标签:
Lucene保存了从Index到Segment到Document到Field一直到Term的正向信息,也包括了从Term到Document映射的反向信息,还有其他一些Lucene特有的信息。下面对这三种信息一一介绍。
正向信息:
index-->segments(segment,.gen,segment_N)-->Field(fnm,fdx,fdt)-->Term(tvx,tvd,tvf)segments.gen和segments_N保存的是段(segment)的元数据信息(metadata),其实是每个Index一个的,而段的真正的数据信息,是保存在域(Field)和词(Term)中的.
段的元数据信息(segment_N):
我们要打开一个索引的时候,我们必须要选择一个来打开,那如何选择哪个segments_N呢?
Lucene采取以下过程:
- 其一,在所有的segments_N中选择N最大的一个。基本逻辑参照SegmentInfos.getCurrentSegmentGeneration(File[] files),其基本思路就是在所有以segments开头,并且不是segments.gen的文件中,选择N最大的一个作为genA。
- 其二,打开segments.gen,其中保存了当前的N值。其格式如下,读出版本号(Version),然后再读出两个N,如果两者相等,则作为genB。
如下图是segments_N的具体格式:
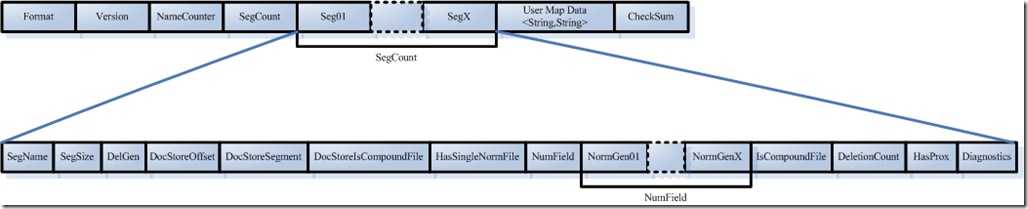
- 索引文件格式的版本号。
- 由于Lucene是在不断的开发中,因而不同的版本的lucene,其索引文件的格式也不尽相同,于是规定一个版本号。
- lucene2.1该值为-3,lucene2.9该值为-9.
- 当用某个版本号的indexReader读取了另一个版本号生成的索引的时候,会因为值不同而报错。
- 索引的版本号,记录了indexWriter将修改提交到索引文件中的次数。
- 其初始值大多数情况下从索引文件里面读出,仅仅在索引开始创建的时候,被赋予当前的时间,已取得一个唯一值。
- 其职改变在indexWriter.commit-->indexWriter.startCommit-->segmentinfos.prepareCommit-->segmentinfos.write-->writeLong(++version)
- 其初始值之所最初一个时间,因为我们不关心indexwriter将修改提交到索引的具体次数,而更关心到底那个是最新的(最后被修改的)。indexwriter中常比较自己的version和索引文件中的version是否相同来判断此indexReader被打开后,还有没有被indexWriter更新。
- 是下一个新段(segment)的段名。
- 所有属于同一个段的索引文件都以段名作为文件名,一般为_0.xxx,_0.yyy......
- 新生成的段的段名一般为原有最打断名+1.
- 如下索引,nameCount读出来的是2,说明是新的段位_2.xxx,_2.yyy.
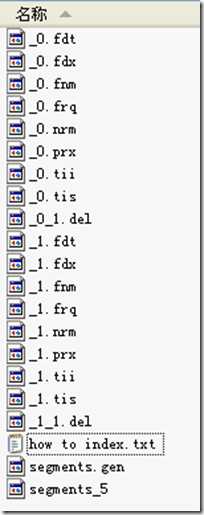
- 段的个数。
- 如上图,segcount=2
- segName:段名,所有属于同一个段的文件都有以段名作为文件名。eg:上图第一个段名为“_0”,第二个段名为“_1”
- segSize:此段中包含的文档数;a,然而此文档数十包括已经被删除又没有optimize的文档,因为在optimize之前,lucene的断中包含了所有被索引的文档,而被删除的文档是保存在.del文件中。在搜索过程中读到了被删除的文档,然后再用.del中的标志,将这篇文档进行过滤。
- 下面的代码生成了上面的索引图,可以看出索引了两篇文档形成了_0段,然后又删除了其中的一篇形成了_0_1.del,又索引了两篇文档形成了_1段,
形成了_1_1.del,因而在两个断中,此值都为2。
IndexWriter writer = new IndexWriter(FSDirectory.open(INDEX_DIR), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED);
writer.setUseCompoundFile(false);
indexDocs(writer, docDir);//docDir中只有两篇文档
//文档一为:Students should be allowed to go out with their friends, but not allowed to drink beer.
