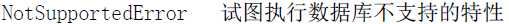标签:
?? 介绍
?? 数据库 和 Python RDBMSs, ORMs, and Python
?? Python 数据库应用程序程序员接口(DB-API)
?? 关系数据库 (RDBMSs)
?? 对象-关系管理器(ORMs)
?? 关系模块
21.1 介绍
持久存储
在任何的应用程序中,都需要持久存储。
一般说来,有三种基本的存储机制:
文件、关系型数 据库或其它的一些变种,例如现有系统的API,ORM、文件管理器、电子表格、配置文件等等。
基本的数据库操作和SQL 语言
底层存储
数据库的底层存储通常使用文件系统, 它可以是普通操作系统文件、专用操作系统文件,甚至有可能是磁盘分区。
用户界面
大部分的数据库系统会提供一个命令行工具来执行SQL 命令和查询,当然也有一些使用图形界面的漂漂亮亮的客户端程序来干同样的事。
数据库
关系型数据库管理系统通常通常都支持多个数据库,例如销售库、市场库、客户支持库等等.
MySQL 是一种基于服务器的关系数据库管理系统 (只要服务器在运行, 它就一直在等待运行指令)
SQLite 和Gadfly 则是另一种轻量型的基于文件的关系数据库(它们没有服务器)。
组件
你可以将数据库存储想像为一个表格, 每行数据都有一个或多个字段对应着数据库中的列. 每
个表每个列及其数据类型的集合构成数据库结构的定义. 数据库能够被创建, 也可以被删除. 表也
一样. 往数据库里增加一条记录称为插入(inserting) 一条记录, 修改库中一条已有的记录则称
为 更新(updating), 删除表中已经有的数据行称为删除(deleting). 这些操作通常作为数据库操
作命令来提交. 从一个数据库中请求符合条件的数据称为查询(querying). 当你对一个数据库进行
查询时, 你可以一步取回所有符合条件的数据, 也可以循环逐条取出每一行. 有些数据库使用游标
的概念来表示 SQL 命令, 查询, 取回结果集等等.
SQL
数据库命令和查询操作需要通过SQL 语句来执行.
不是所有的数据库都使用SQL, 但所有主流的关系型数据库都使用SQL.
被广为接受的书写SQL 的基本风格是关键字大写.
绝大多数命令行程序要求用一个分号来结束一条SQL 语句.
创建数据库
CREATE DATABASE test; -- 创建一个名为“test”的数据库
GRANT ALL ON test.* to user(s); -- 将该数据库的权限赋给具体的用户(或者全部 用户),以便它们可以执行下面的数据库操作
选择要使用的数据库
USE test;
删除数据库
DROP DATABASE test;
创建表
CREATE TABLE users (login VARCHAR(8), uid INT, prid INT);
删除表
DROP TABLE users;
插入行
INSERT INTO users VALUES(‘leanna‘, 311, 1);
更新行
UPDATE users SET prid=4 WHERE prid=2;
UPDATE users SET prid=1 WHERE uid=311;
删除行
DELETE FROM users WHERE prid=%d;
DELETE FROM users;
数据库 和 Python
Python 能够直接通过数据库接口, 也可以通过 ORM (NoSql) 来访问关系数据库.
数据库原理: 并发能力, 视图, 原子性, 数据完整性, 数据可恢复性, 还有左连接, 触发器, 查询优化, 事务支持, 及存储过程等
从python 中访问数据库需要接口程序.
接口程序是一个 python 模块, 它提供数据库客户端库(通常是C 语言写成的)的接口供你访问.
所有 Python 接口程序都一定程度上遵守 Python DB-API 规范.
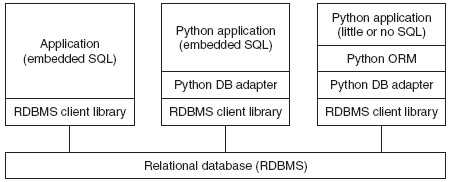
图 21-1 数据库和应用程序之间的多层通讯.
第一个盒子一般是 C/C++ 程序, 你的程序通过 DB-API 兼容接口程序访问数据库.ORM 通过程序处理数据库细节来简化数据库开发.
21.2 Python 数据库应用程序
DB-API 是一个规范. 它定义了一系列必须的对象和数据库存取方式, 以便为各种各样的底层数 据库系统和多种多样的数据库接口程序提供一致的访问接口.
模块属性
DB-API 规范里的以下特性和属性必须提供.
