标签:
字符串的匹配的算法一直都是比较基础的算法,我们本科数据结构就学过了严蔚敏的KMP算法。KMP算法应该是最高效的一种算法,但是确实稍微有点难理解。所以打算,开这个博客,一步步的介绍4种匹配的算法。也是《算法导论》上提到的。我会把提到的四种算法全部用c/c++语言实现。提供参考学习。下图的表格,介绍了各个算法的处理时间和匹配时间。希望我写的比较清楚。如果不理解的,或者不对的,欢迎留言。
| 算法 | 预处理时间 | 匹配时间 |
| 朴素算法 | 0 | O((n-m+1)m) |
| Rabin-Karp | ⊙(m) | O((n-m+1)m) |
| 有限自动机算法 | O(m|∑|) | ⊙(n) |
| KMP(Knuth-Morris-Pratt) | ⊙(m) | ⊙(n) |
====BF算法(朴素的模式匹配)======================================================
介绍,上面这四个算法之前,和所有的教材一下,先介绍一下BF算法吧(暴力算法)。
它的思路很简单:把每个字符串都拿来做对比。时间复杂度是O(m*n)。我们不妨先看看代码:
1 char* strStr(const char* str,const char* target) 2 { 3 if(!*target) return str; 4 char *p1 = (char *)str; 5 6 while(*p2) 7 { 8 char *p1begin = p1; 9 char *p2 = (char *)target; 10 while(*p1 && *p2 && (*p1 == *p2)) 11 { 12 p1++; 13 p2++; 14 } 15 if(!*p2) return p1begin; 16 } 17 return NULL; 18 }
图解:
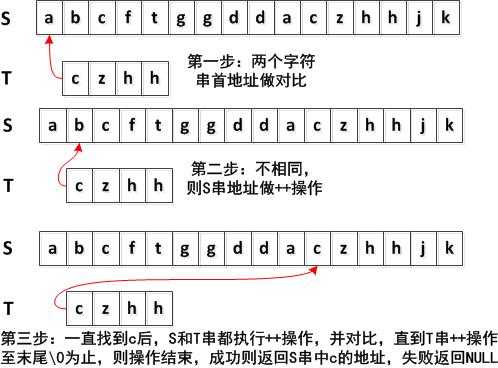
上图是我通过上面的代码画的一张偏于理解的图:第10行~14行是重点代码,为别进行++的操作,做对比,并且指针一直往后指。直到T串操作完成。最后判断是否T串是否已经走到末尾,如果已经走到末尾,代表了S串中包含了T串的内容,则返回保存的指针。
该算法的时间复杂度:两个while循环,所以O(m*n)。
BF算法是属于朴素算法的,算法导论中对朴素算法的伪代码是这样的:
1 n=T.length 2 m=P.lenth 3 for s = 0 to n-m 4 if P[1...m] == T [s+1...s+m] 5 print "pattern occurs with shift"s
什么 意思?
其实他只要对比n-m+1次即可。我们以上图的图作为例子。n-m=12,for循环从0~12只需要对比13次,即(n-m+1),如果第十三次都不成功,说明S串中没有T,直接返回NULL,他的时间复杂度是O(n-m+1),但是如果存在,并且在最后一位,那么他的时间复杂度就是O((n-m+1)*m),找到以后,还要进行m次对比,也就是两个while循环。
因此,我得出结论,BF算法应该是朴素算法里的一种。我们把这类的算法都成为朴素的模式匹配算法。
当然,如果模式T,所有的字符都不同,则有没有方法能够将朴素算法降到O(n),答案是肯定有的。(另外说一句,他们的时间复杂度都很好计算,如果不会的话,就去看看简单的参考书)。
1 int strStr1(const char* str, const char* target) 2 { 3 for(i = 0,j = 0; i != n; i++) 4 { 5 if(str[i] == target[j]) 6 { 7 j++; 8 } 9 else 10 { 11 j = 0; 12 } 13 if(j == m) 14 return true; 15 } 16 }
这道题是算法导论第三版的32章32.1.2的题目,但是我觉得这题目要考虑一点,如果我要返回的是S串中在什么位置,也就是想要返回一个S串中的指针,上面的方法显然是不行的。因为他只是返回:存不存在这个串。
那如何改进呢?
