
public static void main(String[] args)
{
int[] nums={57,68,59,52};
sort(nums);
}
public static void sort(int[] nums)
{
for (int i = 0; i < nums.length; i++)
{
int min=nums[i];
int n=i;//最小数的索引
for (int j = i+1; j < nums.length; j++)
{
if (nums[j]<min)
{
//找出最小数
min=nums[j];
n=j;
}
}
nums[n]=nums[i];
nums[i]=min;
}
}2、实例
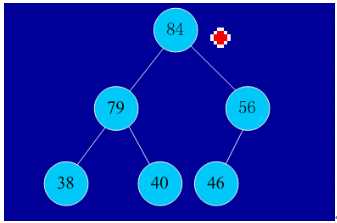
初始序列:46,79,56,38,40,84
建堆:
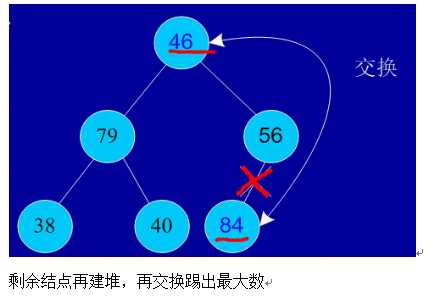
交换,从堆中踢出最大数
public static void main(String[] args)
{
int[] nums={46,79,56,38,40,84};
int len=nums.length;
//循环建堆
for (int i = 0; i < nums.length-1; i++)
{
//建堆
buildMaxHeap(nums,len-1-i);
//交换堆顶和最后一个元素
swap(nums,0,len-1-i);
System.out.println(Arrays.toString(nums));
}
}
/**
* 对nums数组中0到lastIndex建大顶堆
*/
public static void buildMaxHeap(int[] nums,int lastIndex)
{
//从lastIndex处节点(最后一个节点)的父节点开始
for (int i = (lastIndex-1)/2; i >=0; i--)
{
//k保存正在判断的节点
int k=i;
//如果当前K节点的子节点存在
while (k*2+1<=lastIndex)
{
//k节点的左节点的索引
int binggerIndex=2*k+1;
//如果biggerIndex小于lastIndex,即biggerIndex+1代表的k节点的右子节点存在
if (binggerIndex<lastIndex)
{
//如果右子节点的值较大
if (nums[binggerIndex]<nums[binggerIndex+1])
{
binggerIndex++;
}
}
//如果K节点的值小于其较大的子节点的值
if (nums[k]<nums[binggerIndex])
{
//交换他们
swap(nums, k, binggerIndex);
//将biggerIndex赋予K,开始While循环的下一次,重新保证k节点的值大于其左右子节点的值
k=binggerIndex;
}
else
{
break;
}
}
}
}
public static void swap(int[] nums,int i,int j)
{
int temp=nums[i];
nums[i]=nums[j];
nums[j]=temp;
}版权声明:本文为博主原创文章,未经博主允许不得转载。
原文地址:http://blog.csdn.net/zzc8265020/article/details/47834943
