标签:
转自: http://www.cnblogs.com/zhijianliutang/p/4190669.html
概念理解
关于SQL Server中的统计信息,在联机丛书中是这样解释的
查询优化的统计信息是一些对象,这些对象包含与值在表或索引视图的一列或多列中的分布有关的统计信息。查询优化器使用这些统计信息来估计查询结果中的基数或行数。通过这些基数估计,查询优化器可以创建高质量的查询计划。例如,查询优化器可以使用基数估计选择索引查找运算符而不是耗费更多资源的索引扫描运算符,从而提高查询性能。
其实关于统计信息的作用通俗点将就是:SQL Server通过统计信息理解库中每张表的数据内容项分布,知道里面数据“长得啥德行,做到心中有数”,这样每次查询语句的时候就可以根据表中的数据分布,基本能定位到要查找数据的内容位置。
比如,我记得我以前有篇文章写过一个相同的查询语句,但是产生了完全不同的查询计划,这里回顾下,基本如下:
SELECT * FROM Person.Contact WHERE FirstName LIKE ‘K%‘ SELECT * FROM Person.Contact WHERE FirstName LIKE ‘Y%‘
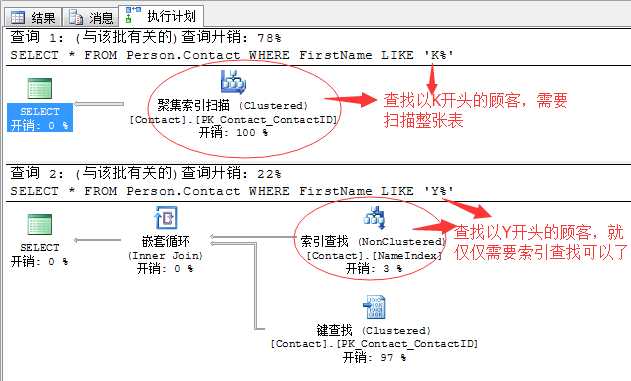
完全相同的查询语句,只是查询条件不同,一个查找以K开头的顾客,一个查找以Y开头的顾客,却产生了完全不同的查询计划。
其实,这里的原因就是统计信息在作祟。
我们知道,在这张表的FirstName字段存在一个非聚集索引,目标就是为了提升如上面的查询语句的性能。
但是这张表里面FirstName字段中的数据内容以K开头的顾客存在1255行,也就是如果利用非聚集索引查找的方式,需要产生1225次IO操作,这可能不是最糟的,糟的还在后面,因为我们获取的数据字段并不全部在FirstName字段中,而需要额外的书签查找来获取,而这个书签查找会产生的大量的随机IO操作。记住:这里是随机IO。关于这里的查找方式在我们第一篇文章中就有介绍。
所以相比利用非聚集索引所带来的消耗相比,全部的所以索引扫描来的更划算,因为它依次扫描就可以获取想要的数据。
而以Y开头的就只有37行,37行数据完全通过非聚集索引获取,再加一部分的书签查找很显然是一个很划算的方式。因为它数据量少,产生的随机IO量相对也会少。
所以,这里的问题来了:
