标签:
?? 引言
?? Python 的Web 应用:简单的Web 客户端
?? urlparse 和 urllib 模块
?? 高级的 Web 客户端
?? 网络爬虫/蜘蛛/机器人
?? CGI:帮助 Web 服务器处理客户端数据
?? 创建 CGI 应用程序
?? 在 CGI 中使用Unicode
?? 高级 CGI
?? 创建 Web 服务器
?? 相关模块
20.1 介绍
Web 应用:客户端/服务器计算
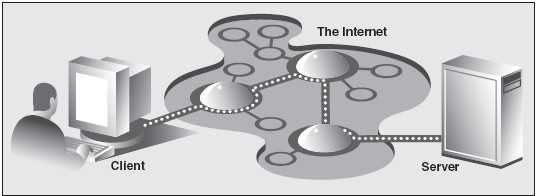
图20-1 因特网上的Web 客户端和Web 服务器。在因特网上客户端向服务器端发送一个请求,然后服务器端响应这个请求并将相应的数据返回给客户端。
HTTP 协议是TCP/IP 协议的上层协议,这意味着HTTP 协议依靠TCP/IP 协议来进行低层的交流工作。
HTTP 协的职责不是路由或者传递消息(TCP/IP 协议处理这些),而是通过发送、接受HTTP 消息来处理客户端的请求。
HTTP 协议属于无状态协议,它不跟踪从一个客户端到另一个客户端的的请求信息,这点和我们 现今使用的客户端/服务器端架构很像。
HTTP 协议由于每个请求缺乏上下文背景,你可以注意到有些URL 会有很长的变量和值作 为请求的一部分,以便提供一些状态信息。
因特网
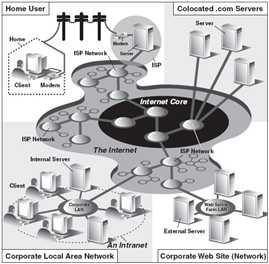
图 20-2 因特网的统览。左侧指明了在哪里你可以找到Web 客户端,而右侧则暗示了Web 服务 器的具体位置。
20.2 使用Python 进行Web 应用:创建一个简单的Web 客户端
浏览器只是Web 客户端的一种。
任何一个通过向服务器端发送请求来获得 数据的应用程序都被认为是“客户端”
浏览器主要用于查看并同其他Web 站点交互。
一个客户端程序可以下载数据,同时也可以存储、操作数据,甚或可以将其传送到另外一个地方或者传给另外一个应用。
统一资源定位符
简单的Web 应用包扩使用被称为URL(统一资源定位器)的Web 地址。
URL 是大型标识符URI(统一资 源标识)的一部分。
Python 支持两种不同的模块,分别以不同的功能和兼容性来处理URL。一种是urlparse,一种 是urllib。
urlparse 模块
urlpasrse 模块提供了操作URL 字符串的基本功能。这些功能包括urlparse(), urlunparse() 和urljoin().
urllib 模块
Urllib 模块提供了在给定的URL 地址下载数据的功能,同时也可以通过字符串的编码、解码来 确保它们是有效URL 字符串的一部分。
urllib.urlopen()
urlopen() 打开一个给定URL 字符串与Web 连接,并返回了文件类的对象。
语法结构如下:
urlopen(urlstr, postQueryData=None)
urlopen()打开urlstr 所指向的URL。
如果没有给定协议或者下载规划,或者文件规划早已传入, urlopen()则会打开一个本地的文件。
对于所有的HTTP 请求,常见的请求类型是“GET”。
GET 向Web 服务器发送的请求字 符串(编码键值或引用,如urlencode()函数的字符串输出[如下])应该是urlstr 的一部分。
POST 请求的字符串(编码的)应该被放到postQueryData 变量中。
urllib.urlretrieve()
语法结构如下:
urlretrieve(urlstr, localfile=None, downloadStatusHook=None)
除了像urlopen()这样从URL 中读取内容,urlretrieve()可以方便地将urlstr 定位到的整个
HTML 文件下载到你本地的硬盘上。你可以将下载后的数据存成一个本地文件或者一个临时文件。如
果该文件已经被复制到本地或者已经是一个本地文件,后续的下载动作将不会发生。
如果可能,downloadStatusHook 这个函数将会在每块数据下载或传输完成后被调用。调用时使
用下边三个参数:目前读入的块数,块的字节数和文件的总字节数。如果你正在用文本的或图表的
视图向用户演示“下载状态”信息,这个函数将会是非常有用的。
urlretrieve()返回一个2-元组,(filename, mime_hdrs).filename 是包含下载数据的本地文
件名,mime_hdrs 是对Web 服务器响应后返回的一系列MIME 文件头。要获得更多的信息,可以看
mimetools 的Message 类。对本地文件来说mime_hdrs 是空的。
urllib.quote() and urllib.quote_plus()
quote*()函数获取URL 数据,并将其编码,从而适用于URL 字符串中。尤其是一些不能被打印的或者不被Web 服务器作为有效URL 接收的特殊字符串必须被转换。
语法结构如下:
quote*(urldata, safe=‘/‘)
逗号,下划线,句号,斜线和字母数字这类符号是不需要转化。其他的则均需要转换。另外,
那些不被允许的字符前边会被加上百分号(%)同时转换成16 进制,例如:“%xx”,“xx”代表这个字母
的ASCII 码的十六进制值。当调用quote*()时,urldata 字符串被转换成了一个可在URL 字符串中
使用的等价值。safe 字符串可以包含一系列的不能被转换的字符。默认的是斜线(/).