数据属性
apilevel
apilevel 这个字符串(不是浮点数)表示这个 DB-API 模块所兼容的DB-API 最高版本号. 如"1.0", "2.0", 如果未定义, 则默认是 "1.0";
threadsafety
threadsafety 这是一个整数, 取值范围如下
?? 0:不支持线程安全, 多个线程不能共享此模块
?? 1:初级线程安全支持: 线程可以共享模块, 但不能共享连接
?? 2:中级线程安全支持 线程可以共享模块和连接, 但不能共享游标
?? 3:完全线程安全支持 线程可以共享模块, 连接及游标.
如果一个资源被共享, 就必需使用自旋锁或者是信号量这样的同步原语对其进行原子目标锁定。
对这个目标来说, 磁盘文件和全局变量都不可靠, 并且有可能妨碍mutex(互斥量)的操作.
paramstyle
DB-API 支持多种方式的SQL 参数风格. 这个参数是一个字符串, 表明SQL 语句中字符串替代的 方式.
函数属性
connect 方法
connect 方法生成一个connect 对象, 我们通过这个对象来访问数据库. 符合标准的模块都 会实现 connect 方法.
数据库连接参数可以以一个 DSN 字符串的形式提供, 也可以以多个位置相关参数的形式提供 (如果你明确知道参数的顺序的话), 也可以以关键字参数的形式提供.
注意不是所有的接口程序都是严格按照规范实现的. MySQLdb 就使用了 db 参 数而不是规范推荐的 database 参数来表示要访问的数据库.
异常
兼容标准的模块也应该提供这些异常类.


连接对象
要与数据库进行通信, 必须先和数据库建立连接. 连接对象处理命令如何送往服务器, 以及如 何从服务器接收数据等基础功能.
连接成功(或一个连接池)后你就能够向数据库服务器发送请求, 得到响应.
方法
表21.5 连接对象没有必须定义的数据属性, 但是它至少应该定义这些方法.
一旦执行了 close() 方法, 再试图使用连接对象的方法将会导致异常.
对不支持事务的数据库或者虽然支持事务, 但设置了自动提交(auto-commit)的数据库系统来
说, commit()方法什么也不做. 如果你确实需要, 可以实现一个自定义方法来关闭自动提交行为.
由于 DB-API 要求必须实现此方法, 对那些没有事务概念的数据库来说, 这个方法只需要有一条
pass 语句就可以了.
类似 commit(), rollback() 方法仅对支持事务的数据库有意义. 执行完rollback(), 数据库
将恢复到提交事务前的状态. 根据 PEP249, 在提交commit()之前关闭数据库连接将会自动调用
rollback()方法.
对不支持游标的数据库来说, cursor()方法仍然会返回一个尽量模仿游标对象的对象. 这些是
最低要求. 特定数据库接口程序的开发者可以任意为他们的接口程序添加额外的属性, 只要他们愿 意.
DB-API 规范建议但不强制接口程序的开发者为所有数据库接口模块编写异常类. 如果没有提
供异常类, 则假定该连接对象会引发一致的模块级异常. 一旦你完成了数据库连接, 并且关闭了
游标对象, 你应该执行 commit() 提交你的操作, 然后关闭这个连接.
游标对象
一个游标允许用户 执行数据库命令和得到查询结果.
一个 Python DB-API 游标对象总是扮演游标的角色, 无论数据库是否真正支持游标.
数据库接口程序必须实现游标对象,才能保证无论使用何种后端数据库你的代码都不需要做任何改变.
游标对象最重要的属性是 execute*() 和 fetch*() 方法. 所有对数据库服务器的请求都由它
们来完成.对fetchmany()方法来说, 设置一个合理的arraysize 属性会很有用. 当然, 在不需要时
关掉游标对象也是个好主意. 如果你的数据库支持存储过程, 你就可以使用callproc() 方法.