SQL Server是如何知道这张表里FirstName字段中以K开头的顾客会比较多,而以Y开头反而少呢?。
这里就是统计信息在作祟了,它不但知道FirstName字段中各行数据的内容“长啥样”,并且还是知道每行数据的分布情况。
其实,这就好比在图书库中,每个书架就是一张表,而每本书就是一行数据,索引就好像图书馆书籍列表,比如按类区分,而统计信息就好像是每类书籍的多少以及存放书架位置。所以你借一本书的时候,需要借助索引来查看,然后利用统计信息指导位置,这样才能获取书本。
希望这样解释,看官已经明白了统计信息的作用了。
这里多谈点,有很多童鞋没有深入了解索引和统计信息的作用前提下,在看过很多调优的文章之后,只深谙了一句话:调优嘛,创建索引就行了。
我不否认创建索引这种方式调优方式的作用性,但是很多时候关于建索引的技巧却不了解。更巧的是大部分情况下属于误打误撞创建完索引后,性能果真提升了,而有时候创建的索引却毫无用处,只会影响表的其它操作的性能(尤其是Insert),更有甚者会产生死锁情况。
而且,关于索引项的作用,其实很多的情况下,并不想你想象的那么美好,后续文章我们会分析那些索引失效的原因。
所以遇到问题,其实还要通过表象理解其本质,这样才能做到真正的有的放矢,有把握的解决问题。
解析统计信息
我们来详细分析一下统计信息中的内容项,我们知道在上面的语句中,在表Customers中ContactName列中存在一个非聚集索引项,所以在该列存在统计信息,我们可以通过如下脚本查看该表的统计信息列表
sp_helpstats Customers
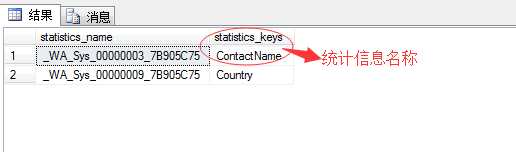
然后通过以下命令来查看该统计信息的详细内容,代码如下
DBCC SHOW_STATISTICS(Customers,ContactName)
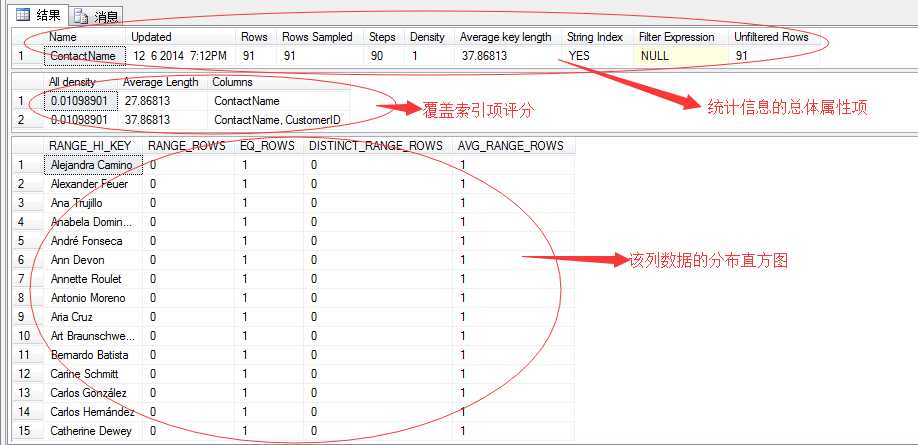
每一个统计信息的内容都包含以上三部分的内容。
我们依次来分析下,通过这三部分内容SQL Server如何了解该列数据的内容分布的。
a、统计信息的总体属性项
该部分包含以下几列:
经过上面部分的数据,统计信息已经分析出该列数据的最近更新时间、数据量、数据长度、数据类型等信息值。
b、统计信息的覆盖索引项
All density:反映索引列的稠密度值。这是一个非常重要的值,SQL Server会根据这个评分项来决定该索引的有效程度。
该分值的计算公式为:density=1/表中非重复的行数。所以该稠密度值取值范围为:0-1。
