标签:
Redis数据库是一种非关系型数据库,基于key/value对,运行时加载到内存,对value支持虚拟内存, 支持多种数据结构,支持持久化,以性能著称,可用于存储,缓存,消息队列等场景。主要介绍下Redis运行时维护的数据结构,以展示其工作方式。
1.总体设计。
首先,Redis没有MySQL那样的索引机制,因为其内建一个基于hash的字典,如下图:
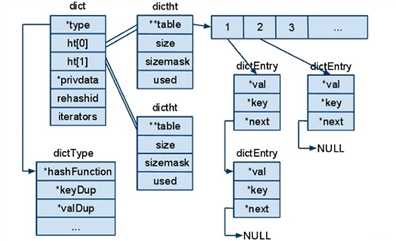
Redis 计算哈希值和索引值的方法如下:
# 使用字典设置的哈希函数,计算键 key 的哈希值 hash = dict->type->hashFunction(key); # 使用哈希表的 sizemask 属性和哈希值,计算出索引值 # 根据情况不同, ht[x] 可以是 ht[0] 或者 ht[1] index = hash & dict->ht[x].sizemask;
插入数据时,根据以上算出index,然后根据index值放入table表中相应位置即可。
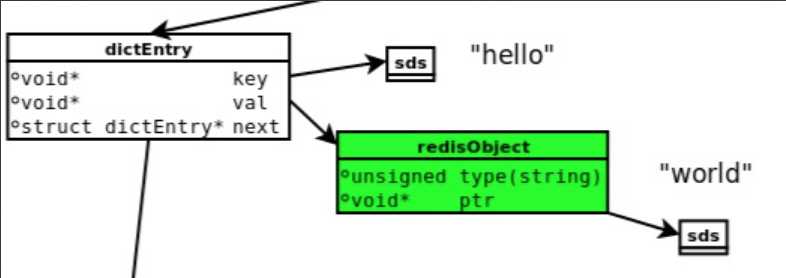
2. string类型
例如:Set hello world
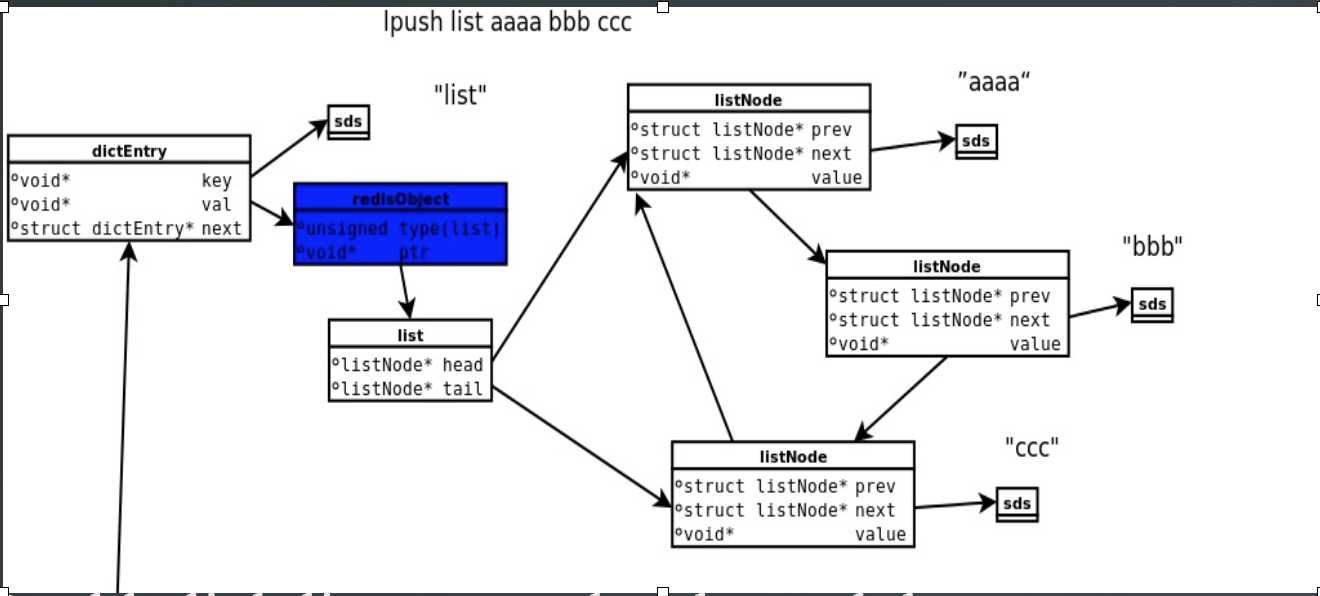
3. list类型
例如:Lpush list aaaa bbb ccc
4. hash类型
例如:Hset test hello world
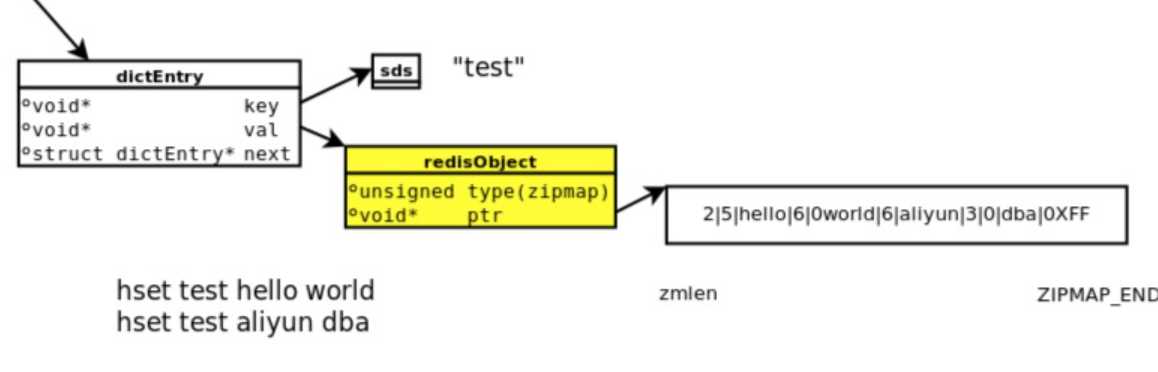
注:新建一个hash对象时开始是用zipmap(又称为small hash)来存储的。这个zipmap其实并不是hash table,但是zipmap相比正常的hash实现可以节省不少hash本身需要的一些元数据存储开销。尽管zipmap的添加,删除,查找都是O(n),但是由于一般对象的field数量都不太多。所以使用zipmap也是很快的,也就是说添加删除平均还是O(1)。如果field或者value的大小超出一定限制后,Redis会在内部自动将zipmap替换成正常的hash实现(一个key对应一个hash表)。
参考:
http://www.slideshare.net/iammutex/redis-9948788
http://blog.nosqlfan.com/html/3525.html?ref=rediszt
http://redisbook.com/preview/dict/hash_algorithm.html
标签:
原文地址:http://www.cnblogs.com/renzherushe/p/4779390.html