quote_plus() 与quote()很像,另外它还可以将空格编码成+号。
urllib.unquote() 和 urllib.unquote_plus()
调用unquote()函数将会把urldata 中所有的URL-编码字母都解码,并返回字符串。
Unquote_plus()函数会将加号转换成空格符。
语法结构如下:
unquote*(urldata)
urllib.urlencode()
urlencode函数接收字典的键-值对,并将其编译成CGI 请求的URL 字 符串的一部分。键值对的格式是“键=值”,以连接符(&)划分。
>>> aDict = {‘name‘: ‘Georgina Garcia‘, ‘hmdir‘: ‘~ggarcia‘ }
>>> urllib.urlencode(aDict)
‘name=Georgina+Garcia&hmdir=%7Eggarcia‘
>>>
安全套接字层支持
在1.6 版中urllib 模块通过安全套接字层(SSL)支持开放的HTTP 连接.socket 模块的核心变化
是增加并实现了SSL。 随后,urllib 和httplib 模块被上传用于支持URL 在“https”连接规划中
的应用。除了那两个模块以外,其他的含有SSL 的模块还有: imaplib, poplib 和 smtplib。
urllib2 模块
如果你打算访问更加复杂的URL 或者想要处理更复杂的情况如基于数字的权限验证,重定位, coockie 等问题,我们建议你使用urllib2 模块。
20.3 高级Web 客户端
Web 浏览器是基本的Web 客户端,主要用来在Web 上查询或者下载文件,而Web 的高级客户端并 不只是从因特网上下载文档。
高级Web 客户端的一个例子就是网络爬虫(aka 蜘蛛和机器人),这些程序可以基于不同目的在 因特网上探索和下载页面,其中包括:
?? 为 Google 和Yahoo 这类大型的搜索引擎建索引
?? 脱机浏览—将文档下载到本地,重新设定超链接,为本地浏览器创建镜像。
?? 下载并保存历史记录或框架
?? Web 页的缓存,节省再次访问Web 站点的下载时间。


1 #!/usr/bin/env python
2
3 # Advanced Web Client: a Web Crawler
4
5 from sys import argv
6 from os import makedirs, unlink, sep
7 from os.path import dirname, exists, isdir, splitext
8 from string import replace, find, lower
9 from htmllib import HTMLParser
10 from urllib import urlretrieve
11 from urlparse import urlparse, urljoin
12 from formatter import DumbWriter, AbstractFormatter
13 from cStringIO import StringIO
14
15 class Retriever(object):# dowload Web pages
16
17 def __init__(self, url):
18 self.url = url
19 self.file = self.filename(url)
20 #self.parser = None
21
22 def filename(self, url, deffile=‘index.htm‘):
23 parsedurl = urlparse(url, ‘http:‘, 0) ## parse path
24 path = parsedurl[1] + parsedurl[2]
25 ext = splitext(parsedurl[2])
26 if ext[1] == ‘‘: # no file, use default
27 if path[-1] == ‘/‘:
28 path += deffile
29 else:
30 path += ‘/‘ + deffile
31 ldir = dirname(path) # local directory
32 if sep != ‘/‘: # os-indep. path separator
33 ldir = replace(ldir, ‘/‘, sep)
34 if not isdir(ldir):# create archive dir if nec.
