标签:
一、为什么要有异常处理机制?
java中的异常处理机制简单的讲就是try..catch..finally的使用。
程序难免会出现错误, 如果没有异常处理机制, 那么程序员在编写代码的时候就必须检查特定的结果, 并在程序的很多地方去处理它。 有了异常处理机制后,就不必在每个方法调用处都检查, 只需要用try包裹住可能发生异常的代码段, 这样做的好处是:
1.降低了代码的复杂度,正如上面所说的,不需要每个方法调用处都去检查;
2.将“描述正常情况下应该做什么事情”和“如果出了错怎么办” 的逻辑分开;
3.实现恢复模型: 异常处理理论有两种基本模型,终止模型和恢复模型, 终止模型就是发生异常程序就终止了 ;恢复模型则正是catch中所提供的功能, 它可以在发生异常的时候不抛出,选择继续往下执行, 这就是恢复模型
二、java中异常类型的说明
1.java中有一个根接口Throwable, 它的实现类有三种:
1)error: 这种异常,比如栈溢出, 是“致命”的, 发生了程序会立即终止;
2)exception: 普通异常, 比如IOException, 这种异常典型的就是你写一个方法调用IO流处理,必须在方法内部用try..catch处理或者在方法上声明throws
这种普通异常会在编译期间就进行检查, 如果没有被显式处理则编译都不能通过;
3)runtime-exception: 运行时异常,比如NullPointException, 这种异常在运行阶段发生, 可以不必显式写明try..catch 或者throws
2.自定义异常
正如上面所讲的, Java中已经提供了三种最基本类型的异常,同时也有IOExcepiton等多个异常供你使用, 但是具体工作中还是可能遇到跟业务逻辑相关的错误情景, 这时比较好的方式是自定义异常来处理。
1 package com.zk.exception; 2 3 public class MyError extends Error{ 4 private static final long serialVersionUID = 3391397569507838918L; 5 6 public MyError() { 7 System.out.println("致命性异常"); 8 } 9 } 10 11 package com.zk.exception; 12 13 public class MyException extends Exception{ 14 private static final long serialVersionUID = -264744505170671061L; 15 16 public MyException() { 17 System.out.println("普通异常"); 18 } 19 } 20 21 package com.zk.exception; 22 23 public class MyRuntimeException extends RuntimeException{ 24 25 private static final long serialVersionUID = 8073126103901733888L; 26 27 public MyRuntimeException() { 28 System.out.println("运行时异常"); 29 } 30 }
三、适当的使用try-catch
由于try-catch中会有额外的内存消耗,所以不要过多的使用try-catch , 典型的例子就是当try-catch 和foreach一起使用时,
最好是在最外层写try-catch,然后里面写foreach 。
1.适合使用try-catch的地方
1)调用了会抛出普通一场的方法, 这个是编译期就会检查的
2)调用别的服务类的服务方法的地方
3)一整段逻辑比较复杂, 却要当做是一个事务的地方
2.异常处理时,必须适当的日志
这本是推荐性质的要求, 但是在项目组中, 很可能被要求为“必须”级别。 尤其是catch中, 如果catch中采用的是恢复模型(即没有throw新的异常,而是向下继续执行),那么就必须写上日志, 否则这个异常则可能被忽略。
记住这么一个原则: 任何异常都不应该被忽略。
另外, 异常如果要输出到控制台, 调用System.out.error, 而不要调用System.out.println
四、捕获异常注意事项
可以通过catch来捕获异常,但是注意一点,不要先写范围广的catch,否则下面将不能得到执行机会,比如:
try {
...
} catch(Exception e) {
...
} catch(NullPointException e) {
...
