标签:
 浏览器控制 鼠标事件 键盘事件 获取验证sleep休眠 多表单切换 多窗口切换 上传文件
浏览器控制 鼠标事件 键盘事件 获取验证sleep休眠 多表单切换 多窗口切换 上传文件 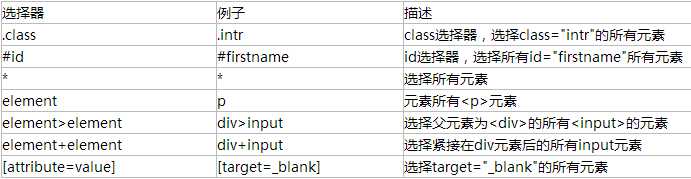
from selenium.webdriver.common.keys import Keys...dr.get("http://www.baidu.com")#输入内容dr.find_element_by_id("kw").send_keys("seleniumm")#删除输入内容的最后一个字母,dr.find_element_by_id("kw").send_keys(Keys.BACK_SPACE)#输入:空格+教程dr.find_element_by_id("kw").send_keys(Keys.SPACE)dr.find_element_by_id("kw").send_keys(u"教程")#ctrl+a全选输入框内容dr.find_element_by_id("kw").send_keys(Keys.CONTROL,‘a‘)#ctrl+x剪贴输入框内容dr.find_element_by_id("kw").send_keys(Keys.CONTROL,‘x‘)#ctrl+v剪贴输入框内容dr.find_element_by_id("kw").send_keys(Keys.CONTROL,‘v‘)#回车键操作dr.find_element_by_id("su").send_keys(Keys.ENTER)dr.close()
dr.titledr.current_urldr.find_element_by_id("xx").text
WebDriverWait(driver, timeout,poll_frequency,ignored_exceptions=None).until(method,message)示例:WebDriverWait(dr,5,0.5,None).until(expected_conditions.presence_of_element_located((By.ID,"kw1")),message=‘test‘)解释:A.WebDriverWait():在设置时间内,默认间隔一段时间检测一次当前页面元素是否存在,若超过当前指定时间检测不到则抛出异常;B.driver:webdriver的浏览器驱动,ie、firefox、chromeaC.timeout:最长超时时间,以秒为单位D.poll_frequency:休眠间隔时间-步长,默认0.5秒E.ignored_exceptions:超时后异常信息,默认抛出NoSuchElementException异常F.until(method,message): 调用该方法提供的驱动作为一个参数,直到返回值为TrueG.until_not(method,message):调用该方法提供的驱动作为一个参数,直到返回值为FalseH.expected_conditions类提供的预期条件实现有:title_is:判断标题是否是xxtitle_contains:判断标题是否包含xxpresence_of_element_located:元素是否存在
visibility_of_element_located:元素是否存在
visibility_of:是否可见
presence_of_all_elements_located:判断一组元素是否存在
text_to_be_present_in_element:判断元素是否有xx文本信息
text_to_be_present_in_element_value:判断元素值是否有xx文本信息
frame_to_be_available_and_switch_to_it:表单是否可见,并切换到该表单
invisibility_of_element_located:判断元素是否隐藏element_to_be_clickable:判断元素是否点击,它处于可见和启动状态staleness_of:等到一个元素不再依附于DOMelement_to_be_selected:被选中的元素element_located_to_be_selected:一个期望的元素位于被选中element_selection_state_to_be:一个期望检查如果给定元素被选中element_located_selection_state_to_be:期望找到一个元素并检查是否是选择状态alert_is_present:预期一个警告信息
<style type="text/css">body{font-size:12px; font-family:Tahoma;}.checkbox{vertical-align:middle; margin-top:0;}</style><body><input class="checkbox" type="checkbox" />元旦<input type="checkbox" name="test" />圣诞节<input type="checkbox" name="test" />股市<input type="checkbox" name="test" />阿凡达<input type="checkbox" name="test" />十月围城<input type="checkbox" name="test" />水价上调<input type="button" value="检测" id="btn" /></body>
- from selenium import webdriver
dr=webdriver.Firefox()dr.get("D:\\workspace\\pySelenium\\resources\\checkbox.htm")#使用tagname方式选择页面上所有tagname为input的元素select_tagname=dr.find_elements_by_tag_name("input")#使用xpath方式选择页面上所有tagname为input的元素select_xpath=dr.find_elements_by_xpath("//input[@type=‘checkbox‘]")#使用css_select方式选择页面上所有tagname为input的元素select_css=dr.find_elements_by_css_selector(‘input[type=checkbox]‘)for i in select_tagname:#循环对每个input元素进行点击选中操作if i.get_attribute("type")==‘checkbox‘:i.click()for j in select_xpath:#循环对每个input元素进行点击取消操作j.click()for k in select_css:#循环对每个input元素进行点击选中操作k.click()#打印出checkbox的个数print ‘----页面上checkbox的个数为:‘,len(select_css)#使用pop()获取1组元素的第几个元素select_css.pop(0).click() #第一个select_css.pop(1).click() #第二个select_css.pop().click() #最后一个select_css.pop(-1).click() #最后一个select_css.pop(-2).click() #倒数第二个dr.close()
<html><body><frameset><h3>frame</h3><iframe id=‘frameid‘ name=‘frameName‘ width="800" height="500" src="http://www.baidu.com"/></frameset></body></html>
dr.get("D:\\workspace\\pySelenium\\resources\\frame.htm")dr.switch_to_frame("frameid") #通过frame的id进入iframe#dr.switch_to_frame("frameName") #通过frame的name进入iframe#下面可以对frame进行操作了dr.find_element_by_id("kw").send_keys("selenium")dr.find_element_by_id("su").click()dr.switch_to_default_content() #退出当前frame返回上一层