35 if exists(ldir): unlink(ldir)
36 try:
37 makedirs(ldir)
38 except WindowsError, e:
39 print (ldir, url, path)
40 raise e
41 return path
42
43 def download(self): # download Web page
44 try:
45 retval = urlretrieve(self.url, self.file)
46 except IOError:
47 retval = (‘*** ERROR: invalid URL "%s"‘ % 48 self.url,)
49 return retval
50
51 def parseAndGetLinks(self): # parse HTML, save links
52 self.parser = HTMLParser(AbstractFormatter( 53 DumbWriter(StringIO())))
54 self.parser.feed(open(self.file).read())
55 self.parser.close()
56 return self.parser.anchorlist
57
58 class Crawler(object): # manage entire crawling process
59 count = 0 # static downloaded page counter
60
61 def __init__(self, url):
62 self.q = [url]
63 self.seen = list()
64 self.dom = urlparse(url)[1]
65
66 def getPage(self, url):
67 r = Retriever(url)
68 retval = r.download()
69 if retval[0] == ‘*‘: # error situation, do not parse
70 print retval, ‘... skipping parse‘
71 return
72 Crawler.count += 1
73 print ‘\n(‘, Crawler.count, ‘)‘
74 print ‘URL:‘, url
75 print ‘FILE:‘, retval[0]
76 self.seen.append(url)
77
78 links = r.parseAndGetLinks() # get and process links
79 for eachLink in links:
80 if eachLink[:4] != ‘http‘ and 81 find(eachLink, ‘://‘) == -1:
82 eachLink = urljoin(url, eachLink)
83 print ‘*‘, eachLink,
84
85 if find(lower(eachLink), ‘mailto:‘) != -1:
86 print ‘... discarded, mailto link‘
87 continue
88
89 if find(lower(eachLink), ‘javascript:‘) != -1:
90 print ‘... discarded, javascript link "%s"‘ % eachLink
91 continue
92
93 if eachLink not in self.seen:
94 if find(eachLink, self.dom) == -1:
95 print ‘... discarded, not in domain‘
96 else:
97 if eachLink not in self.q:
98 self.q.append(eachLink)
99 print ‘... new, added to Q‘
100 else:
101 print ‘... discarded, already in Q‘
102 else:
103 print ‘... discarded, already processed‘
104 def go(self): # process links in queue
105 while self.q:
106 url = self.q.pop()
107 self.getPage(url)
108
109 def main():
110 if len(argv) > 1:
111 url = argv[1]
112 else:
113 try:
114 url = raw_input(‘Enter starting URL:‘)
115 except (KeyboardInterrupt, EOFError):
116 url = ‘‘
117 if not url: return
118 robot = Crawler(url)
119 robot.go()
120
121 if __name__ == ‘__main__‘:
122 main()
crawl.py
20.4 CGI:帮助Web 服务器处理客户端数据
CGI 介绍
Web 开发的最初目的是在全球范围内对文档进行存储和归档(大多是教学和科研目的的)。这些 零碎的信息通常产生于静态的文本或者HTML.
服务器接到表单反馈,与外部应用程序 交互,收到并返回新生成的HTML 页面都发生在一个叫做Web 服务器CGI(Common Gateway Interface) 的接口上.
