标签:
网盘中提供下载的是数据库的for linux_32位版本0201_database_linux32.zip,而11g12c下载可到官方网站http://www.oracle.com/index.html, 去下载版本Oracle Database 11g Release 2 :
|
linux_11gR2_database_1of2.zip linux_11gR2_database_2of2.zip |

但10g已经不提供下载,注意哦,Release 2才是我们要的稳定版嘛。用BT下载,下载速度不是很稳定,你可以借助 FileZilla_3.3.3_win32-setup.exe,把下面2个文件传进 Linux 操作系统里面去,用FTP客户端,也可以不借助FTP软件而通过22远程端口连接:
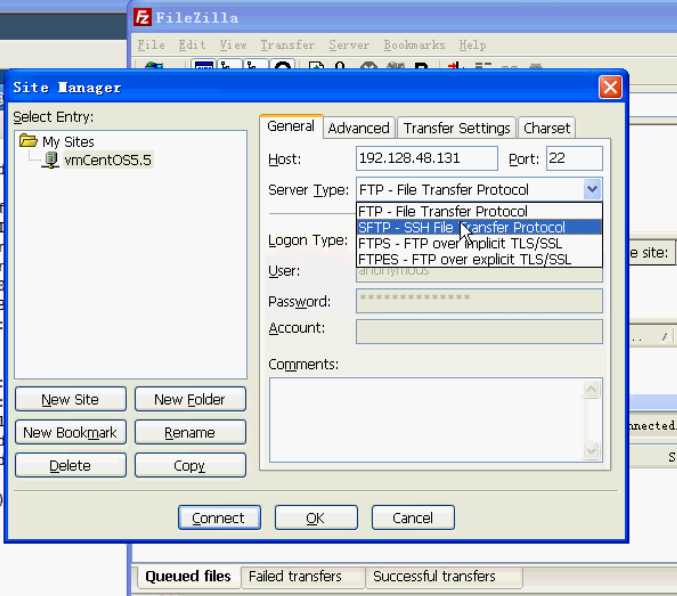 (选择ssh连接:)
(选择ssh连接:)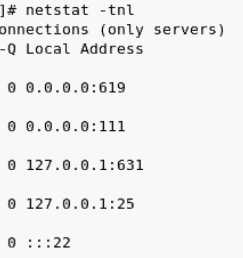 (选择22端口)
(选择22端口)
使用 unzip 命令解压 刚才上传的2个文件, 命令格式如下:unzip 文件名
准备工作,配置环境,检查相关的开发工具和一些包:检查命令格式如下:rpm -qa | grep 名字
|
binutils-2.17.50.0.6 ok compat-libstdc++-33-3.2.3 ok elfutils-libelf-0.125 ok elfutils-libelf-devel-0.125 -- elfutils-libelf-devel-static-0.125 -- gcc-4.1.2 ok gcc-c++-4.1.2 ok glibc-2.5-24 ok glibc-common-2.5 ok glibc-devel-2.5 ok glibc-headers-2.5 ok kernel-headers-2.6.18 ok ksh-20060214 ok libaio-0.3.106 ok libaio-devel-0.3.106 -- libgcc-4.1.2 ok libgomp-4.1.2 ok libstdc++-4.1.2 ok libstdc++-devel-4.1.2 ok make-3.81 ok numactl-devel-0.9.8.i386 -- sysstat-7.0.2 -- unixODBC-2.2.11 -- unixODBC-devel-2.2.11 -- |
==========================================
从 CentOS-6.5-x86_64-bin-DVD.iso\CentOS 文件找到缺少的包, 并且上传到 linux 上去,
ls *.rpm
rpm -ivh *.rpm
==========================================
创建用户组:
|
groupadd oinstall groupadd dba mkdir -p /u01/oracle |
添加一个oracle用户, 根目录是 /u01/oracle, 主的组是 oinstall 副的组是dba
|
useradd -g oinstall -G dba -d /u01/oracle oracle cp /etc/skel/.bash_profile /u01/oracle cp /etc/skel/.bashrc /u01/oracle cp /etc/skel/.bash_logout /u01/oracl |
为oracle用户设置密码 123456
|
passwd oracle /]#ls -l /]#chown -R oracle:oinstall u01 /]#ls -l |
检查 nobody 是否存在 , id nobody
缺省存在的。如果不存在 # /usr/sbin/useradd -g nobody
==========================================
vi /etc/sysctl.conf
|
fs.aio-max-nr = 1048576 fs.file-max = 6815744 kernel.shmall = 2097152 kernel.shmmax = 536870912 kernel.shmmni = 4096 kernel.sem = 250 32000 100 128 net.ipv4.ip_local_port_range = 9000 65500 net.core.rmem_default = 262144 net.core.rmem_max = 4194304 net.core.wmem_default = 262144 net.core.wmem_max = 1048586 |
==========================================
vi /etc/security/limits.conf
|
oracle soft nproc 2047 oracle hard nproc 16384 oracle soft nofile 1024 oracle hard nofile 65536 |
==========================================
vi /etc/pam.d/login
session required pam_limits.so
==========================================
su - oracle
pwd
ls -la
==========================================
vi .bash_profile
|
ORACLE_BASE=/u01 ORACLE_HOME=$ORACLE_BASE/oracle ORACLE_SID=wilson PATH=$ORACLE_HOME/bin:$PATH:$HOME/bin
export ORACLE_BASE ORACLE_HOME ORACLE_SID PATH |