char* strStr1(const char* str, const char* target) { int i, j; int n = strlen(str); int m = strlen(target); char *p1 = (char*)str; for (i = 0, j = 0; i != n; i++) { if (str[i] == target[j]) { j++; } else { j = 0; } if (j == m) return (p1+i-j+1);//返回该位置的地址 } }
====Rabin-Karp=================================================
关于Rabin-Karp算法,会比较复杂。因为涉及到了一些数学上的知识,用到了一些进制的转换。也扯到了模等。我觉得要理解他,如果全凭看算导上面的东西,肯定会把自己弄晕的。我们先来看一篇博文(点击跳转),之后,我们找道题目练练手(poj 1200)。答案在后面给出:
Rabin-Karp 字符串搜索算法 是一个相对快速的字符串搜索算法,它所需要的平均搜索时间是O(n).这个算法是建立在使用散列来比较字符串的基础上的。 Rabin-Karp算法在字符串匹配中其实也不算是很常用,但它的实用性还是不错的,除非你的运气特别差,最坏情况下可能会需要O((n-m)*m)的运行时间(关于n,m的意义请看上篇)。平均情况下,还是比较好的。 朴素的字符串匹配算法为什么慢?因为它太健忘了,前一次匹配的信息其实可以有部分可以应用到后一次匹配中的,而朴素的字符串匹配算法只是简单的把这个信息扔掉,从头再来,因此,浪费了时间。好好的利用这些信息,自然可以提高运行速度。 这个算法不是那么容易说清楚,我举一个例子说下(看算法导论看到的例子)。 我们用E来表示字母表的字母个数,这个例子字母表如下:{0,1,2,3,4,5,6,7,8,9},那么E就是10,如果采用小写英文字母来做字母表,那么E就是26,类此。 由于完成两个字符串的比较需要对其中包含的字符进行检验,所需的时间较长,而数值比较则一次就可以完成,那么我们首先把模式(匹配的字串)转化成数值(转化成数值的好处不仅仅在此)。在这个例子里我们可以把字符0~9映射到数字0~9。比如,”423″,我们可以转化成3+E*(2+E*4)),这样一个数值,如果这个值太大了,我们可以选一个较大的质数对其取模,模后的值作为串的值。 这边处理好了,那么接下来转换被匹配的字符串,取前m个字符,如上述操作对其取值,然后对该值进行比较即可。 若不匹配,则继续向下寻找,这时候该如何做呢?比如模式是”423″,而父串是”324232″;第一步比较423跟324的值,不相等,下一步应该比较423跟242了,那么我们这步如何利用前一步的信息呢?首先我们把324前去300,然后在乘以E(这里是10),在加上2不就成了242了么?用个式子表示就是新的值a(i+1)=(E(a(i)-S[i])*h-S[S+M])) MOD p,p是我们选取的大质数,S[i]表示父串的第i个字符,而a(i)表示当前值,本例中就是324,h表示当前值最高位的权值,比如,324,则h=100,就是3这个位的权值,形式化的表示就是h=(E^m-1)MOD p。当然拉,由于采用了取模操作,当两者相等时,未必是真正的相等,我们需要进行细致的检查(进行一次朴素的字符串匹配操作)。若不相等,则直接可以排除掉。继续下一步。
答案:

#include <stdio.h> #include <string.h> char str[1000000]; bool hash[16000000] = {false}; int ansi[256] = {0}; int main(){ int N, NC, ans = 0; scanf("%d%d%s",&N, &NC, str); for(char *s = str; *s; ++s){ //*s 不是 s ansi[*s] = 1; //如果字母出现过,赋值为1 } int cnt = 0; for(int i = 0; i < 256; ++i){ if(ansi[i]) ansi[i] = cnt++; //从0开始编号 } int len = strlen(str); for(int i = 0; i < len - N + 1; ++i){ int key = 0; for(int j = 0; j < N; ++j){ key = key * NC + ansi[str[i + j]]; //转换成NC进制 //printf("%d\n",ansi[str[i + j]]); } //printf("key=%d\n",key); if( !hash[key] ){ ans++; hash[key] = true; } } printf("%d\n",ans); return 0; }
如果你认认真真的做了,那肯定对该算法有了一些简单的理解。然后我们再去分析《算导》上的伪代码,以及一些知识点。我们先来看算导上的图。

31415的模是7,14152的模是8,67399的模也是7,但是,这两个数并不是相同的数,因此,他是一个伪命中点。模的计算机步骤在图C中已经写的很清楚了,不必多费口舌。但是当我们遇到两个相同的mod的时候,有必要去对比,判断他是否是和子串相同的。如果相同,则命中,判断他的串(值)是否相同。相同,则真命中,否则为伪命中。
他预处理时间为o(m),原因是他要将各个数的转化为模(下有伪代码中可看出)需要有一段时间,转化的时间是o(m)。之后,只要对比n-m+1次即可。如果两个数相同,则进行m次匹配。因此他最坏的时间复杂度是o(m*(n-m+1))。
我们来看看伪代码:
n = len(T); m = len(p); h = d^(m-1)mod q; //表示进位 p = 0; t0 = 0; for i 1 to m //m次预处理时间 p = (d*p+P[I]) mod q; t0 = (d*t0+T[I])mod q; for i 0 to n-m //从串S里面开始逐个搜索 if p==ti else ts+1 = d(ts-T[S+1]h) + T[S+M+1]mod q //比较重要的一步。获取下一个mod
===================
注:有限自动机算法、KMP请关注下。转载请注明出处。
4种字符串匹配算法:BS朴素 Rabin-karp 有限自动机 KMP(上)
标签:
原文地址:http://www.cnblogs.com/yusenwu/p/4771993.html