创建HTML 的CGI 应用程序通常是用高级编程语言来实现的,可以接受、处理数据,向服务器端 返回HTML 页面。目前使用的编程语言有Perl, PHP, C/C++,或者Python。
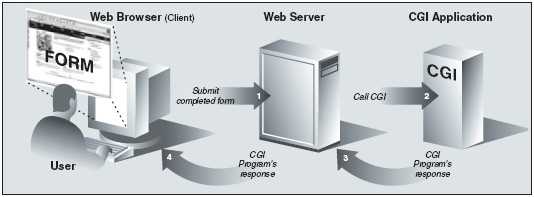
图20-3 CGI 工作概要图。CGI 代表了在一个Web 服务器和能够处理用户表单、生成并返回动态 HTML 页的应用程序间的交互。
典型的Web 应用产品已经不再使用CGI
由于它词义的局限性和允许Web 服务器处理大量模拟客户端数据能力的局限性,CGI 几乎绝迹。
Web 服务的关键使命依赖于遵循像C/C++这样语言的规范。如今的Web 服务器典型的部件有Aphache
和集成的数据库部件(MySQL 或者PostgreSQL),Java(Tomcat),PHP 和各种Perl 模块,Python 模
块,以及SSL/security。然而,如果你工作在私人小型的或者小组织的Web 网站上的话就没有必要
使用这种强大而复杂的Web 服务器, CGI 是一个适用于小型Web 网站开发的工具。
Web 应用程序开发框架和内容管理系统,仍旧遵循这CGI 最初提供的模式,可以允许用户输入,根据输入执行拷贝,并提供了一个有效的HTML 做为最终的客户端输出。
CGI 应用程序
CGI 应用程序和典型的应用程序有些不同。主要的区别在于输入、输出以及用户和计算机交互方 面。
当一个CGI 脚本开始执行时,它需要检索用户-支持表单,但这些数据必须要从Web 的客户端才可以
获得,而不是从服务器或者硬盘上获得。
这些不同于标准输出的输出将会返回到连接的Web 客户端,而不是返回到屏幕、CUI 窗口或者硬
盘上。这些返回来的数据必须是具有一系列有效头文件的HTML。否则,如果浏览器是Web 的客户端,
由于浏览器只能识别有效的HTTP 数据(也就是MIME 都问价和HTML),那么返回的也只能是个错误消
息(具体的就是因特网服务器错误)。
最后,可能和你想象的一样,用户不能与脚本进行交互。所有的交互都将发生在Web 客户端(用
户的行为),Web 服务器端和CGI 应用程序间。
cgi 模块
在cgi 模块中有个主要类:FieldStorage 类,它完成了所有的工作。在Python CGI 脚本开始时
这个类将会被实例化,它会从Web 客户端(具有Web 服务器)读出有关的用户信息。一旦这个对象
被实例化,它将会包含一个类似字典的对象,具有一系列的键-值对,键就是通过表单传入的表单条
目的名字,而值则包含相应的数据。
这些值本身可以是以下三种对象之一。它们既可以是FieldStorage 对象(实例)也可以是另一
个类似的名为MiniFieldStorage 类的实例,后者用在没有文件上传或mulitple-part 格式数据的情
况。MiniFieldStorage 实例只包含名字和数据的键-值对。最后,它们还可以是这些对象的列表。这
发生在表单中的某个域有多个输入值的情况下。
对于简单的Web 表单,你将会经常发现所有的MiniFieldStorage 实例。