dr.get("D:\\workspace\\pySelenium\\resources\\frame.htm")#定位到frame页面元素framepath=dr.find_element_by_class_name("frameClassname")dr.switch_to_frame(framepath) #通过frame页面对象进入iframe#下面可以对frame进行操作了dr.find_element_by_id("kw").send_keys("selenium")dr.find_element_by_id("su").click()dr.switch_to_default_content() #退出当前frame返回上一层
dr.get("http://www.baidu.com")current_handle=dr.current_window_handle #获取百度首页窗口句柄index_login=dr.find_element_by_xpath("//div[@id=‘u1‘]/a[@class=‘lb‘]") #获取登录按钮对象index_login.click() #点击登录dr.implicitly_wait(5)dr.find_element_by_class_name("pass-reglink").click() #点击立即注册按钮all_handles=dr.window_handles #获取所有打开窗口句柄for handle in all_handles:if handle==current_handle:dr.switch_to_window(handle)‘‘‘...对首页窗口进行操作‘‘‘print ‘----首页页面title:‘,dr.titlefor handle in all_handles:if handle!=current_handle:dr.switch_to_window(handle)‘‘‘...对注册窗口进行操作‘‘‘print ‘----注册页面title:‘,dr.title
dr.get("http://www.baidu.com")set_link=dr.find_element_by_xpath("//div[@id=‘u1‘]/a[@class=‘pf‘]") #找到设置链接元素ActionChains(dr).move_to_element(set_link).perform() #鼠标移动到设置上dr.find_element_by_xpath("//a[@class=‘setpref‘]").click() #点击搜索设置链接time.sleep(3)#加等待时间 等按钮可用,否则会报错save_set=dr.find_element_by_css_selector("#gxszButton > a.prefpanelgo")#获取保存设置按钮save_set.click() #点击保存设置按钮alert=dr.switch_to_alert()#进入alertprint ‘----弹出alert中内容为:‘,alert.text #打印对话框里的文字内容alert.accept() #对话框里点击alert中确定按钮#alert.dismiss() #对话框里点击取消按钮#alert.send_keys("对话框中输入的内容") #在对话框里输入内容
dr.get("D:\\workspace\\pySelenium\\resources\\upload.htm")loadFile=dr.find_element_by_name("filebutton") # 获取上传文件input元素节点loadFile.send_keys("D:\\workspace\\pySelenium\\resources\\frame.htm") #输入上传文件地址来实现上传
loadFile=dr.find_element_by_name("filebutton") # 获取上传按钮loadFile.click()#点击上传按钮,弹出上传对话框os.system("D:\\autoItFile.exe")#调用autoIt生成的exe文件,实现导入
ffp=webdriver.FirefoxProfile()ffp.set_preference("browser.download.folderList",2) #0:代表下载到浏览器默认路径下;2:下载到指定目录ffp.set_preference("browser.download.manager.showWhenStarting",False) #是否显示开始:True:显示;False:不显示ffp.set_preference("browser.download.dir", os.getcwd()) #指定下载文件目录,os.getcwd()无参数,返回当前目录# ffp.set_preference("browser.helperApps.neverAsk.saveToDisk","application/octet-stream")#下载文件类型,#指定下载页面的content-type值,application/octet-stream为文件类型,http-content-type常用对照表搜索百度dr=webdriver.Firefox(firefox_profile=ffp)dr.get("https://pypi.python.org/pypi/selenium#downloads")dr.find_element_by_xpath("//div[@id=‘content‘]/div[3]/table/tbody/tr[3]/td[1]/span/a[1]").click()#接下来使用autoIt实现
num=1dr.get("http://www.baidu.com")cookies=dr.get_cookies() #获取cookie的所有信息for ck in cookies:print ‘----所有cookie‘,num,‘:‘,ck #打印cookie的所有信息num=num+1print ‘----按name查cookie:‘,dr.get_cookie("PSTM") #通过cookie的name获取cookie信息dr.add_cookie({‘name‘:‘hello‘,‘value‘:‘123456789‘}) #向name和value添加会话信息cookies2=dr.get_cookies() #重新获取cookie的所有信息for ck2 in cookies2:if ck2[‘name‘]==‘hello‘:print "----加入的cookie信息:%s-->%s",(ck2[‘name‘],ck2[‘value‘])
dr.get("http://www.baidu.com")dr.find_element_by_id("kw").send_keys("selenium")dr.find_element_by_id("su").click()js="var q=document.documentElement.scrollTop=1000"#滚动条滚到最下面dr.execute_script(js)time.sleep(4)js2="var q=document.documentElement.scrollTop=0"#滚动条滚到页面顶dr.execute_script(js2)
dr.get("http://www.baidu.com")try:dr.find_element_by_id("kw1").send_keys("selenium")dr.find_element_by_id("su").click()except NoSuchElementException,msg:dr.get_screenshot_as_file("d:\\error.jpg")#截图输出到d盘print msgdr.close()
import randomrandnum=random.randint(1000,9999)print "----生成随机数为:",randnuminput_num=input(u"请输入验证码:")print "----输入验证码为:",input_numif input_num==randnum:print"随机数正确,登录成功"elif input_num==1234:print"输入正确,登录成功"else:print "登录失败"
标签:
原文地址:http://www.cnblogs.com/georgelei/p/4761956.html