==========================================
mv database /u01/
cd /u01
ls -l
chown -R oracle:oinstall database/
==========================================
重启一下系统,然后接着就开始安装了
|
使用oracle账号 登陆图形界面 进行安装
运行终端 Terminal
cd /u01/database
./runInstaller
Installation Optiong install database software only
Grid Options Single instance database installation
Product Languages English
Database Edition Enterprise Edition (3.95)
Installation Location Oracle Base: /u01 Software Loacation: /u01/oracle
提示: yes
Create Inventory mkdir /oraInventory
chown -R oracle:oinstall oraInventory
Operating System Groups Next
Prerequis ite Checks Ignore All
Summary Finish
Install Product 安装完毕, 提示执行 2个脚本
/oraInventory/orainstRoot.sh /u01/oracle/root.sh 直接按回车, 缺省值就可以
Finish The installation of Oracle Database was successful
====================================
上面只是安装了软件, 数据库没有创建, 还有配置 监听器 Listener
netca 一直默认下一步 , 呵呵, 最后 Finish
ps -ef 可以查看Listener是否配置成功
----------- dbca 一直 Next, Global Database Name 和 SID 都是输入 wilson
选择 User the Same.....All Accounts
密码: 123456
选择 Sample Schemas
Memory 内存分配,默认就可以了 Character Sets 选择 Use Unicode(AL32UTF8)
然后一直 Next , 到最后 Finish
弹出一个 Confirmation , 点击 OK 就可以了, 然后自动进行安装
安装到目录 /u01/oradata/wilson /u01/等等。。。 会发现多了很多文件。
-------------------- 然后可以修改 vi /etc/inittab 让 centos5.5 linux 启动的时候 不进入 图形界面 直接进入 字符界面
id:5:initdefault: 修改成 id:3:initdefault:
保存退出, 然后重启系统
-------------------------------- 用 oracle 用户 远程登录, 然后
$ sqlplus /nolog
SQL> conn / as sysdba
Connected to an idle instance. 出现错误
SQL> startup
[oracle@localhost ~]$ sqlplus /nolog
SQL*Plus: Release 11.2.0.1.0 Production on Fri Jun 25 15:05:54 2010
Copyright (c) 1982, 2009, Oracle. All rights reserved.
SQL> conn / as sysdba Connected. SQL> create table testUser( id integer,name char(10));
Table created.
SQL> insert into testUser values(0,‘Jack‘);
1 row created.
SQL> commit;
Commit complete.
SQL> select * from testUser;
ID NAME ---------- ---------- 0 Jack
关闭数据库 SQL> shutdown immediate
SQL> quit |
对数据记录的操作(select,insert,update,delete)
常用函数(count,max,min,avg,sum,decode,distinct)
|
CREATE TABLE xue_sheng( id integer, xing_ming varchar(25), nian_ling number); INSERT INTO xue_sheng VALUES(1,‘ZhanSan‘,24); INSERT INTO xue_sheng VALUES(2,‘LiSi‘,23); |
查询
|
SQL> SELECT * FROM xue_sheng; SQL> SELECT xing_ming FROM xue_sheng; |
插入数据
|
SQL> INSERT INTO xue_sheng VALUES(3,‘WangXiaoEr‘, 25); SQL> INSERT INTO xue_sheng(id,nian_ling) VALUES(4 , 25); |
查找order by desc(降序) 或者 asc(升序) 排序
|
SQL> SELECT * FROM xue_sheng ORDER BY nian_ling DESC; ASC |
查找字段为空或者非空
|
SQL> SELECT * FROM xue_sheng where xing_ming IS NULL; IS NOT NULL |
过滤重复字段
|
