标签:
由于项目需要用到Lucene,所以决定这个周末学一下Lucene,Lucene最新的版本是5.3.0。下载5.3.0后发现有点坑,文档的例子好像有点旧。
下面是文档中的代码片段,但是5.3.0的FSDirectory.open()参数是Path类型的,而不是String类型的。
1 Analyzer analyzer = new StandardAnalyzer(); 2 3 // Store the index in memory: 4 Directory directory = new RAMDirectory(); 5 // To store an index on disk, use this instead: 6 //Directory directory = FSDirectory.open("/tmp/testindex"); 7 IndexWriterConfig config = new IndexWriterConfig(analyzer); 8 IndexWriter iwriter = new IndexWriter(directory, config); 9 Document doc = new Document(); 10 String text = "This is the text to be indexed."; 11 doc.add(new Field("fieldname", text, TextField.TYPE_STORED)); 12 iwriter.addDocument(doc); 13 iwriter.close(); 14 15 // Now search the index: 16 DirectoryReader ireader = DirectoryReader.open(directory); 17 IndexSearcher isearcher = new IndexSearcher(ireader); 18 // Parse a simple query that searches for "text": 19 QueryParser parser = new QueryParser("fieldname", analyzer); 20 Query query = parser.parse("text"); 21 ScoreDoc[] hits = isearcher.search(query, null, 1000).scoreDocs; 22 assertEquals(1, hits.length); 23 // Iterate through the results: 24 for (int i = 0; i < hits.length; i++) { 25 Document hitDoc = isearcher.doc(hits[i].doc); 26 assertEquals("This is the text to be indexed.", hitDoc.get("fieldname")); 27 } 28 ireader.close(); 29 directory.close();
我个人不太喜欢接触最新版本的东西,最新的东西一般网上的资料都很少,这会给学习带来不少麻烦,但是在Apache官网找了很久没找到旧版本的,所以也只能学5.3.0。
下面是根据文档自己编写的一个小DEMO(以书为例子创建索引库)。
整个目录的结构如下:
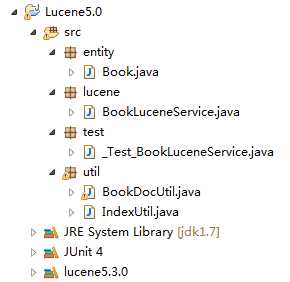
这里我对经常用到的代码进行了提取,创建了两个工具类:IndexUtil(提供indexWriter和indexSearcher),BookDocUtil(实现Book实体和Document对象的转化)。
1、IndexUtil.java
1 package util; 2 3 import java.nio.file.Paths; 4 import org.apache.lucene.analysis.Analyzer; 5 import org.apache.lucene.analysis.standard.StandardAnalyzer; 6 import org.apache.lucene.index.DirectoryReader; 7 import org.apache.lucene.index.IndexWriter; 8 import org.apache.lucene.index.IndexWriterConfig; 9 import org.apache.lucene.search.IndexSearcher; 10 import org.apache.lucene.store.Directory; 11 import org.apache.lucene.store.FSDirectory; 12 13 public class IndexUtil { 14 15 private static final String INDEX_DIR = "./index"; 16 private static IndexWriter iWriter; 17 private static IndexSearcher iSearcher; 18 19 private IndexUtil(){} 20 21 public static IndexWriter getIndexWriter() { 22 try { 23 Directory dir = FSDirectory.open(Paths.get(INDEX_DIR)); 24 Analyzer analyzer = new StandardAnalyzer(); 25 IndexWriterConfig iwc = new IndexWriterConfig(analyzer); 26 iWriter = new IndexWriter(dir, iwc); 27 } catch (Exception e) { 28 throw new RuntimeException(e); 29 } 30 return iWriter; 31 } 32 33 public static IndexSearcher getIndexSearcher() { 34 try { 35 Directory dir = FSDirectory.open(Paths.get(INDEX_DIR)); 36 DirectoryReader dirReader = DirectoryReader.open(dir); 37 iSearcher = new IndexSearcher(dirReader); 38 } catch (Exception e) { 39 throw new RuntimeException(e); 40 } 41 return iSearcher; 42 } 43 }
2、BookDocUtil.java
1 package util; 2 3 import org.apache.lucene.document.Document; 4 import org.apache.lucene.document.Field; 5 import org.apache.lucene.document.Field.Index; 6 import org.apache.lucene.document.Field.Store; 7 8 import entity.Book; 9 10 public class BookDocUtil { 11 12 private BookDocUtil(){} 13 14 public static Document book2Doc(Book book) { 15 Document doc = new Document(); 16 Field field = null; 17 field = new Field("id", book.getId().toString(), Store.YES, Index.NOT_ANALYZED); 18 doc.add(field); 19 field = new Field("isbn", book.getIsbn(), Store.YES, Index.NO); 20 doc.add(field); 21 field = new Field("name", book.getName(), Store.YES, Index.ANALYZED); 22 doc.add(field); 23 field = new Field("author", book.getAuthor(), Store.YES, Index.NO); 24 doc.add(field); 25 field = new Field("introduction", book.getIntroduction(), Store.YES, Index.ANALYZED); 26 doc.add(field); 27 return doc; 28 } 29 30 public static Book doc2Book(Document doc) { 31 Book book = new Book(); 32 book.setId(Integer.parseInt(doc.get("id"))); 33 book.setIsbn(doc.get("isbn")); 34 book.setName(doc.get("name")); 35 book.setAuthor(doc.get("author")); 36 book.setIntroduction(doc.get("introduction")); 37 return book; 38 } 39 }