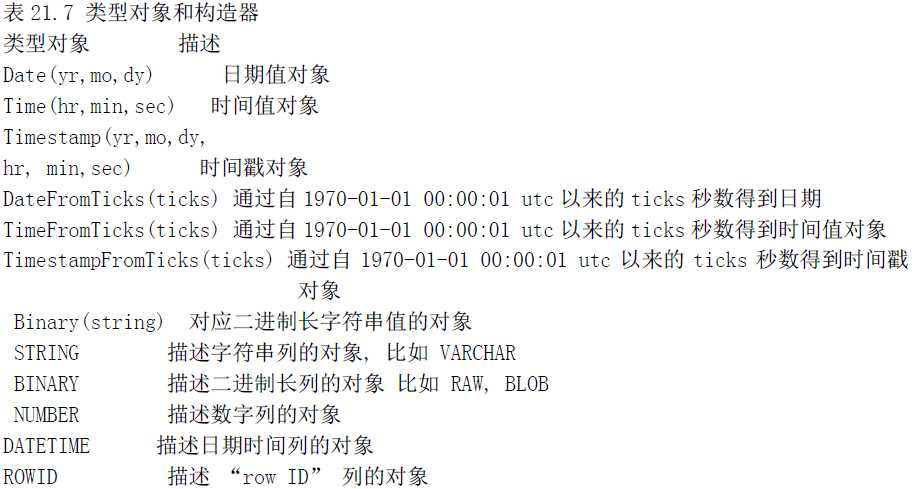
类型对象和构造器
通常两个不同系统的接口要求的参数类型是不一致的,譬如python 调用c 函数时Python 对象和 C 类型之间就需要数据格式的转换,
对于 Python DB-API 的开发者来说, 你传递给数据库的参数是字符串形式的, 但数据库会根 据需要将它转换为多种不同的形式. 以确保每次查询能被正确执行.
一个 Python 字符串可能被转换为一个 VARCHAR, 或一个TEXT, 或一个BLOB, 或一
个原生 BINARY 对象, 或一个DATE 或TIME 对象. 一个字符串到底会被转换成什么类型? 必须小心
的尽可能以数据库期望的数据类型来提供输入, 因此另一个DB-API 的需求是创建一个构造器以生成
特殊的对象, 以便能够方便的将Python 对象转换为合适的数据库对象.
SQL 的 NULL 值被映射为 Pyhton 的 NULL 对象, 也就是 None.
关系数据库
http://python.org/topics/database/modules.html
数据库和Python:接口程序
对每一种支持的数据库, 都有一个或多个Python 接口程序允许你连接到目标数据库系统.
你挑选接口程序的标准可以是: 性能如何? 文档或 WEB 站点的质量如何? 是否有一个活跃的用户或开发社区? 接口程序的质量和稳定性如何?
绝大多数接口程序只提供基本的连接功能, 高级应用代码如 线程和线程管理以及数据库连接池的管理等等, 需要你自己来完成.
使用数据库接口程序举例
SQLite
对非常简单的应用来说, 使用文件进行持久存储通常就足够了. 但对于绝大多数数据驱动的应用程序必须使用全功能的关系数据库.
SQLite 介于二者之间, 它定位于中小规模的应用.它是相当轻量级的全功能关系型数据库, 速度很快, 几乎不用配置, 并且不需要服务器.
在标准库中有这么sqlite3一个模块, 就能方便用户使用Python 和 SQLite 进行软件开发, 等到软
件产品正式上市发布时, 只要需要, 就能够很容易的将产品使用的数据库后端变更为一个全功能的,
更强大的类似 MySQL, PostgreSQL, Oracle 或 SQL Server 那样的数据库.


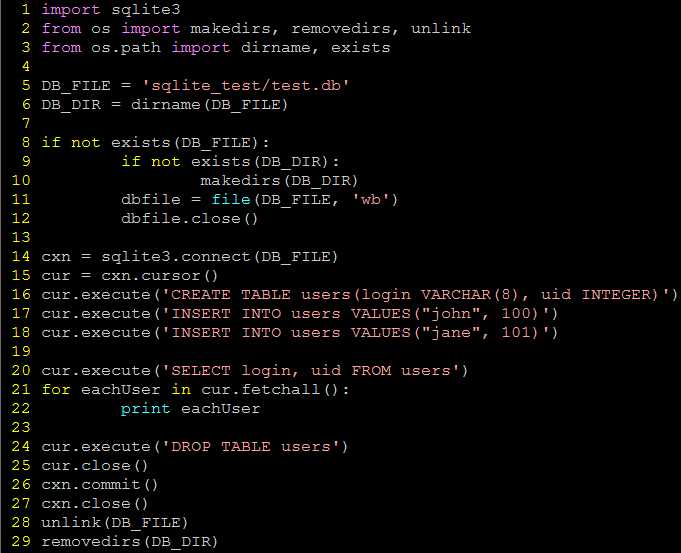
1 import sqlite3
2 from os import makedirs, removedirs, unlink
3 from os.path import dirname, exists
4
5 DB_FILE = ‘sqlite_test/test.db‘
6 DB_DIR = dirname(DB_FILE)
7
8 if not exists(DB_FILE):
9 if not exists(DB_DIR):
10 makedirs(DB_DIR)
11 dbfile = file(DB_FILE, ‘wb‘)
12 dbfile.close()
13
14 cxn = sqlite3.connect(DB_FILE)
15 cur = cxn.cursor()
16 cur.execute(‘CREATE TABLE users(login VARCHAR(8), uid INTEGER)‘)
17 cur.execute(‘INSERT INTO users VALUES("john", 100)‘)
18 cur.execute(‘INSERT INTO users VALUES("jane", 101)‘)
19
20 cur.execute(‘SELECT login, uid FROM users‘)
21 for eachUser in cur.fetchall():
22 print eachUser
23
24 cur.execute(‘DROP TABLE users‘)
25 cur.close()
26 cxn.commit()
27 cxn.close()
28 unlink(DB_FILE)
29 removedirs(DB_DIR)
sqlite3test.py
1 #!/usr/bin/env python
2
3 import os
4 from random import randrange as rrange
5
6 COLSIZ = 10
7 RDBMSs = {‘s‘: ‘sqlite‘, ‘m‘: ‘mysql‘, ‘g‘:‘gadfly‘}
8 DB_EXC = None
9
10 def setup():
11 return RDBMSs[raw_input(‘‘‘
12 Choose a database system:
13
14 (M)ySQL
15 (G)adfly
16 (S)qlite
17
18 Enter choice:‘‘‘).strip().lower()[0]]
19
20 def connect(db, dbName):
21 global DB_EXC
22 dbDir = ‘%s_%s‘ % (db, dbName)
23
24 if db == ‘sqlite‘:
25 try:
26 import sqlite3
27 except ImportError, e:
28 try:
29 from pysqlite2 import dbapi2 as sqlite3
30 except ImportError, e:
31 return None
32
33 DB_EXC = sqlite3
34 if not os.path.isdir(dbDir):
35 os.mkdir(dbDir)
36 cxn = sqlite3.connect(os.path.join(dbDir, dbName))
37
38 elif db == ‘mysql‘:
39 try:
40 import MySQLdb
41 import _mysql_exceptions as DB_EXC
42 except ImportError, e:
43 return None
44
45 try:
46 cxn = MySQLDb.connect(db=dbName)
47 except _mysql_exceptions.OperationalError, e:
48 cxn = MySQLdb.connect(user=‘root‘)
49 try:
50 cxn.query(‘DROP DATABASE %s‘ % dbName)
51 except DB_EXC.OperationalError, e:
52 pass
53 cxn.query(‘CREATE DATABASE %s‘ % dbName)
54 cxn.query("GRANT ALL ON %s.* to ‘‘@‘localhost‘" % dbName)
55 cxn.commit()
56 cxn.close()
57 cxn = MySQLdb.connect(db=dbName)
58
59 elif db == ‘gadfly‘:
60 try:
61 from gadfly import gadfly
62 DB_EXC = gadfly
63 except ImportError, e:
64 return None
65
66 try:
67 cxn = gadfly(dbName, dbDir)
68 except IOError, e:
69 cxn = gadfly()
70 if not os.path.isdir(dbDir):
71 os.mkdir(dbDir)
72 cxn.startup(dbName, dbDir)
73 else:
74 return None
75 return cxn
76
77 def create(cur):
78 try:
79 cur.execute(‘‘‘
80 CREATE TABLE users (
81 login VARCHAR(8),
82 uid INTEGER,
83 prid INTEGER)
84 ‘‘‘)
85 except DB_EXC.OperationalError, e:
86 drop(cur)
87 create(cur)
88
89 drop = lambda cur: cur.execute(‘DROP TABLE users‘)
90
91 NAMES = (
92 (‘aaron‘, 8312), (‘angela‘, 7603), (‘dave‘, 7306),
93 (‘davina‘,7902), (‘elliot‘, 7911), (‘ernie‘, 7410),
94 (‘jess‘, 7912), (‘jim‘, 7512), (‘larry‘, 7311),
95 (‘leslie‘, 7808), (‘melissa‘, 8602), (‘pat‘, 7711),
96 (‘serena‘, 7003), (‘stan‘, 7607), (‘faye‘, 6812),
97 (‘amy‘, 7209),
98 )
99
100 def randName():
101 pick = list(NAMES)
102 while len(pick) > 0:
103 yield pick.pop(rrange(len(pick)))
104
105 def insert(cur, db):
106 if db == ‘sqlite‘:
107 cur.executemany("INSERT INTO users VALUES(?, ?, ?)",
108 [(who, uid, rrange(1, 5)) for who, uid in randName()])
109 elif db == ‘gadfly‘:
110 for who, uid in randName:
111 cur.execute("INSERT INTO users VALUES(?, ?, ?)",
112 (who, uid, rrange(1,5)))
113 elif db == ‘mysql‘:
114 cur.executemay("INSERT INTO users VALUES(%s, %s, %s)",
115 [(who, uid, rrange(1,5)) for who, uid, in randName()])