SQL> SELECT DISTINCT nian_ling FROM xue_sheng; |
更新表字段
|
SQL> UPDATE xue_sheng SET xing_ming=‘ZhanWu‘; SQL> UPDATE xue_sheng SET xing_ming=‘LiSi‘ where id=2; |
|
SQL> DELETE FROM xue_sheng where id=4; |
统计
|
SQL> SELECT COUNT(*) FROM xue_sheng; |
求和
|
SQL> SELECT SUM( nian_ling ) FROM xue_sheng; |
最大值
|
SQL> SELECT MAX( nian_ling ) FROM xue_sheng; |
最小值
|
SQL> SELECT MIN( nian_ling ) FROM xue_sheng; |
平均值
|
SQL> SELECT AVG( nian_ling ) FROM xue_sheng; |
DECODE函数使用, 可以理解成是一个判断分类函数
|
SQL> SELECT SUM(DECODE(nian_ling,25,1,0)),SUM(DECODE(nian_ling,24,1,0)) FROM xue_sheng; |
|
INSERT INTO xue_sheng(id,nian_ling) VALUES(5 , 25); |
|
SQL> SELECT SUM(DECODE(nian_ling,25,1,0)) n_25,SUM(DECODE(nian_ling,24,1,0)) n_24 FROM xue_sheng; |
需要注意 DELETE FROM 表名, 表示把表的数据全部清空
分组查询group by, 模糊查询/搜索like, 表连接join on, 子查询in() / not in()
|
DROP TABLE xue_sheng; DROP TABLE ban_ji; |
新建学生表: xue_sheng
|
CREATE TABLE xue_sheng( id integer, xing_ming varchar(25),xing_bie number, fen_shu number, b_id integer);
INSERT INTO xue_sheng VALUES(1,‘ZhanSan‘,1,80,1); INSERT INTO xue_sheng VALUES(2,‘LiSi‘,1,90,2); INSERT INTO xue_sheng VALUES(3,‘ZhanHong‘,0,75,2); INSERT INTO xue_sheng VALUES(4,‘ChenXiaoMing‘,1,85,1); |
查询要求: 分组显示男女同学的总分。先把性别分组, 然后进行一个求和的统计
|
SELECT xing_bie,sum(fen_shu) FROM xue_sheng GROUP BY xing_bie; |
模糊查询 或者 模糊查找,使用LIKE 关键字, 通用字符 ‘%‘
|
SELECT * FROM xue_sheng where xing_ming LIKE ‘Zhan%‘; SELECT * FROM xue_sheng where xing_ming LIKE ‘%g‘; SELECT * FROM xue_sheng where xing_ming LIKE ‘%a%‘; |
新建一个班级表: ban_ji
|
CREATE TABLE ban_ji( id integer , ban_ji varchar(25)); INSERT INTO ban_ji VALUES(1,‘1-(1)‘); INSERT INTO ban_ji VALUES(2,‘1-(2)‘); INSERT INTO ban_ji VALUES(3,‘1-(3)‘); SELECT id, ban_ji FROM ban_ji; |
学生表, 班级表一起查询(表连接):
|
别名的使用 SELECT x.id, xing_ming,ban_ji FROM xue_sheng x, ban_ji b; SELECT x.id, xing_ming,ban_ji FROM xue_sheng x, ban_ji b where x.b_id=b.id; SELECT x.id, xing_ming,ban_ji FROM xue_sheng x JOIN ban_ji b ON x.b_id=b.id; |
子查询 IN() 或者 NOT IN() ,又叫嵌套查询
|
SELECT * FROM xue_sheng WHERE b_id IN( 1,3 ); SELECT * FROM xue_sheng WHERE b_id=1 OR b_id=3; |
|
SELECT * FROM xue_sheng WHERE b_id IN( SELECT id FROM ban_ji ); |
显示 在1-(2)班级的所有同学:
做一个分解步骤来理解,
第一先步骤先执行 SELECT id FROM ban_ji where ban_ji=‘1-(2)‘;
第二步 , 在执行 SELECT * FROM xue_sheng WHERE b_id IN( 第一步的结果 );
|
SELECT * FROM xue_sheng WHERE b_id IN( SELECT id FROM ban_ji where ban_ji=‘1-(2)‘); |
NOT IN() 的使用
|
SELECT * FROM xue_sheng WHERE b_id NOT IN( SELECT id FROM ban_ji where ban_ji=‘1- (2)‘); |
VIEW 的介绍(方便,安全,一致)和使用(创建,修改)
|
表和视图的区别,表是占用硬盘空间物理表,而视图可以理解为一个虚表,并不存储在硬盘上,不占用硬盘空间,实际上就是一个查询语句,方便查询。对视图里面的数据操作(增 删 改) 其实就是对真实的表 增 删 改, 它们始终保持一致性。 |
哪为什么还需要视图 ?