20.5 建立CGI 应用程序
建立Web 服务器
为了可以用Python 进行CGI 开发,你首先需要安装一个Web 服务器,将其配置成可以处理Python CGI 请求的模式,然后让你的Web 服务器访问CGI 脚本。
如果你需要一个真正的Web 服务器,可以下载并安装Aphache。Aphache 的插件或模块可以处理 Python CGI,但这在我们的例子里并不是必要的。
为了学习的目的或者是建立小型的Web 站点,使用Python 自身带的Web 服务器就已经足够了。
如果你只是想建立一个基于Web 的服务器,你可以直接执行下边的Python 语句。
$ python -m CGIHTTPServer
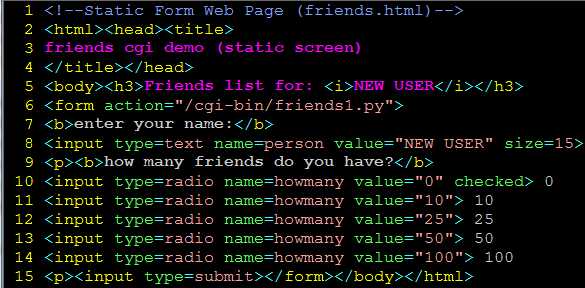
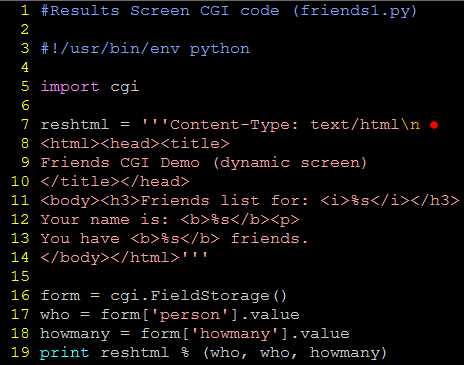
建立表单页
生成结果页
核心提示:HTML 头文件是从HTML 中分离出来的。
有一点需要向CGI 初学者指明的是,在向CGI 脚本返回结果时,须先返回一个适当的HTTP 头文
件后才会返回结果HTML 页面。为了区分这些头文件和结果HTML 页面,需要在friends1.py
的第五行中插入几个换行符。
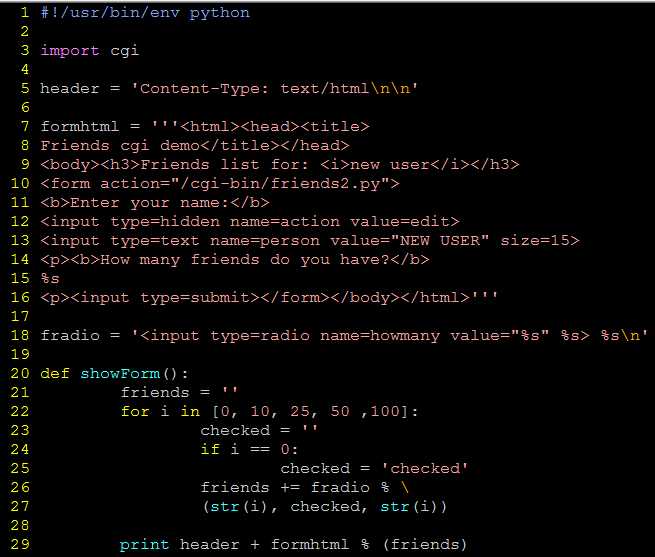
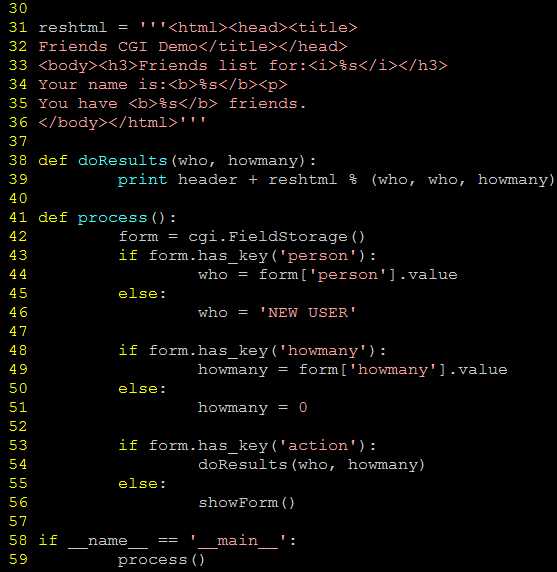
生成表单和结果页面
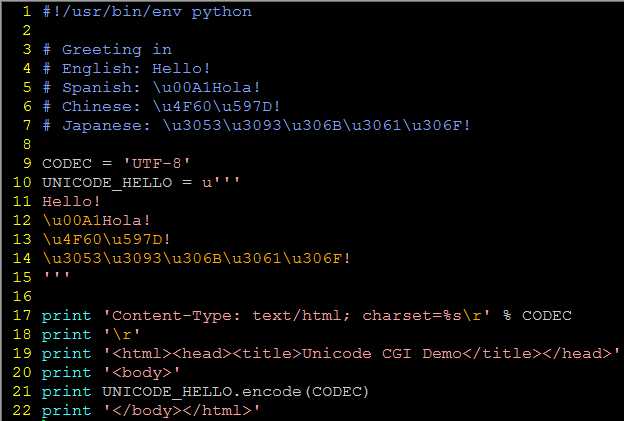
20.6 在CGI 中使用Unicode 编码
Mulitipart 表单提交和文件的上传
目前, CGI 特别指出只允许两种表单编码,“ application/x-www-form-urlencoded ” 和 “multipart/form-dat”。
由于前者是默认的,就没有必要像下边那样在FORM 标签里声明编码方式。
<FORM enctype="application/x-www-form-urlencoded" ...>
但是对于multipart 表单,你需要像这样明确给出编码:
<FORM enctype="multipart/form-data" ...>
在表单提交时你可以使用任一种编码,但在目前上传的文件仅能表现为multipart 编码。
不论你使用的是默认编码还是multipart 编码,cgi 模块都会以同样的方式来处理它们,在表单 提交时提供键和相应的值,你还可以像以前那样通过FieldStorage 实例来访问数据。
Multipart 编码是由网景在早期开发的,但是已经被微软(开始于IE4 版)和其他的浏览器采用。
多值字段
除了上传文件,我们将会展示如何处理具有多值的字段。最常见的情况就是你有一系列的复选
框允许用户有多个选择。每个复选框都会标上相同的字段名,但是为了区分它们,会有不同的值与
特定的复选框关联。
正如你所知道的,在表单提交时,数据从用户端以键-值对形式发送到服务器端。当提交不止一