//文档二为:My friend Jerry went to school to see his students but found them drunk which is not allowed.
writer.commit();//提交两篇文档,形成_0段。
writer.deleteDocuments(new Term("contents", "school"));//删除文档二
writer.commit();//提交删除,形成_0_1.del
indexDocs(writer, docDir);//再次索引两篇文档,Lucene不能判别文档与文档的不同,因而算两篇新的文档。
writer.commit();//提交两篇文档,形成_1段
writer.deleteDocuments(new Term("contents", "school"));//删除第二次添加的文档二
writer.close();//提交删除,形成_1_1.del
- .del文件的版本号
- 在lucene中,在optimize之前,删除的文档是保存在.del文件中的。
- 使用indexReader和indexWriter进行删除文档:IndexReader.deleteDocuments(Term term)是用IndexReader删除包含此词(Term)的文档。使用indexWriter底层也是使用indexReader实现的。IndexWriter.deleteDocument(Term t)...
- DelGen是每当indexWriter向索引文件中提交删除操作的时候,+1,并生成新的.del文件。
IndexWriter.commit()
-> IndexWriter.applyDeletes()
-> IndexWriter$ReaderPool.release(SegmentReader)
-> SegmentReader(IndexReader).commit()
-> SegmentReader.doCommit(Map)
-> SegmentInfo.advanceDelGen()
-> if (delGen == NO) {
delGen = YES;
} else {
delGen++;
}
生成新的.del文件:
一个段(Segment)包含多个域,每个域都有一些元数据信息,保存在.fnm文件中,.fnm文件的格式如下:
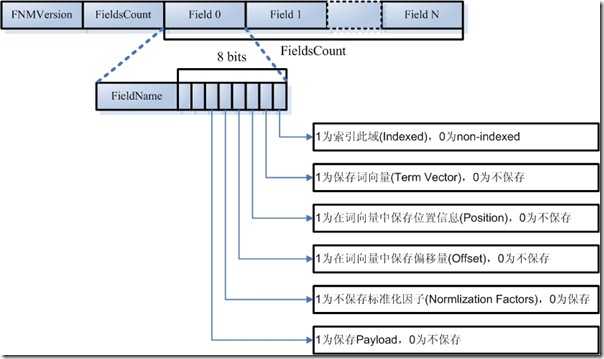
- FNMVersion
- 是fnm文件的版本号,对于Lucene 2.9为-2
- FieldsCount
- 一个数组的域(Fields)
- FieldName:域名,如"title","modified","content"等。
- FieldBits:一系列标志位,表明对此域的索引方式
- 最低位:1表示此域被索引,0则不被索引。所谓被索引,也即放到倒排表中去。
- 仅仅被索引的域才能够被搜到。
- Field.Index.NO则表示不被索引。
- Field.Index.ANALYZED则表示不但被索引,而且被分词,比如索引"hello world"后,无论是搜"hello",还是搜"world"都能够被搜到。
- Field.Index.NOT_ANALYZED表示虽然被索引,但是不分词,比如索引"hello world"后,仅当搜"hello world"时,能够搜到,搜"hello"和搜"world"都搜不到。
- 一个域出了能够被索引,还能够被存储,仅仅被存储的域是搜索不到的,但是能通过文档号查到,多用于不想被搜索到,但是在通过其它域能够搜索到的情况下,能够随着文档号返回给用户的域。
- Field.Store.Yes则表示存储此域,Field.Store.NO则表示不存储此域。
- 倒数第二位:1表示保存词向量,0为不保存词向量。
- Field.TermVector.YES表示保存词向量。
- Field.TermVector.NO表示不保存词向量。
- 倒数第三位:1表示在词向量中保存位置信息。
- Field.TermVector.WITH_POSITIONS
- 倒数第四位:1表示在词向量中保存偏移量信息。
- Field.TermVector.WITH_OFFSETS
- 倒数第五位:1表示不保存标准化因子
- Field.Index.ANALYZED_NO_NORMS
- Field.Index.NOT_ANALYZED_NO_NORMS
- 倒数第六位:是否保存payload
lucene的索引文件2
标签:
原文地址:http://www.cnblogs.com/mggwct/p/4773122.html