视图可以理解成一个封装过的表, 例如不让用户 清楚知道表的某些字段信息,比较安全
|
CREATE TABLE xue_sheng( id integer, xing_ming varchar(25),xing_bie number, fen_shu number, b_id integer); INSERT INTO xue_sheng VALUES(1,‘ZhanSan‘,1,80,1); INSERT INTO xue_sheng VALUES(2,‘LiSi‘,1,90,2); INSERT INTO xue_sheng VALUES(3,‘ZhanHong‘,0,75,2); INSERT INTO xue_sheng VALUES(4,‘ChenXiaoMing‘,1,85,1); |
增加一个视图:
|
SQL> CREATE VIEW xs_view AS SELECT * FROM xue_sheng; CREATE VIEW xs_view AS SELECT * FROM xue_sheng * ERROR at line 1: ORA-01031: insufficient privileges scott没有创建视图的权限
|
赋权建立视图
|
SQL> conn /as sysdba Connected. SQL> grant connect,dba to scott; Grant succeeded.
SQL> conn scott/tiger Connected.
SQL> CREATE VIEW xs_view AS SELECT * FROM xue_sheng; View created. |
查询视图:
|
SELECT * FROM xs_view; |
往视图插入数据
|
INSERT INTO xs_view(id,xing_ming) VALUES(5,‘test‘); SELECT * FROM xs_view; SELECT * FROM xue_sheng; |
CREATE OR REPLACE 的使用 和 设置视图的权限 WITH READ ONLY 只读
|
CREATE OR REPLACE VIEW xs_view AS SELECT * FROM xue_sheng WITH READ ONLY; |
修改原来的视图, 其实就是做一个替换
|
SQL> INSERT INTO xs_view(id,xing_ming) VALUES(6,‘test2‘); INSERT INTO xs_view(id,xing_ming) VALUES(6,‘test2‘) * ERROR at line 1: ORA-42399: cannot perform a DML operation on a read-only view
提示这是一个 read-only view 只读的视图 |
这样使用视图比较方便。
|
CREATE OR REPLACE VIEW xs_view AS SELECT * FROM xue_sheng WHERE fen_shu >= 80; SELECT * FROM xs_view; |
|
CREATE TABLE ban_ji( id integer , ban_ji varchar(25));
INSERT INTO ban_ji VALUES(1,‘1-(1)‘);
INSERT INTO ban_ji VALUES(2,‘1-(2)‘);
INSERT INTO ban_ji VALUES(3,‘1-(3)‘); |
|
SELECT x.id, xing_ming,ban_ji FROM xue_sheng x JOIN ban_ji b ON x.b_id=b.id; |
建立一个简单的视图, 取代复杂的查询语句
|
CREATE OR REPLACE VIEW xs_view AS SELECT x.id, xing_ming,ban_ji FROM xue_sheng x JOIN ban_ji b ON x.b_id=b.id;
SELECT * FROM xs_view;
|
显示视图的字段和数据类型
|
DESC xs_view; |
存储过程PROCEDURE(介绍,输入,输出参数,使用,维护)
存储过程 - 执行一个任务,该任务包括了一系列的PL SQL语句,存储在数据库中,成为数据库一个对象。
- 效率比较高的,但你创建一个存储过程它会进行一个判断编译的。
创建一个简单的存储过程
|
SQL> CREATE OR REPLACE PROCEDURE xs_proc IS BEGIN NULL; END; / Procedure created. |
如何执行:
|
SQL> EXECUTE xs_proc; PL/SQL procedure successfully completed. |
或者执行
|
SQL> BEGIN 2 xs_proc; 3 END; 4 / PL/SQL procedure successfully completed. |
存储过程显示一些信息
|
SQL> CREATE OR REPLACE PROCEDURE xs_proc IS BEGIN DBMS_OUTPUT.PUT_LINE(‘hello‘); END; / |
|
SQL> EXECUTE xs_proc; |
要设置为ON , 才会把 hello 显示出来
|
SQL> SET SERVEROUTPUT ON SQL> EXECUTE xs_proc; |
|
CREATE TABLE xue_sheng( id integer, xing_ming varchar(25), yu_wen number,shu_xue number); INSERT INTO xue_sheng VALUES(1,‘ZhanSan‘,80,90); INSERT INTO xue_sheng VALUES(2,‘LiSi‘,85,87); |
只带一个输入参数 ,把查询的结果显示出来
|
SQL> CREATE OR REPLACE PROCEDURE xs_proc(temp_id IN integer) IS name varchar2(25); BEGIN select xing_ming into name from xue_sheng where id=temp_id; DBMS_OUTPUT.PUT_LINE(name); END; / |
|
SQL> execute xs_proc(1); ZhanSan |
当输入学生的名字, 就会把他的总分(语文+数学)显示出来。
|