个复选框时,就会有多个值对应同一个键。在这种情况下,cgi 模块将会建立一个这类实例的列表,
你可以遍历获得所有的值,而不是为你的数据指定一个MiniFielStorage 实例。
cookie
在客户端获得请 求文件前,Web 服务器向客户端发送“SetCookie”头文件要求客户端存储cookie。
cookie 以分号(;)分隔,每个键-值对中间都 由等号(=)分开。
和multipart 编码一样,cookie 同样起源于网景,他们实现了cookie 并制定出第一个规范并沿 用至今。
使用高级CGI
//TODO
20.8 Web(HTTP)服务器
最流行的一些Web 客户 端: Chrome, Firefox, Mozilla, IE, Opera, Netscape, AOL, Safari, Camino, Epiphany, Galeon 和Lynx
最常用的Web 服务器: Apache,Netscape IIS, thttpd, Zeus,和Zope
用Python 建立Web 服务器
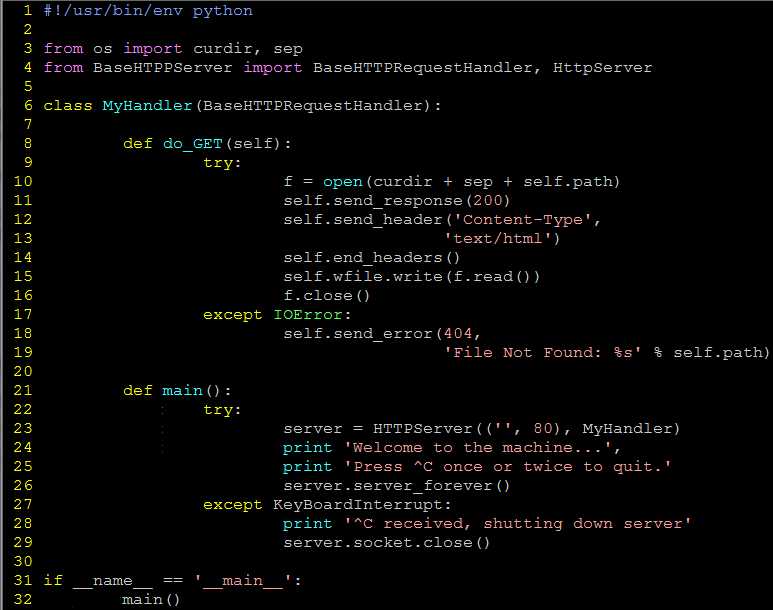
要建立一个Web 服务,一个基本的服务器和一个“处理器” 必备的。
基础的(Web)服务器
基础的(Web)服务器是一个必备的模具。它的角色是在客户端和服务器端完成必要HTTP 交互。
在BaseHTTPServer 模块中你可以找到一个名叫HTTPServer 的服务器基本类。
处理器
处理器是一些处理主要“Web 服务”的简单软件。
它们处理客户端的请求,并返回适当的文件, 静态的文本或者由CGI 生成的动态文件。
处理器的复杂性决定了你的Web 服务器的复杂程度。
Python 标准库提供了三种不同的处理器。
BaseHTTPResquestHandler
最基本,最普通的是 vanilla 处理器,被命名 BaseHTTPResquestHandler,这个可以在基本
Web 服务器的BaseHTTPServer 模块中找到。除了获得客户端的请求外,不再执行其他的处理工作,
因此你必须自己完成它们,这样就导致了出现了myhttpd.py 服务的出现。
SimpleHTTPRequestHandler
用于SimpleHTTPServer 模块中的SimpleHTTPRequestHandler , 建立在 BaseHTTPResquestHandler 基础上,直接执行标准的GET 和HEAD 请求。
CGIHTTPRequestHandler
最后,我们来看下用于CGIHTTPServer 模块中的CGIHTTPRequestHandler 处理器,它可以获取
SimpleHTTPRequestHandler 并为POST 请求提供支持。它可以调用CGI 脚本完成请求处理过程,也可
以将生成的HTML 脚本返回给客户端。
20.9 相关模块
20 Web 编程 - 《Python 核心编程》
标签:
原文地址:http://www.cnblogs.com/BugQiang/p/4743110.html