116
117 getRC = lambda cur: cur.rowcount if hasattr(cur, ‘rowcount‘) else -1
118
119 def update(cur):
120 fr = rrange(1,5)
121 to = rrange(1,5)
122 cur.execute(
123 "UPDATE users SET prid=%d WHERE prid=%d" % (to, fr))
124 return fr, to, getRC(cur)
125
126 def delete(cur):
127 rm = rrange(1,5)
128 cur.execute(‘DELETE FROM users WHERE prid=%d‘ % rm)
129 return rm, getRC(cur)
130
131 def dbDump(cur):
132 cur.execute(‘SELECT login, uid, prid FROM users‘)
133 print ‘\n%s%s%s‘ % (‘LOGIN‘.ljust(COLSIZ),
134 ‘USERID‘.ljust(COLSIZ), ‘PROJ#‘.ljust(COLSIZ))
135 for data in cur.fetchall():
136 print ‘%s%s%s‘ % tuple([str(s).title().ljust(COLSIZ)137 for s in data])
138 def main():
139 db = setup()
140 print ‘*** Connecting to %r database‘ % db
141 cxn = connect(db, ‘test‘)
142
143 if not cxn:
144 print ‘ERROR: %r not supported, exiting‘ % db
145 return
146 cur = cxn.cursor()
147
148 print ‘\n*** Creating users table‘
149 create(cur)
150
151 print ‘\n*** Inserting names into table‘
152 insert(cur, db)
153 dbDump(cur)
154
155 print ‘\n*** Randomly moving folks‘,
156 fr, to, num = update(cur)
157 print ‘from on group (%d) to another (%d)‘ % (fr, to)
158 print ‘\t(%d users moved)‘ % num
159 dbDump(cur)
160
161 print ‘\n*** Randomly choosing group.‘,
162 rm, num = delete(cur)
163 print ‘(%d) to delete‘ % rm
164 print ‘\t(%d users removed)‘ % num
165 dbDump(cur)
166
167 print ‘\n*** Drop users table‘
168 drop(cur)
169 cur.close()
170 cxn.commit()
171 cxn.close()
172
173 if __name__ == ‘__main__‘:
174 main()
shuffle_db.py
21.3 对象-关系管理器(ORMs)
考虑对象,而不是SQL
ORM系统的创建者将绝大多数纯 SQL 层功能抽象为Python 对象, 这样你就无需编写SQL 也能够 完成同样的任务.
如果你在某些情况下实在需要SQL, 有些系统也允许你拥有这种灵活性.
绝大多数情况下, 你应该尽量避免进行直接的SQL 查询.
数据库的表被转换为 Python 类, 它具有列属性和操作数据库的方法.
Python 和 ORM
最知名的 Python ORM 模块是 SQLAlchemy 和 SQLObject
其它的 Python ORM 包括 PyDO/PyDO2, PDO, Dejavu, Durus, QLime 和 ForgetSQL.
一些大型 的Web 开发工具/框架也可以有自己的 ORM 组件, 如 WebWare MiddleKit和 Django的数据库 API.
知名的 ORM 并不意味着就是最适合你的应用程序的ORM.
与SQLObject 相比, SQLAlchemy 的接口在某种程度上更接近 SQL,
SQLAlchemy 的抽象层确实相当完美, 而且在你必须使用SQL 完成某些功能时, 它提供了足够的灵活性.
这两个ORM 模块在设置及存取数据时使用的术语非常相似, 代码长度也很接近,
委托处理 就是指一个方法调用不存在时, 转交给另一个拥有此方法的对象去处理.
21.4 相关模块
21 数据库编程 - 《Python 核心编程》
标签:
原文地址:http://www.cnblogs.com/BugQiang/p/4743111.html