标签:
------Java培训、Android培训、iOS培训、.Net培训期待与您交流! -------
如下图所示,排序有内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。
我们通常所说八大排序是指的内部排序。
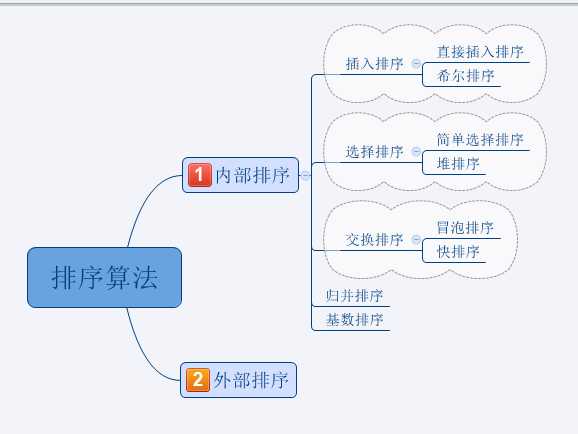
在实际的编写代码的过程中,如果需要对数组进行排序,简单的一个函数Array.sort()就能搞定,那么这些排序算法的意义何在呢?了解算法的过程其实是对于编程思路的加深理解,触类旁通进一步提升我们用代码解决问题的能力。算法的优化和衍伸是无穷尽的,作为新手我们只需要了解一些经典的算法,着重深入理解其中的典型就行了,一味的追求大而全反而会让自己理解不了,浪费时间的同时也会充满挫败感。个人对插入排序、选择排序、冒泡排序、快排序在这里做一个总结,在完全掌握这几类排序算法之后再学习理解其他的排序算法。
1、直接插入排序
插入排序的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。其具体步骤参见代码及注释。

1 /** 2 * 插入排序 的思路: 3 * 1、从第一个元素开始,该元素可以认为已经被排序 4 * 2、取出下一个元素,在已经排序的元素序列中从后向前扫描 5 * 3、如果该元素(已排序)大于新元素,将该元素移到下一位置 6 * 4、重复步骤3,直到找到已排序的元素小于或者等于新元素的位置 7 * 5、将新元素插入到该位置中 8 * 6、重复步骤2 9 * 10 * @param numbers 要进行排序的数组 11 */ 12 13 public static void insertSort(int[] numbers) 14 { 15 int temp,j; 16 for(int i=1;i<numbers.length;i++) 17 { 18 temp=numbers[i]; 19 for(j=i;j>0&&temp<numbers[j-1];j--) 20 numbers[j]=numbers[j-1]; 21 numbers[j]=temp; 22 } 23 24 }
2、选择排序
对待排序的记录序列进行n-1遍的处理,第1遍处理是将L[1..n]中最小者与L[1]交换位置,第2遍处理是将L[2..n]中最小者与L[2]交换位置,......,第i遍处理是将L[i..n]中最小者与L[i]交换位置。这样,经过n-1遍处理之后,前n-1个记录的位置就已经按从小到大的顺序排列好了,自然最后一个就是最后的位置,所有的位置也就按从小到大的顺序排列好了。
1 /** 2 * 选择排序 3 * 1、在未排序序列中找到最小元素,存放到排序序列的起始位置 4 * 2、再从剩余未排序元素中继续寻找最小元素,然后放到排序序列末尾。 5 * 3、 以此类推,直到所有元素均排序完毕。 6 * 7 * @param numbers 要进行排序的数组 8 */ 9 public static void selectSort(int[] numbers) 10 { 11 long start,end; //计时用,算程序的耗时 12 int minIndex; 13 start=System.nanoTime(); 14 for(int i=0;i<numbers.length-1;i++) 15 { 16 minIndex=i; 17 for(int j=i+1;j<numbers.length;j++) 18 { 19 if(numbers[j]<numbers[minIndex]) 20 { 21 minIndex=j; //记录本次循环中数据最小的脚标 22 } 23 } 24 if(minIndex!=i) //如果不相等则说明需要进行交换,相等说明当前项就是需要放到最前面的数,进行比较判断避免不必要的交换 25 { 26 swap(numbers,minIndex,i); 27 } 28 } 29 end=System.nanoTime(); 30 System.out.println("2、选择排序,耗时:"+(end-start)); 31 }
上面的代码中用到了一个交换函数swap,第一个参数是数组,第二、三个参数是要交换的元素的脚标。函数的功能是实现两个位置的元素互换位置。
3、冒泡排序
最大的元素会如同气泡一样移至右端,其利用比较相邻元素的方法,将大的元素交换至右端, 所以大的元素会不断的往右移动,直到适当的位置为止。
1 /** 2 * 冒泡法排序 3 * 1、比较相邻的元素。如果第一个比第二个大,就交换他们两个。 4 * 2、对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素就会是最大的数。 5 * 3、针对所有的元素重复以上的步骤,除了最后一个。 6 * 4、持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。 7 * @param numbers 要排序的数组 8 */ 9 public static void bubbleSort(int[] numbers) 10 { 11 long start,end; //计时用,算程序的耗时 12 start=System.nanoTime(); 13 for(int i=0;i<numbers.length-1;i++) 14 { 15 for(int j=0;j<numbers.length-1-i;j++) 16 { 17 if(numbers[j]>numbers[j+1]) 18 { 19 swap(numbers,j,j+1); 20 } 21 } 22 } 23 end=System.nanoTime(); 24 System.out.println("冒泡排序,耗时:"+(end-start)); 25 }