}
这种情况就是问题,由于第一个catch的存在,它捕获所有的异常,包括空指针,那么当真正空指针异常发生的时候,也是执行第一个,
而异常机制就是执行了一个后,就不往下继续执行了。这样的话,第二个就没有机会执行了。
捕获异常要先写小范围的,后写大范围的。
五、栈轨迹 getStackTrace()
1 public class StackTrace { 2 3 public static void main(String[]args) { 4 int i=0; 5 try { 6 i = 10/0; 7 } catch(Exception e) { 8 System.out.println(e.getStackTrace()); 9 10 System.out.println("*****"); 11 for(StackTraceElement s : e.getStackTrace()) { 12 System.out.println(s); 13 } 14 15 System.out.println("***"); 16 e.printStackTrace(); 17 } 18 } 19 }
结果如下:
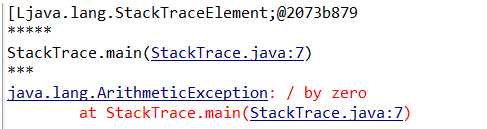
这里要提到的就是, e.getStackTrace()方法,返回的是异常栈的轨迹的数组, 因为没有重写toString方法,所以这里直接显示的StackTraceElement;@... 这一段显示是没有意义的。
所以如果想要打印出来完整的异常信息,通过e.getStackTrace()方法,获得数组,然后for循环一个一个显示, 这种写法是有意义的,能够找出来出错的栈轨迹。
六、重新抛出异常
简单的讲,重新抛出异常就是在catch中再throw new **Exception
但是这里需要注意的一个事情,还是要关联到前面提到过的“任何异常都不应该被忽视”原则, 见下例:
1 public class ThrowExceptionTest { 2 public static void main(String[]args){ 3 try { 4 int i=0; 5 i = 10/0; 6 } catch(Exception e) {//第一次捕获异常 7 try { 8 e.printStackTrace(); 9 System.out.println("***"); 10 throw new MyException1("抛个自定义异常");//捕获异常中,再抛一次异常 11 12 // System.out.println("**"); //这里报错,在catch的throw语句后,不能再其他语句了,因为跳转了执行不到,被认为编译期错误 13 14 } catch(MyException1 e2) {//再次捕获异常 15 try { 16 throw new MyException2("再抛个自定义异常");//第二次抛出自定义异常 17 } catch (MyException2 e1) { 18 /** 19 * 下面打印栈信息 20 */ 21 System.out.println("***"); 22 e1.printStackTrace();//最终打印异常站信息 23 } 24 } 25 } 26 } 27 } 28 29 30 class MyException1 extends Exception { 31 public MyException1(String s) { 32 System.out.println(s); 33 } 34 } 35 36 class MyException2 extends Exception { 37 public MyException2() { 38 } 39 40 public MyException2(String s) { 41 System.out.println(s); 42 } 43 }
结果如下:

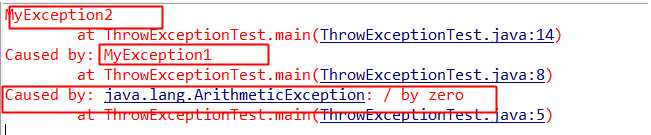
这里只会打印最后抛出的异常的信息, 却会忽略掉第一次的异常信息。
Java异常机制中提供了一个叫做异常链的机制, 可以用来解决上面问题:
1 public class ThrowExceptionTest { 2 public static void main(String[]args){ 3 try { 4 int i = 10/0; 5 } catch(Exception e) {//第一次捕获异常 6 try { 7 MyException1 me1 = new MyException1();//捕获异常中,再抛一次异常 8 me1.initCause(e); 9 throw me1; 10 11 } catch(MyException1 e2) {//再次捕获异常 12 try { 13 MyException2 me2 = new MyException2(); 14 me2.initCause(e2);//通过此方法, 将两次异常加入同一个异常链中 15 16 throw me2;//第二次抛出自定义异常 17 } catch (MyException2 e1) { 18 /** 19 * 下面打印栈信息 20 */ 21 e1.printStackTrace();//最终打印异常站信息 22 } 23 } 24 } 25 } 26 } 27 28 29 class MyException1 extends Exception { 30 } 31 32 class MyException2 extends Exception { 33 }
结果如下:
七、异常处理机制中的finally