该值越小说明该列的索引项选择性更强,也就说该索引更有效。理想的情况是全部为非重复值,也就是说都是唯一值,这样它的数最小。
举个例子:比如上面的例子该列存在91行,假如顾客不存在重名的情况下,那么该密度值就为1/91=0.010989,该列为性别列,那么它只存在两个值:男、女,那么该列的密度值就为0.5,所以相比而言SQL Server在索引选择的时候很显然就会选择ContactName(顾客名字)列。
简单点讲:就是当前索引的选择性高,它的稠密度值就小,那么它就重复值少,这样筛选的时候更容易找到结果值。相反,重复值多选择性就差,比如性别,一次过滤只能过滤掉一半的记录。
Average Length:索引的平均长度。
Columns:索引列的名称。这里因为我们是非聚集索引,所以会存在两行,一行为ContactName索引列,一行为ContactName索引列和聚集索引的列值CustomerID组合列。希望能明白这里,索引基础知识。
通过以上部分信息,SQL Server会知道该部分的数据获取方式那个更快,更有效。
c、统计信息的直方图信息
我们接着分析第三部分,该列直方图信息,通过这块SQL Server能直观“掌控”该列的数据分布内容,我们来看
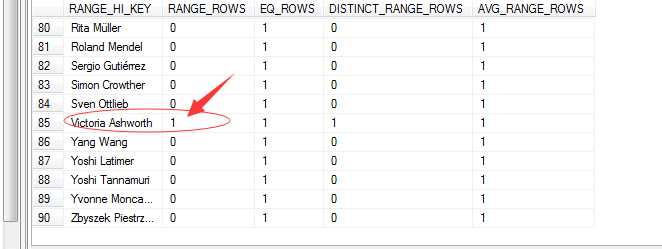
经过最后一部分的描述,SQL Server已经完全掌控了该表中该字段的数据内容分布了。想获取那些数据根据它就可以从容获取到,并且统计信息是排序了的。
所以当我们每次写的T-SQL语句,它都能根据统计信息评估出要获取的数据量多少,并且找到最合适的执行计划来执行。
我也相信经过上面三部分的分析,关于文章开篇我们提到的那个关于‘K’和‘Y’的问题会找到答案了,这里不解释了。
当然,如果数据量特别大,统计信息的维护也会有小小的失误,而这时候就需要我们来站出来及时的弥补。
创建统计信息
通过上面的介绍,其实我们已经看到了统计信息的强大作用了,所以对于数据库来说它的重要性就不言而喻了,因此,SQL Server会自动的创建统计信息,适时的更新统计信息,当然我们可以关闭掉,但是我非常不建议这么做,原因很简单:No Do No Die...
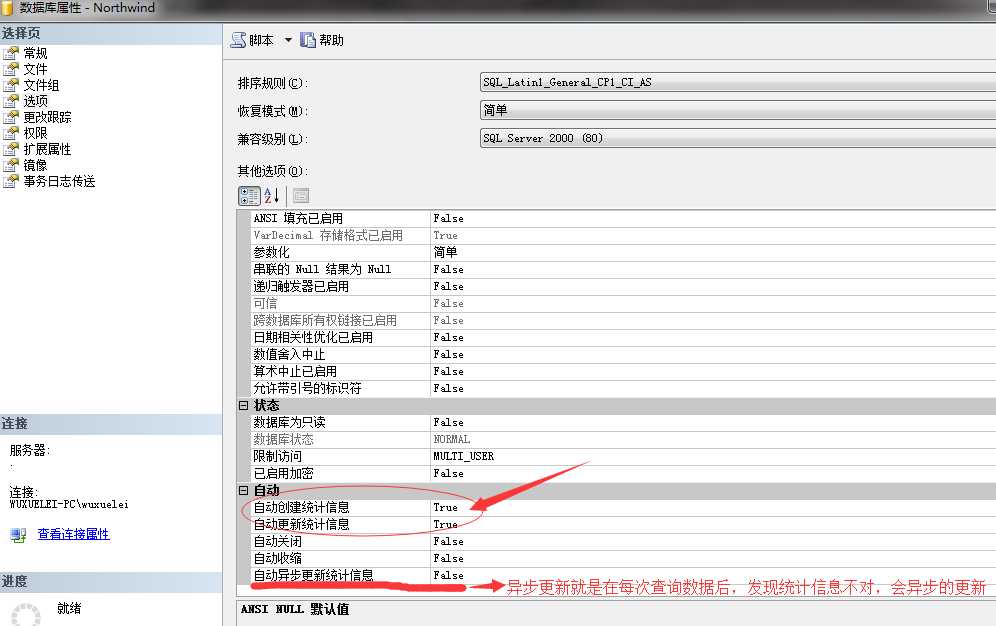
这两项功能默认是开启的,也就是说SQL Server会自己维护统计信息的准确性。