针对冒泡排序可以做一些简单的改进来提高效率,基本的气泡排序法可以利用旗标的方式稍微减少一些比较的时间,当寻访完阵列后都没有发生任何的交换动作,表示排序已经完成,而无需再进行之后的循环比较与交换动作。
1 /** 2 * 加入旗标的冒泡算法 3 * @param numbers 4 */ 5 public static void bubbleSortEx(int[] numbers) 6 { 7 boolean flag = true;//旗标 8 long start,end; //计时用,算程序的耗时 9 start=System.nanoTime(); 10 for(int i=0;i<(numbers.length-1)&&flag==true;i++) 11 { 12 flag=false; 13 for(int j=0;j<numbers.length-1-i;j++) 14 { 15 if(numbers[j]>numbers[j+1]) 16 { 17 swap(numbers,j,j+1); 18 flag=true;//如果本次循环中没有发生任何依次交换,则旗标flag的值就会为false;排序已经完成,这时外层循环条件也会不成立。避免了不必要的比较与交换 19 } 20 } 21 } 22 end=System.nanoTime(); 23 System.out.println("旗标改进过的冒泡排序,耗时:"+(end-start)); 24 }
4、快速排序
快排序是不稳定的排序算法,在实际情况下综合效率最好的排序算法,思路:1、先在待排序的一组数据中随便选一个数出来作为基数:key; 2、然后对这组数进行排序,比key小的放key的左边,比key大的放key的右边3、递归的来分组,在第二步中在将这个组数字,分成多个小组来排序
1 /* 2 * 快速排序的排序算法 3 * @param a 要排序的数组 4 * @param low 要排序的开始的索引值 5 * @param height 要排序的结束的索引值 6 */ 7 public static void quickSort(int a[], int low, int height) 8 { 9 if (low < height) 10 { 11 //调用算法,将数组分成大于关键元素和小于关键元素的两部分,获取返回的关键元素的位置 12 int result = partition(a, low, height); 13 //小于关键元素的部分递归调用快排序 14 quickSort(a, low, result - 1); 15 //大于关键元素的部分递归调用快排序 16 quickSort(a, result + 1, height); 17 } 18 } 19 20 //核心算法 21 //以关键元素将数组分成大于关键元素和小于关键元素的两部分, 22 //函数返回最终关键元素位于数组的位置 23 public static int partition(int a[], int low, int height) 24 { 25 //以第一个数组元素作为关键数据key; 26 int key = a[low]; 27 while (low < height) 28 { 29 //从height开始向前搜索,即由后开始向前搜索,找到第一个小于key的值,两者交换; 30 while (low < height && a[height] >= key) 31 height--; 32 a[low] = a[height]; 33 //从low开始向后搜索,即由前开始向后搜索,找到第一个大于key的值,两者交换; 34 while (low < height && a[low] <= key) 35 low++; 36 a[height] = a[low]; 37 //重复上面的两步直到low=height; 38 } 39 a[low] = key; 40 return low; 41 }
程序运行之后测试了一下,测试结果如下:
获取的随机数组为:
[ 92,86,71,6,57,50,78,58,96,50,46,42,38,27,67,41,57,52,73,41 ]
1、插入排序,耗时:6720
插入排序后的随机数组为:
[ 6,27,38,41,41,42,46,50,50,52,57,57,58,67,71,73,78,86,92,96 ]
2、选择排序,耗时:12960
选择排序后的随机数组为:
[ 6,27,38,41,41,42,46,50,50,52,57,57,58,67,71,73,78,86,92,96 ]
3、冒泡排序,耗时:17280
冒泡排序后的随机数组为:
[ 6,27,38,41,41,42,46,50,50,52,57,57,58,67,71,73,78,86,92,96 ]
旗标改进过的冒泡排序,耗时:17279
旗标冒泡排序后的随机数组为:
[ 6,27,38,41,41,42,46,50,50,52,57,57,58,67,71,73,78,86,92,96 ]
4、快排序,耗时:11520
快排序后的随机数组为:
[ 6,27,38,41,41,42,46,50,50,52,57,57,58,67,71,73,78,86,92,96 ]
这地方要注意,在应用同一个随机数组时,必须要新建备份,不能新建数组变量引用原来的随机数组,这样的话后面的排序的对象就是排序后的数组,这时因为引用类型的变量指向的是同一块堆内存!
以上的测试时间仅供参考,在项目中需要使用什么排序算法要根据实际情况来确定。各个排序算法的优劣在数据量不大的情况下不明显,一旦数据量大了之后差别就很大了。
标签:
原文地址:http://www.cnblogs.com/dengzhenyu/p/4781710.html