CREATE OR REPLACE PROCEDURE xs_proc(temp_name IN varchar2 ) IS num_1 number; num_2 number; BEGIN select yu_wen,shu_xue into num_1,num_2 from xue_sheng where xing_ming=temp_name; DBMS_OUTPUT.PUT_LINE(num_1 + num_2); END; / SQL> EXECUTE xs_proc(‘ZhanSan‘); 170 |
输入参数 和 输出参数一起使用
|
SQL> CREATE OR REPLACE PROCEDURE xs_proc(temp_name IN varchar2,temp_num OUT number ) IS num_1 number; num_2 number; BEGIN select yu_wen,shu_xue into num_1,num_2 from xue_sheng where xing_ming=temp_name; temp_num := num_1 + num_2; END; / |
|
SQL> DECLARE tname varchar2(25); tnum number; BEGIN tname:=‘ZhanSan‘; xs_proc( tname,tnum ); DBMS_OUTPUT.PUT_LINE( tnum ); END; / 170 |
维护存储过程
1、查看过程状态
|
SELECT object_name,status FROM USER_OBJECTS WHERE object_type=‘PROCEDURE‘; |
2、重新编译过程
|
ALTER PROCEDURE xs_proc COMPILE; |
3、查看过程的源代码
|
SELECT * FROM USER_SOURCE WHERE TYPE=‘PROCEDURE‘; |
4、删除存储过程
|
DROP PROCEDURE xs_proc; |
事务transaction - 四大特性(原子性,一致性,隔离性,永久性)
银行账号里的转账,假设有2个账号, A账号和B账号 。
A 账号 转给 B 账号 100块钱,
(2个动作在里面, 1是A账号减去100块,2是B账号增加100块钱 ,2个动作不可分割-原子性)
如果当 B账号钱没有增加的时候, 那么A账号的钱不应该减少, 保持一致性。
|
CREATE TABLE zhang_hao( id integer, zhang_hu varchar(25), jin_e integer); INSERT INTO zhang_hao VALUES(1,‘A‘,1000); INSERT INTO zhang_hao VALUES(2,‘B‘,500); COMMIT; |
现在进行一个删除操作, 你会发现其实并不是真正的删除
用 scott 用户删除,永久性 - 一旦commit提交了就不能回滚了,数据将真正写入到表中
|
SQL> DELETE FROM zhang_hao where id=2; COMMIT; / ROLLBACK;’ |
|
SQL> show user; USER is "SCOTT" SQL> update zhang_hao set jin_e=300 where id=2; |
更新一条数据, 会出现2个用户同时更新的情况
解决并发一个办法:
当我在更新的时候 其他用户不能进行修改, 可以说是加上一个排它锁(隔离性)。
|
SELECT * FROM zhang_hao FOR UPDATE; 这样sys账号 就不能更新,在一个等待的状态中 UPDATE scott.zhang_hao SET jin_e=200 WHERE id=1; |
ms sql sever中的begin....transaction控制事务的一致性,
在oracle中有 commit 和 exception , rollback
如果你想多条语句提交一起执行一起回滚.用savepoint
也就是说 多条语句中 , 任意一条出现错误都会导致全部语句不执行,回滚。
|
A账号转800块钱给B账号。 这就要注意一个问题, 当A账号的钱转出去了,中途出现错误,B账号没有收到。 这种情况我们就不应该减少A账号的钱, 不执行操作, 做一个回滚。 |
|
create table test( tt varchar(30) );
SQL> create or replace procedure zh_proc as begin savepoint mystart; update zhang_hao set jin_e=200 where zhang_hu=‘A‘; insert into test values(‘dd‘); update zhang_hao set jin_e=1300 where zhang_hu=‘B‘; commit; exception when others then rollback to mystart; end; / |
|
5 update zhang_hao set jin_e=200 where zhang_hu=‘A‘; 6 insert into test values(‘dd‘); 7 update zhang_hao set jin_e=1300 where zhang_hu=‘B‘;
这3条语句任意一条出现执行错误, 都会回滚 rollback 到 开始的地方 mystart 。把3条语句看成一个整体。 |
|
删除 test 表 SQL> drop table test; |
目的为了 执行 SQL> drop table test; 出现错误
|
SQL> execute zh_proc; BEGIN zh_proc; END;
* ERROR at line 1: ORA-06550: line 1, column 7: PLS-00905: object SCOTT.ZH_PROC is invalid ORA-06550: line 1, column 7: PL/SQL: Statement ignored |
|
SQL> select * from zhang_hao;
ID ZHANG_HU JIN_E ---------- ------------------------- ---------- 1 A 1000 2 B 500
可以证明 update zhang_hao set jin_e=200 where zhang_hu=‘A‘; 这条语句被回滚了。
|
现在我们把test表新建回去
|
create table test( tt varchar(30) ); |
这样他就会成功提交执行那3条sql语句。
|
SQL> execute zh_proc;
PL/SQL procedure successfully completed.
