标签:
文本主要内容:
一、链表结构:
概念:
链式存储结构是基于指针实现的。我们把一个数据元素和一个指针称为结点。
数据域:存数数据元素信息的域。
指针域:存储直接后继位置的域。
链式存储结构是用指针把相互直接关联的结点(即直接前驱结点或直接后继结点)链接起来。链式存储结构的线性表称为链表。
链表类型:
根据链表的构造方式的不同可以分为:
二、单链表:
概念:
链表的每个结点中只包含一个指针域,叫做单链表(即构成链表的每个结点只有一个指向直接后继结点的指针)
单链表中每个结点的结构:

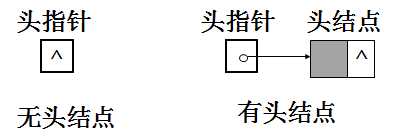
1、头指针和头结点:
单链表有带头结点结构和不带头结点结构两种。
“链表中第一个结点的存储位置叫做头指针”,如果链表有头结点,那么头指针就是指向头结点的指针。
头指针所指的不存放数据元素的第一个结点称作头结点(头结点指向首元结点)。头结点的数据域一般不放数据(当然有些情况下也可存放链表的长度、用做监视哨等)
存放第一个数据元素的结点称作第一个数据元素结点,或称首元结点。
如下图所示:

不带头结点的单链表如下:

带头结点的单链表如下图:

关于头指针和头结点的概念区分,可以参考如下博客:
http://blog.csdn.net/hitwhylz/article/details/12305021
2、不带头结点的单链表的插入操作:

上图中,是不带头结点的单链表的插入操作。如果我们在非第一个结点前进行插入操作,只需要a(i-1)的指针域指向s,然后将s的指针域指向a(i)就行了;如果我们在第一个结点前进行插入操作,头指针head就要等于新插入结点s,这和在非第一个数据元素结点前插入结点时的情况不同。另外,还有一些不同情况需要考虑。
因此,算法对这两种情况就要分别设计实现方法。
3、带头结点的单链表的插入操作:(操作统一,推荐)

