标签:
从我第一次听到Nosql这个概念到如今已经走过4个年头了,但仍然没有具体的去做过相应的实践。最近获得一段学习休息时间,购买了Nosql技术实践一书,正在慢慢的学习。在主流观点中,Nosql大体分为4类,键值存储数据库,列存储数据库,文档型数据库,图形数据库。今天主要快速的浏览了文档型数据库中目前市场占有率的最高的MongoDB数据库。记得初次见到和关注这个数据库还是我刚来上海的时候,公司将该数据库作为新建的项目管理系统的后台数据库,当时还是很向往的,只是无缘参与那个项目,也就一直没有和该数据库打上交道。接下来简单的介绍下该数据库的基本原理和相关应用,也算是巩固知识和加强记忆了。大体上快速学习分为两部分,第一部分为基础,第二部分为进阶。
首先,MongoDB不需要表结构,它是模式自由的(schema-free),例如{"welcome", "Shanghai"}, {"name", "bibi"}可以放到同一个集合中。那么它是如何在存储数据的呢?MongoDB在保存数据时会使用Bson的形式,一种json的二进制化形式,并把它与特定的Key进行关联。这样将非常便于程的扩展和维护,在需要增加新字段或者修改字段时只需要修改程序,而不需要修改数据库的架构,非常的方便。
其次,MongoDB原生的提供很强的伸缩性,对于web应用,当需要存储的数据不断增加时,我们将面对一个很大的问题,如何给数据存储模块扩容。在原有的数据存储模块架构中,往往需要通过购买功能更强大的机器,给数据库服务器升级,但这存在的问题是成本很高,同时升级也受限于当时硬件技术水平的。于此同时,由于实际web应用中,访问量并不是相似的,例如在各种活动期间,会出现各种特殊峰值,例如淘宝的11节的第1分钟的访问量都已达到千万级,而在平时这个值相对小很多。所有这时增加服务器在忙时可能仍然达不到目的,而闲时又会造成大量的浪费,所以伸缩性成为上成为web架构中的最重要的技术指标之一,这也是当前Nosql技术流行的主要原因。
最后,MongoDB还提供丰富的功能,包括支持辅助索引,支持MapReduce和其他聚合工具,并提供了分布式环境下的高可用,比如自动的在集群中增加和配置节点。
当然,MongoDB也不是万能的,实际上也存在一些不足。例如,不支持join查询和事务处理,数据也不是实时写入到磁盘的,同时存储数据时需要预留很大的空间。在实际项目中,需要根据实际的需要进行选择,当前很多主流网站均使用Sql+NoSql的形式构建数据库存储模块。
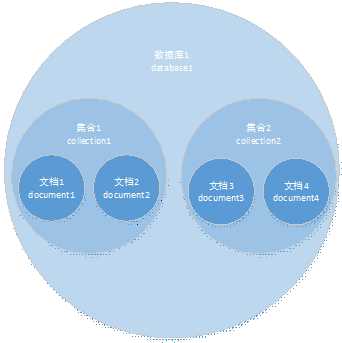
MongoDB中的文档document相当于Sql数据库中的一行记录;多个文档组成一个集合collection,相当于关系数据库的表;多个集合组合在一起,就是数据库database;一个数据库服务器可以有多个数据库实例。
|
操作类别 |
实例 |
备注 |
|
插入 |
j={name, "bibi"};t={x : 3}; db.things.save(j); db.things.save(t); db.things.find(); |
|
|
修改 |
Db.things.update({name,"mongo"}, {$set:{name:"mongo_new"}}); |
|
|
删除 |
Db.things.remove({name:"mongo_new"}); |
|
|
普通查询 |
var cursor = db.things.find(); while(cursor.hasNext()) printjson(cursor.next()); |
获得游标,遍历游标 |
|
Db.things.find().forEach(printjson) |
||
|
Var arr = db.things.find().toArray(); Arr[5]; |
||
|
条件查询 |
Db.things.find({x:4}, {j:true}).forEach(printjson); |
|
|
FindOne |
Printjson(db.things.findOne({name:"mongo"})); |
|
|
limit |
Db.things.find().limit(3); |
|
操作符 |
实例 |
备注 |
|
条件操作符 |
Db.collection.find({"field":{$gt:value}}); Db.collection.find({"field":{$lt:value}}); Db collection.find({"field":{$gte:value}}); Db.collection.find({"field":{$lte:value}}); |
Field>value Field<value Field>=value Field<=value |
|
$all |
Db.users.find({age:{$all:[6, 8]}}); |
必须满足[]内所有值 |
|
$exists |
Db.things.find({age:{$exists:true}}); Db.things.find({age:{$exists:false}}); |
查询存在age字段的记录 查询不存在age字段的记录 |
|
Null值的处理 |
Db.collection.find(age:null)} Db.collection.find(age:{$in:[null], $exists:true})} |
这儿要注意,在只用null作为判断条件是,还会把不包含age字段的记录找出来 |
|
$mod |
Db.collection.find({age:{$mod:[10, 1]}}) |
取模运算 |
|
$ne |
Db.things.find({x:{$ne:3}}); |
不等于 |
|
$in |
Db.users.find({age:{$in:[2,4,6]}}); |
包含 |
|
$nin |