SQL> select * from zhang_hao;
ID ZHANG_HU JIN_E ---------- ------------------------- ---------- 1 A 200 2 B 1300
|
触发器TRIGGER - 介绍,创建,使用,级联(删除,插入和更新)
|
触发器是一个特殊的存储过程。 区别就是在于, 存储过程需要去调用,而触发器无需调用,在执行某些操作的时候,会自动执行。一般当表或者视图执行 增,删,改 操作的时候,就会自动执行触发器中的PL SQL 语句块。还有一个区别, 创建触发器是不带参数的, 而 存储过程 可带可不带 参数。 |
数据库行级触发器 - 对每一行(每一条记录进行检查) 动作都触发 FOR EACH ROW
创建一个学生表:
|
CREATE TABLE xue_sheng( id integer, xing_ming varchar(25),xing_bie number, fen_shu number, b_id integer); INSERT INTO xue_sheng VALUES(1,‘ZhanSan‘,1,80,1); INSERT INTO xue_sheng VALUES(2,‘LiSi‘,1,90,2); INSERT INTO xue_sheng VALUES(3,‘ZhanHong‘,0,75,2); INSERT INTO xue_sheng VALUES(4,‘ChenXiaoMing‘,1,85,1); |
创建一个班级表:
|
CREATE TABLE ban_ji( id integer , ban_ji varchar(25)); INSERT INTO ban_ji VALUES(1,‘1-(1)‘); INSERT INTO ban_ji VALUES(2,‘1-(2)‘); |
创建一个删除行级触发器
当删除班级表的一个id , 那么它会自动把学生表所属的班级的学生也会删除
|
SQL> CREATE OR REPLACE TRIGGER del_ban_id AFTER DELETE ON ban_ji FOR EACH ROW BEGIN DELETE FROM xue_sheng where b_id=:old.id; END; / |
执行删除操作的时候, 建立一个 old内存表, old表和ban_ji表 结构完全一样
所以上面的 old.id 可以理解成 ban_ji班级表的 id
|
SQL> DELETE FROM ban_ji where id=2; 1 row deleted. |
查看,检查触发器是否自动执行了
|
select * from ban_ji; select * from xue_sheng; |
创建一个插入行级触发器
|
SQL> CREATE OR REPLACE TRIGGER insert_ban_ji AFTER INSERT ON ban_ji FOR EACH ROW BEGIN INSERT INTO xue_sheng VALUES(‘5‘,‘test‘,0,83,:new.id); END; /
|
当插入数据时候,先插入到 new 表,new表和班级表结构也是一样的。 然后在插入到 真正的表,
所以 new.id 和 ban_ji班级表id 对应的。
|
INSERT INTO ban_ji VALUES(3,‘1-(3)‘); |
查看,检查触发器是否自动执行了
|
select * from ban_ji; select * from xue_sheng; |
级联更新 同时涉及到 old.id 和 new.id
我要更新班级表的班级id, 当然学生表的班级id也要同时更新
|
SQL> CREATE OR REPLACE TRIGGER update_ban_ji AFTER UPDATE ON ban_ji FOR EACH ROW BEGIN UPDATE xue_sheng SET b_id=:new.id WHERE b_id=:old.id; END; / |
先查看一下原来2个表的数据
|
select * from xue_sheng; select * from ban_ji; |
然后更新班级表的id
|
UPDATE ban_ji SET id=8 WHERE id=1 |
最后查看一下效果
|
select * from ban_ji; select * from xue_sheng; |
触发器其实还有其他分类, 不过都是类似的使用
注意触发器建立所在表的选择
对 old.id 和 new.id 的理解
数据完整性 - 创建约束(主键,外键,CHECK,非空) 和 索引的使用
创建一个学生表:
|
CREATE TABLE xue_sheng( id integer, xing_ming varchar(25),xing_bie number, fen_shu number, b_id integer); INSERT INTO xue_sheng VALUES(1,‘ZhanSan‘,1,80,1); INSERT INTO xue_sheng VALUES(2,‘LiSi‘,1,90,2); INSERT INTO xue_sheng VALUES(3,‘ZhanHong‘,0,75,2); INSERT INTO xue_sheng VALUES(4,‘ChenXiaoMing‘,1,85,1); |
主键的唯一性(数据不能出现重复) , 基本上每一张表都会有这个主键
如果不设置学号id 这个唯一性, 就会出现学号重复的现象, 2个同学拥有相同的学号。
|
INSERT INTO xue_sheng VALUES(1,‘test‘,0,75,1); select * from xue_sheng; delete from xue_sheng where xing_ming=‘test‘; |
把 id 这个字段设置为主键:
|
ALTER TABLE xue_sheng ADD CONSTRAINT pk_xue_sheng PRIMARY KEY( id ); |
这样你再插入重复的id ,就会出错
|
INSERT INTO xue_sheng VALUES(1,‘test‘,0,75,1); ERROR at line 1: ORA-00001: unique constraint (SCOTT.PK_ID) violated |
删除主键:
|
ALTER TABLE xue_sheng DROP CONSTRAINT pk_xue_sheng; |
修改表中的 xing_ming 字段不能为空
|
