标签:
Data Gurad概述
不少未实际接触过dg的初学者可能会下意识以为data guard是一个备份恢复的工具。我要说的是,这种形容不完全错,dg拥有备份的功能,某些情况下它甚至可以与primary数据库完全一模一样,但是它存在的目的并不仅仅是为了恢复数据,应该说它的存在是为了确保企业数据的高可用性,数据保护以及灾难恢复 ( 注意这个字眼,灾难恢复) 。dg提供全面的服务包括:创建,维护,管理以及监控standby数据库,确保数据安全,管理员可以通过将一些操作转移到standby数据库执行的方式改善数据库性能,构建高可用的企业数据库应用环境。 在Data Gurad 环境中,至少有两个数据库,一个处于Open 状态对外提供服务,这个数据库叫作Primary Database。第二个处于恢复状态,叫作Standby Database。运行时primary Database 对外提供服务,用户在Primary Database 上进行操作,操作被记录在联机日志和归档日志中,这些日志通过网络传递给Standby Database。这个日志会在Standby Database 上重演,从而实现Primary Database 和Standby Database 的数据同步。
Oracle Data Gurad 对这一过程进一步的优化设计,使得日志的传递,恢复工作更加自动化,智能化,并且提供一系列参数和命令简化了DBA工作。 如果是可预见因素需要关闭Primary Database,比如软硬件升级,可以把Standby Database 切换为Primary Database 继续对外服务,这样即减少了服务停止时间,并且数据不会丢失。如果异常原因导致Primary Database 不可用,也可以把Standby Database 强制切换为Primary Database继续对外服务,这时数据损失都和配置的数据保护级别有关系。因此Primary 和Standby 只是一个角色概念,并不固定在某个数据库中。
Data Guard 架构
DG架构可以按照功能分成3个部分:
1)日志发送(Redo Send)
2)日志接收(Redo Receive)
3)日志应用(Redo Apply)
1. 日志发送(Redo Send)
Primary Database 运行过程中,会源源不断地产生Redo 日志,这些日志需要发送到Standy Database。这个发送动作可以由Primary Database 的LGWR 或者ARCH进程完成,不同的归档目的地可以使用不同的方法,但是对于一个目的地,只能选用一种方法。选择哪个进程对数据保护能力和系统可用性有很大区别。
1.1 使用ARCH 进程
1)Primary Database 不断产生Redo Log,这些日志被LGWR进程写到联机日志。
2)当一组联机日志被写满后,会发生日志切换(Log Switch),并且会触发本
地归档,本地归档位置是采用 LOG_ARCHIVE_DEST_1=‘LOCATION=/path‘ 这种格式定义的。
如:alter system set log_archive_dest_1 = ‘LOCATION=/u01/arch‘ scope=both; 3)完成本地归档后,联机日志就可以被覆盖重用。
4)ARCH 进程通过Net 把归档日志发送给Standby Database的RFS(Remote File Server)进程。
5)Standby Database 端的RFS 进程把接收的日志写入到归档路径中。 6)Standby Database 端的MRP(Managed Recovery Process)进程(Redo Apply)或者LSP 进程(SQL Apply)在Standby Database上应用这些日志,进而同步数据。
参见下图:
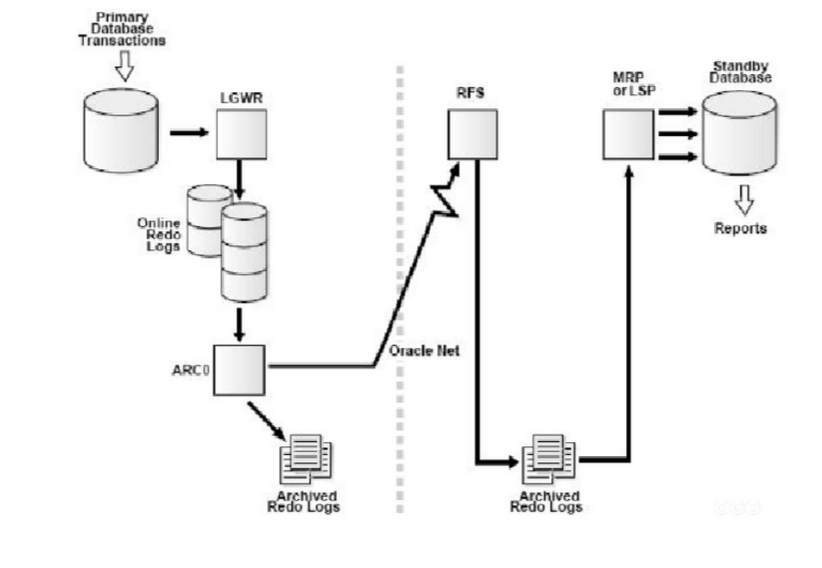
用ARCH模式传输不写Standby Redologs,直接保存成归档文件存放于Standby端。 说明:
逻辑Standby接收后将其转换成SQL语句,在Standby数据库上LSP进程执
行SQL语句实现同步,这种方式叫SQL Apply。
物理Standby接收完Primary数据库生成的REDO数据后,MRP进程以介质恢复的方式实现同步,这种方式也叫Redo Apply。
注意:创建逻辑Standby数据库要先创建一个物理Standby数据库,然后再将其转换成逻辑Standby数据库。
使用ARCH进程传递最大问题在于: Primary Database 只有在发生归档时才会发送日志到Standby Database。如果Primary Database 异常宕机,联机日志中的Redo内容就会丢失,因此使用ARCH 进程无法避免数据丢失的问题,要想避免数据丢失,就必须使用LGWR,而使用LGWR 又分SYNC(同步)和ASYNC(异步)两种方式。
在缺省方式下,Primary Database使用的是ARCH进程,参数设置如下: alter system set log_archive_dest_2 = ‘SERVICE=ST‘ scope=both; 1.2 使用LGWR 进程的SYNC 方式
1)Primary Database 产生的Redo日志要同时写到日志文件和网络。也就是说LGWR进程把日志写到本地日志文件的同时还要发送给本地的LNSn进程(Network Server Process),再由LNSn(LGWR Network Server process)进程把日志通过网络发送给远程的目的地,每个远程目的地对应一个LNS进程,多个LNS进程能够并行工作。
2)LGWR 必须等待写入本地日志文件操作和通过LNSn进程的网络传送都成功,Primary Database上的事务才能提交,这也是SYNC的含义所在。
3)Standby Database的RFS进程把接收到的日志写入到Standby Redo Log日志中。
4)Primary Database的日志切换也会触发Standby Database 上的日志切换,即Standby Database 对Standby Redo Log的归档,然后触发Standby Database 的MRP或者LSP进程恢复归档日志。
因为Primary Database 的Redo 是实时传递的,于是Standby Database 端可以使用两种恢复方法:
实时恢复(Real-Time Apply):只要RFS把日志写入Standby Redo Log 就会立即进行恢复;
归档恢复:在完成对Standby Redo Log 归档才触发恢复。
标签:
原文地址:http://my.oschina.net/u/2420214/blog/498576