1.一般对于“连接性质”的操作, 最后的关闭操作都是在finally, 比如数据库连接
2.try中如果有break, continue , return , 最后finally中的语句还会会执行,见下例:
1 public class FinallyTest { 2 public static void main(String[]args) { 3 try { 4 int i=10/0; 5 } catch(Exception e) { 6 System.out.println("异常1"); 7 } finally { 8 System.out.println("执行finally --1"); 9 } 10 11 try { 12 int i=1; 13 } catch(Exception e ) { 14 System.out.println("异常2"); 15 } finally { 16 System.out.println("执行finally --2"); 17 } 18 19 try { 20 for(int i=1;i<10;i++) { 21 break; 22 } 23 } catch(Exception e) { 24 System.out.println("异常3"); 25 } finally { 26 System.out.println("执行finally --3"); 27 } 28 29 30 try { 31 for(int i=1;i<10;i++) { 32 continue; 33 } 34 } catch(Exception e) { 35 System.out.println("异常4"); 36 } finally { 37 System.out.println("执行finally --4"); 38 } 39 40 try { 41 return ; 42 } catch(Exception e) { 43 System.out.println("异常5"); 44 } finally { 45 System.out.println("执行finally --5"); 46 } 47 } 48 }
结果如下:

关于这个return 和finally ,为什么finally会执行,为什么finally甚至会在return语句后面执行,当初设计的时候是出于如下考虑:
比如一个try中有几个地方可以return , 那么在return之前还需要进行一个清理工作,当然一种做法是在每一个return前面都加清理语句, 但是这显然不是很好的设计。
所以设计的finally中 一定在return后面并且一定会执行, 这样我们就可以把清理语句统一放在finally中。
八、当异常碰到继承
在覆盖方法的时候, 只能够抛出在基类方法的异常说明里面列出来的那些异常。
1 //测试异常限制 2 public class ExceptionStrict { 3 public static void main(String[]args) { 4 5 } 6 7 } 8 9 class A { 10 public void f() throws AException { 11 12 } 13 14 public void t() throws BException { 15 16 } 17 } 18 19 20 class B extends A { 21 // @Override 22 // public void f() throws AException { //这一段注释的是允许的,因为它的父类f()抛出AException,这里是可以抛出AException的 23 // } 24 25 @Override 26 public void f() throws BException { //这里 BException 是AException的子类,覆盖f()方法的时候允许抛出一个原来异常的子类 27 } 28 29 @Override 30 public void t() throws BException { 31 32 } 33 34 // @Override 35 // public void t() throws AException { //这一段如果放开注释,会报错! ,覆盖方法,不能够抛出原异常的父类,只能抛出原异常或者原异常的子类 36 // 37 // } 38 } 39 40 41 class AException extends Exception { 42 43 } 44 45 class BException extends AException { 46 47 }
理解:抛出一个异常,说明允许处理的异常范围。 父类抛出一个异常,子类覆盖方法,在异常方面不能够超过原异常的范围, 而原异常的子类一定在原异常的范围内。
尽管在继承过程中,编译器会对异常说明做强制要求,但异常说明本身并不属于方法类型的一部分,方法类型是由方法的名字与参数的类型组成的。 因此,不能够基于异常来说明重载方法。
此外,一个出现在基类方法的异常说明中的异常,不一定会出现在派生类方法的异常说明中, 这里同继承的规则有明显的不同,在继承中,基类方法必须出现在派生类中,
换一句话说, 某个特定方法的异常说明,在继承和覆盖的过程中不是变大了,而是变小了。
九、把普通异常转为运行时异常
try {
}catch(Exception e) {
RuntimeException re = new RuntimeException();
...
throw re;
}
经过这么处理后,虽然有抛出,但是在最外层方法体中,不需要再声明 throws了。这种写法纯看个人喜欢了。
标签:
原文地址:http://www.cnblogs.com/kaiguoguo/p/4771088.html