INSERT INTO xue_sheng VALUES(5,‘‘,0,75,1); delete from xue_sheng where id=5; alter table xue_sheng modify xing_ming not null; |
|
SQL> desc xue_sheng; Name Null? Type ----------------------- -------- ------------ XING_MING NOT NULL VARCHAR2(25) |
CHECK 约束, 指定字段的值的内容, 例如 学生性别只能 是1或者0
|
insert into xue_sheng values(6,‘dd‘,3,50,1); SQL> ALTER TABLE xue_sheng ADD CONSTRAINT ck_xue_sheng CHECK(xing_bie=1 or xing_bie=0); ERROR at line 1: ORA-02293: cannot validate (SCOTT.CK_XUE_SHENG) - check constraint violated |
|
SQL> delete from xue_sheng where id=6; |
创建一个 CHECK 约束, xing_bie 只能是 1 或者 0
|
SQL> ALT ER TABLE xue_sheng ADD CONSTRAINT ck_xue_sheng CHECK(xing_bie IN(1,0)); |
删除约束
|
SQL> alter table xue_sheng drop CONSTRAINT ck_xue_sheng; |
外键,创建一个班级表:
|
CREATE TABLE ban_ji( id integer , ban_ji varchar(25)); INSERT INTO ban_ji VALUES(1,‘1-(1)‘); INSERT INTO ban_ji VALUES(2,‘1-(2)‘); |
|
insert into xue_sheng values(5,‘dd‘,0,50,3); |
现在在学生表插入数据,如果不对应 班级表的id也是可以插入的,不过这是没有意义的记录
|
ALTER TABLE xue_sheng ADD CONSTRAINT fk_xue_sheng FOREIGN KEY(b_id) REFERENCES ban_ji(id); ERROR at line 1: ORA-02270: no matching unique or primary key for this column-list |
错误提示要 班级表的id必须是主键或者具有唯一值
|
SQL> ALTER TABLE ban_ji ADD CONSTRAINT pk_ban_ji PRIMARY KEY( id ); Table altered. SQL> ALTER TABLE xue_sheng ADD CONSTRAINT fk_xue_sheng FOREIGN KEY(b_id) REFERENCES ban_ji(id); Table altered |
一旦创建了这个外键, 就不能在学生表随意插入数据,要参照班级表的id 。还有班级表的id 也不能随便修改或者删除, 因为如果修改了,学生表就没有数据参照了。
|
insert into xue_sheng values(5,‘dd‘,0,50,3); |
索引:
当数据量非常大的时候, 查询速度明显提高,对数据的一个有序排列
其实创建主键的时候已经对主键做了一个唯一索引
还有一个要注意的, 如果你有大量数据要插入表中, 先把数据插入数据表, 再建立索引,
否则会导致插入数据慢。
|
SQL> create index xs_xm_index on xue_sheng(xing_ming); Index created. SQL> select * from xue_sheng where xing_ming=‘ZhanSan‘; SQL> select * from xue_sheng where xing_ming like ‘%a%‘; |
对于唯一值很少的字段, 可以建立 位图索引, 例如 性别 只有 男,女
|
SQL> create bitmap index bit_xb on xue_sheng(xing_bie);
Index created. |
sql*loader
sql loader其实就是 把数据文件的数据插入到oracle数据表中
|
sqlldr userid control data |
也就是说要必须要先创建好 control控制文件 , data数据文件 。
|
CREATE TABLE ban_ji( id integer , ban_ji varchar(25)); INSERT INTO ban_ji VALUES(1,‘1-(1)‘); INSERT INTO ban_ji VALUES(2,‘1-(2)‘); |
有规律分割的数据文件以 "#" 井号, 分割数据
新建一个数据文件 mydata.txt , 内容如下:
|
3#1-(5) 4#2-(7) 5#3-(13)abc |
接下来新建一个控制文件 mycontrl.ctl , 针对数据文件如下:
|
load data infile ‘mydata.txt‘ append into table ban_ji( id char terminated by "#", ban_ji char terminated by "#" ) |
|
load data - 读取数据 append - 追加到表(不会覆盖原来表的内容) 执行sql loader 命令如下: [oracle@snow orcl]$ sqlldr scott/tiger control=./mycontrl.ctl data=./mydata.txt |
|
SQL*Loader: Release 11.2.0.1.0 - Production on Wed Jul 14 19:17:39 2010 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. Commit point reached - logical record count 3 提示有3条记录提交上去了, 添加到表里面了 |
验证一下, 是否真的添加到数据表中
|
sqlplus scott/tiger select * from ban_ji; |
SQL loader 就是这样的一个使用过程。
另外当你执行 sqlldr 系统会自动产生2个文件, log 和 bad 文件
针对上面的例子 就会产生 mycontrl.log mydata.bad 这两个文件