这里我是以书为例子,下面是书的实体类,为了便于打印,这里重写了toString()方法。
3、Book.java
1 package entity; 2 3 public class Book { 4 5 private Integer id; 6 private String isbn; 7 private String name; 8 private String author; 9 private String introduction; 10 11 // 这里省略了setter , getter 12 13 @Override 14 public String toString() { 15 return new StringBuffer() 16 .append("#id : " + this.id) 17 .append("\t#isbn : " + this.isbn) 18 .append("\t#name : " + this.name) 19 .append("\t#author : " + this.author) 20 .append("\tintroducation : " + this.introduction) 21 .toString(); 22 } 23 }
第一次接触Lucene,仅仅在BookLuenceService中实现了两个功能 save()、query()。
4、BookLuceneService.java
1 package lucene; 2 3 import java.io.IOException; 4 import java.util.ArrayList; 5 import java.util.List; 6 7 import org.apache.lucene.document.Document; 8 import org.apache.lucene.index.IndexWriter; 9 import org.apache.lucene.index.Term; 10 import org.apache.lucene.search.IndexSearcher; 11 import org.apache.lucene.search.ScoreDoc; 12 import org.apache.lucene.search.TermQuery; 13 import org.apache.lucene.search.TopDocs; 14 15 import entity.Book; 16 import util.BookDocUtil; 17 import util.IndexUtil; 18 19 public class BookLuceneService { 20 21 private boolean debug = false; 22 23 public BookLuceneService(boolean debug) { 24 this.debug = debug; 25 } 26 27 public void save( Book book ) { 28 IndexWriter iWriter = IndexUtil.getIndexWriter(); 29 try { 30 iWriter.addDocument(BookDocUtil.book2Doc(book)); 31 } catch (IOException e) { 32 throw new RuntimeException(e); 33 } finally { 34 try { 35 iWriter.close(); 36 } catch (IOException e) { 37 throw new RuntimeException(e); 38 } 39 } 40 } 41 42 public List<Book> query(Integer id) { 43 List<Book> bookList = new ArrayList<Book>(); 44 IndexSearcher iSearcher = IndexUtil.getIndexSearcher(); 45 try { 46 TopDocs topDocs = iSearcher.search(new TermQuery(new Term("id", id.toString())), 10); 47 ScoreDoc []scoreDocs = topDocs.scoreDocs; 48 49 ScoreDoc sTemp = null; 50 Document doc = null; 51 for (int i = 0; i < scoreDocs.length; i++) { 52 sTemp = scoreDocs[i]; 53 //-----debug info----------- 54 if (debug) System.err.println("doc : " + sTemp.doc + "\tscore : " + sTemp.score); 55 //-------------------------- 56 doc = iSearcher.doc(sTemp.doc); 57 bookList.add(BookDocUtil.doc2Book(doc)); 58 } 59 60 } catch (IOException e) { 61 throw new RuntimeException(e); 62 } 63 return bookList; 64 } 65 66 }
最后创建一个测试类对这两个功能进行测试( 首先运行testSave()创建索引,然后运行testQuery()进行查询 ):
5、_Test_BookLuceneService.java
1 package test; 2 3 import org.junit.AfterClass; 4 import org.junit.BeforeClass; 5 import org.junit.Test; 6 7 import entity.Book; 8 import lucene.BookLuceneService; 9 10 public class _Test_BookLuceneService { 11 12 private static BookLuceneService bookLuceneService; 13 14 @BeforeClass 15 public static void init() { 16 bookLuceneService = new BookLuceneService(true); 17 } 18 19 20 // @Test 21 public void testSave() { 22 23 Book book = new Book(); 24 book.setId(1); 25 book.setIsbn("978-7-121-21732-6"); 26 book.setName("Hello World"); 27 book.setAuthor("ITC10"); 28 book.setIntroduction("Say hello world to every language."); 29 30 bookLuceneService.save(book); 31 } 32 33 @Test 34 public void testQuery() { 35 36 for( Book book : bookLuceneService.query(1)) { 37 System.out.println(book.toString()); 38 } 39 } 40 41 @AfterClass 42 public static void destroy () { 43 bookLuceneService = null; 44 } 45 }
测试testQuery()结果如下:
1 doc : 0 score : 0.30685282 2 #id : 1 #isbn : 978-7-121-21732-6 #name : Hello World #author : ITC10 introducation : Say hello world to every language.
这里可以刷新项目工程目录,会发现多了一个index目录,这就是索引库的位置。
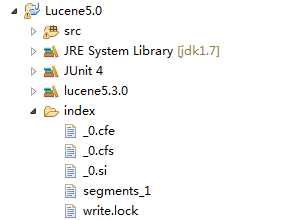
。
第一次学Lucene还得继续慢慢摸索。
标签:
原文地址:http://www.cnblogs.com/itc10/p/4769412.html