上图中,如果采用带头结点的单链表结构,算法实现时,p指向头结点,改变的是p指针的next指针的值(改变头结点的指针域),而头指针head的值不变。
因此,算法实现方法比较简单,其操作与对其它结点的操作统一。
问题1:头结点的好处:
头结点即在链表的首元结点之前附设的一个结点,该结点的数据域中不存储线性表的数据元素,其作用是为了对链表进行操作时,可以对空表、非空表的情况以及对首元结点进行统一处理,编程更方便。
问题2:如何表示空表:
无头结点时,当头指针的值为空时表示空表;
有头结点时,当头结点的指针域为空时表示空表。
如下图所示:
问题3:头结点的数据域内装的是什么?
头结点的数据域可以为空,也可存放线性表长度等附加信息,但此结点不能计入链表长度值。
三、单项链表的代码实现:
1、结点类:
单链表是由一个一个结点组成的,因此,要设计单链表类,必须先设计结点类。结点类的成员变量有两个:一个是数据元素,另一个是表示下一个结点的对象引用(即指针)。
步骤如下:
(1)头结点的构造(设置指针域即可)
(2)非头结点的构造
(3)获得当前结点的指针域
(4)获得当前结点数据域的值
(5)设置当前结点的指针域
(6)设置当前结点数据域的值
注:类似于get和set方法,成员变量是数据域和指针域。
代码实现:
(1)List.java:(链表本身也是线性表,只不过物理存储上不连续)
//线性表接口 public interface List { //获得线性表长度 public int size(); //判断线性表是否为空 public boolean isEmpty(); //插入元素 public void insert(int index, Object obj) throws Exception; //删除元素 public void delete(int index) throws Exception; //获取指定位置的元素 public Object get(int index) throws Exception; }
(2)Node.java:结点类
//结点类 public class Node { Object element; //数据域 Node next; //指针域 //头结点的构造方法 public Node(Node nextval) { this.next = nextval; } //非头结点的构造方法 public Node(Object obj, Node nextval) { this.element = obj; this.next = nextval; } //获得当前结点的指针域 public Node getNext() { return this.next; } //获得当前结点数据域的值 public Object getElement() { return this.element; } //设置当前结点的指针域 public void setNext(Node nextval) { this.next = nextval; } //设置当前结点数据域的值 public void setElement(Object obj) { this.element = obj; } public String toString() { return this.element.toString(); } }
2、单链表类:
单链表类的成员变量至少要有两个:一个是头指针,另一个是单链表中的数据元素个数。但是,如果再增加一个表示单链表当前结点位置的成员变量,则有些成员函数的设计将更加方便。
代码实现:
(3)LinkList.java:单向链表类(核心代码)
1 //单向链表类 2 public class LinkList implements List { 3 4 Node head; //头指针 5 Node current;//当前结点对象 6 int size;//结点个数 7 8 //初始化一个空链表 9 public LinkList() 10 { 11 //初始化头结点,让头指针指向头结点。并且让当前结点对象等于头结点。 12 this.head = current = new Node(null); 13 this.size =0;//单向链表,初始长度为零。 14 } 15 16 //定位函数,实现当前操作对象的前一个结点,也就是让当前结点对象定位到要操作结点的前一个结点。 17 //比如我们要在a2这个节点之前进行插入操作,那就先要把当前节点对象定位到a1这个节点,然后修改a1节点的指针域 18 public void index(int index) throws Exception 19 { 20 if(index <-1 || index > size -1) 21 { 22 throw new Exception("参数错误!"); 23 } 24 //说明在头结点之后操作。 25 if(index==-1) //因为第一个数据元素结点的下标是0,那么头结点的下标自然就是-1了。 26 return; 27 current = head.next; 28 int j=0;//循环变量 29 while(current != null&&j<index) 30 { 31 current = current.next; 32 j++; 33 } 34 35 } 36 37 @Override 38 public void delete(int index) throws Exception { 39 // TODO Auto-generated method stub 40 //判断链表是否为空 41 if(isEmpty()) 42 { 43 throw new Exception("链表为空,无法删除!"); 44 } 45 if(index <0 ||index >size) 46 { 47 throw new Exception("参数错误!"); 48 } 49 index(index-1);//定位到要操作结点的前一个结点对象。 50 current.setNext(current.next.next); 51 size--; 52 } 53 54 @Override 55 public Object get(int index) throws Exception { 56 // TODO Auto-generated method stub 57 if(index <-1 || index >size-1) 58 { 59 throw new Exception("参数非法!"); 60 } 61 index(index); 62 63 return current.getElement(); 64 } 65 66 @Override 67 public void insert(int index, Object obj) throws Exception { 68 // TODO Auto-generated method stub 69 if(index <0 ||index >size) 70 { 71 throw new Exception("参数错误!"); 72 } 73 index(index-1);//定位到要操作结点的前一个结点对象。 74 current.setNext(new Node(obj,current.next)); 75 size++; 76 } 77 78 @Override 79 public boolean isEmpty() { 80 // TODO Auto-generated method stub 81 return size==0; 82 } 83 84 @Override 85 public int size() { 86 // TODO Auto-generated method stub 87 return this.size; 88 } 89 90 91 }
3、测试类:(单链表的应用)
使用单链表建立一个线性表,依次输入十个0-99之间的随机数,删除第5个元素,打印输出该线性表。
(4)Test.java:
1 public class Test { 2 3 public static void main(String[] args) throws Exception { 4 // TODO Auto-generated method stub 5 LinkList list = new LinkList(); 6 for (int i = 0; i < 10; i++) { 7 int temp = ((int) (Math.random() * 100)) % 100; 8 list.insert(i, temp); 9 System.out.print(temp + " "); 10 } 11 12 list.delete(4); 13 System.out.println("\n------删除第五个元素之后-------"); 14 for (int i = 0; i < list.size; i++) { 15 System.out.print(list.get(i) + " "); 16 } 17 } 18 19 }
运行效果:

四、单链表的效率分析:
在单链表的任何位置上插入数据元素的概率相等时,在单链表中插入一个数据元素时比较数据元素的平均次数为:

删除单链表的一个数据元素时比较数据元素的平均次数为:

因此,单链表插入和删除操作的时间复杂度均为O(n)。另外,单链表读取数据元素操作的时间复杂度也为O(n)。
2、顺序表和单链表的比较:
顺序表:
优点:主要优点是支持随机读取,以及内存空间利用效率高;
缺点:主要缺点是需要预先给出数组的最大数据元素个数,而这通常很难准确作到。当实际的数据元素个数超过了预先给出的个数,会发生异常。另外,顺序表插入和删除操作时需要移动较多的数据元素。
单链表:
优点:主要优点是不需要预先给出数据元素的最大个数。另外,单链表插入和删除操作时不需要移动数据元素;
缺点:主要缺点是每个结点中要有一个指针,因此单链表的空间利用率略低于顺序表的。另外,单链表不支持随机读取,单链表取数据元素操作的时间复杂度为O(n);而顺序表支持随机读取,顺序表取数据元素操作的时间复杂度为O(1)。
标签:
原文地址:http://www.cnblogs.com/smyhvae/p/4761593.html