数据存储中, 有时会遇到数据丢失的情况,我们就需要定期做一个数据备份的工作。
在oracle中,使用EXP程序导出数据到文件进行备份, 而使用IMP就可以进行恢复。
EXP可以导出一个数据库, 也可以指定导出数据库的某个对象相关信息,
例如:数据表,表的某一列,或者表的相关信息。
|
CREATE TABLE xue_sheng( id integer, xing_ming varchar(25)); INSERT INTO xue_sheng VALUES(1,‘ZhanSan‘); INSERT INTO xue_sheng VALUES(2,‘LiSi‘); COMMIT; |
下面开始进行备份: (备份学生表里的全部数据)
|
[oracle@localhost ~]$ exp system/system <- 这里输入账号 Export: Release 11.2.0.1.0 - Production on Thu Jul 15 05:30:10 2010 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production With the Partitioning, OLAP, Data Mining and Real Application Testing options Enter array fetch buffer size: 4096 > 4096 <-这里是缓冲区大小, 默认4096 Export file: expdat.dmp > mydata.dmp <-输入备份文件名字,默认名字expdat.dmp (2)U(sers), or (3)T(ables): (2)U > T <- 因为我要备份表,所以选择T Export table data (yes/no): yes > yes <- 是否导出表中的数据 Compress extents (yes/no): yes > yes <- 是否对数据进行压缩 Export done in US7ASCII character set and AL16UTF16 NCHAR character set server uses AL32UTF8 character set (possible charset conversion) About to export specified tables via Conventional Path ... Table(T) or Partition(T:P) to be exported: (RETURN to quit) > xue_sheng <-输入备份的表名字 . . exporting table XUE_SHENG 2 rows exported <-导出提示信息 Table(T) or Partition(T:P) to be exported: (RETURN to quit) > <- 退出就直接回车 Export terminated successfully without warnings. |
如果刚才没有指定备份文件的具体路径,备份文件mydata.dmp就会在当前目录下
|
[oracle@localhost ~]$ ls my* mydata.dmp |
先把xue_sheng 表的数据全部删除
|
[oracle@localhost ~]$ sqlplus system/system SQL> select * from xue_sheng; SQL> delete from xue_sheng; SQL> commit; SQL> select * from xue_sheng; SQL> exit; |
使用 IMP 进行数据恢复
|
[oracle@localhost ~]$ imp system/system Import: Release 11.2.0.1.0 - Production on Thu Jul 15 05:54:32 2010 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production With the Partitioning, OLAP, Data Mining and Real Application Testing options Import data only (yes/no): no > yes Import file: expdat.dmp > mydata.dmp Enter insert buffer size (minimum is 8192) 30720> Export file created by EXPORT:V11.02.00 via conventional path import done in US7ASCII character set and AL16UTF16 NCHAR character set import server uses AL32UTF8 character set (possible charset conversion) List contents of import file only (yes/no): no > Ignore create error due to object existence (yes/no): no > Import grants (yes/no): yes > Import table data (yes/no): yes > Import entire export file (yes/no): no > yes . importing SCOTT‘s objects into SCOTT . . importing table "XUE_SHENG" 2 rows imported Import terminated successfully with warnings. |
验证一下数据是否被恢复
|
[oracle@localhost ~]$ sqlplus system/system SQL> select * from xue_sheng; |
还有拷贝文件的备份方式
例如将 /u01/oradata/wilson 目录下的所有文件拷贝到其他地方
|
control01.ctl redo01.log redo03.log system01.dbf undotbs01.dbf example01.dbf redo02.log sysaux01.dbf temp01.dbf users01.dbf |
oracle浅话深入之(3)—— oracle10g 11g 安装
标签:
原文地址:http://www.cnblogs.com/10years/p/4762165.html