Db.users.find({age:{$nin:[1,3]}}) |
不包含 |
|
$size |
{name:‘bibi‘, age:26, luck_number:[3,7,9]}, db.users.find({luck_number:{$size: 3}}) |
数组元素个数 |
|
正则表达式匹配 |
Db.users.find({name:{$not:/^B.*/}}); |
查询不匹配name=B*带头的记录 |
|
Javascript查询和$where查询 |
Db.collection.find({a:{$gt:3}}); Db.collection.find($where:"this.a>3"); Db.collection.find(this.a>3"); f=function(){return this.a>3} db.collection.find(f); |
查询a大于3的数据 |
|
count |
Db.users.find().count(); Db.user.find().skip(10).limit(5).count(); Db.user.find().skip(10).limit(5).count(true); |
查询记录条数 还是返回的所有记录数 加true也能限制数量 |
|
Skip |
Db.users.find().skip(3).limit(5) |
相当于limit(3, 5) |
|
sort |
Db.colletion.find().sort({age:1}); Db.colletion.find().sort({age:-1}); |
按升序进行排序 按降序进行排序 |
|
游标 |
For(var c = db.t3.find();c.hasNext();){ Printjson(c.next());} Db.t3.find().forEach(function(u){printjson(u);}); |
Map/Reduce这个概念已经存在了很多年,记得有个印度工程时通过做不同口味的番茄酱的理解风趣幽默的为妻子解释了这个概念,主体的意思就是分工然后汇总。在这里Map/Reduce相当于MySQL中的"group by",使用过程需要实现Map函数和Reduce函数。
|
函数名 |
实例 |
备注 |
|
前提条件 |
Db.students.insert({classid:1, age:14, name:‘Tom‘}) Db.students.insert({classid:2, age:27, name:‘Bibi‘}) |
插入班级1,2共8条记录. |
|
Map |
m=function(){emit(this.classid, 1)} |
Map函数必须调用emit(key, value)返回键值对,使用this访问当前待处理的Document. |
|
Reduce |
r=function(key, value){ var x =0; values.forEach(function(v){x+=v}); return x;} |
Reduce函数接受的参数类似Group效果,将Map返回的键值序列组合成{key, [value1, value2, value3..]}传递给reduce. |
|
Result |
Res=db.runcommand({ mapreduce:"students", map:m, reduce:r, out:"student_res" }); |
相当于分组聚合操作, 获得结果: {"_id": 1, "value":3} |
|
finalize |
Res=db.runcommand({ …(同上) finalize:f }); |
利用finalize()我们可以对reduce()的结果做进一步的处理。结果变为如下形式: {"classid": 1, "count":3} |
|
options |
Res=db.runcommand({ …(同上) Query:{age:{$lt:10}} }); |
可选项,例如过滤操作,只取age<10的数据。 |
MongoDB提供了多样性的索引支持,索引信息被保存在system.indexes中,且默认总是为_id创建的索引。
|
操作符 |
实例 |
备注 |
|
基础索引 |
Db.t3.ensureIndex({age:1}); Db.t3.getIndexes(); |
按升序排序的索引, 查看有哪些索引 |
|
Db.t3.ensureIndex({age:1}, {background:true}); |
当系统已有大量数据时,创建索引非常耗时,我们可以在后台执行 |
|
|
文档索引 |
Db.factories.insert({name:"SORY", addr:{city:"Shanghai", state:"China"}}); Db.factories.ensureIndex({addr:1}); |
索引可以是任何类型的字段,甚至文档。 注意索引建立的顺序。 |
|
组合索引 |
Db.factories.ensureIndex({"addr.city":1, "addr.state":1}); |
|
|
唯一索引 |
Db.users.ensureIndex({firstname:1, lastname:1}, {unique:true}); |
注意,如果建立索引所选字段的既有值有重复的,是无法建立唯一索引的。 |
|
强制使用索引 |
Db.t5.find({age:{<: 30}}).hint(name:1, age:1).explain(); |
|
|
删除索引 |
Db.t1.dropIndexes Db.t1.dropIndex({firstname:1}) |
删除t3表的所有索引 删除指定索引 |
标签:
原文地址:http://www.cnblogs.com/wanliwang01/p/4779405.html