在日常维护中,我们大可不必要去更改这两项,当然也有比较极端的情况,因为我们知道更新统计信息也是一个消耗,在非常的大的并发的系统中需要关掉自动更新功能,这种情况非常的少之又少,所以基本采用默认值就可以。
在以下情况下,SQL Server会自动的创建统计信息:
1、在索引创建时,SQL Server会自动的在索引列上创建统计信息。
2、当SQL Server想要使用某些列上的统计信息,发现没有的时候,这时候会自动创建统计信息。
3、当然,我们也可以手动创建。
比如,自动创建的例子
select * into CustomersStats from Customers sp_helpstats CustomersStats
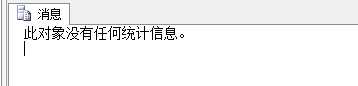
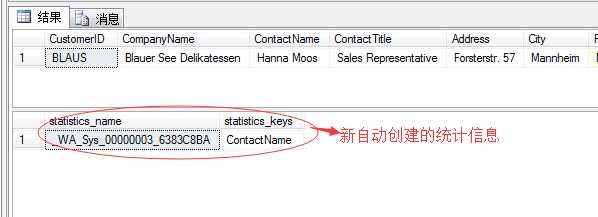
来添加一个查询语句,然后再查看统计信息
select * from CustomersStats where ContactName=‘Hanna Moos‘ go sp_helpstats CustomersStats go
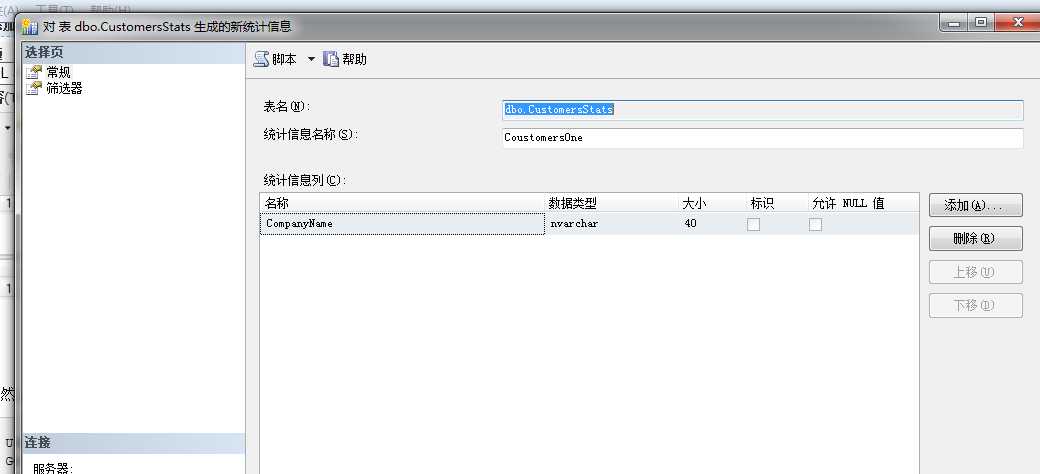
当然,我们也可以根据自己的情况来手动创建,创建脚本如下
USE [Northwind] GO CREATE STATISTICS [CoustomersOne] ON [dbo].[CustomersStats]([CompanyName]) GO
SQL Server也提供了GUI的图像化操作窗口,方便操作
在以下情况下,SQL Server会自动的更新统计信息:
1、如果统计信息是定义在普通的表格上,那么当发生以下任一种的变化后,统计信息就会被触发更新动作。
2、临时表上也可以有统计信息。这也是很多情况下采用临时表优化的原因之一。其维护策略基本和普通表格一样,但是表变量不能创建统计信息。
当然,我们也可以手动的更新统计信息,更新脚本如下:
UPDATE STATISTICS Customers WITH FULLSCAN
文章写的有点糙....但篇幅已经稍长了....先到此吧...后续我再补充一部分关于统计信息的内容。
关于调优内容太广泛,我们放在以后的篇幅中介绍,有兴趣的可以提前关注。
参考文献
标签:
原文地址:http://www.cnblogs.com/vincent2010/p/4771734.html