标签:
理论上讲,只要足够大的RNN结构就能去生成任意复杂的序列结构。
但是在实际上,标准的RNN并不能有效的长期保存信息(这是由于类似HMM的结构,每次每个节点的信息如果始终经过同样的变换,那么会要么指数爆炸要么指数衰减,很快信息就会丢失)。也是由于它这个“健忘”的特点,这种RNN生成的序列很容易缺乏稳定性。这样的话,如果只能依赖上几步的结果去预测下一步,而又使用预测的新结果去预测再下一步,那么一旦出现了错误,系统就会很容沿着错误的方向走下去,而很少有机会能从之前的信息中把错误改正过来。
从这个角度讲,如果RNN能有一个“长久的记忆”的话,就会能在稳定性上有很好的效果,因为即使它不能确定当前几步是不是正确的,它也能够从更久之前的信息中得到一些“启发”来形成新的预测。
(有人可能会说:如果在训练RNN的时候本身就加上噪音或者其他方法让它在遇到奇怪的输入时能够依然保持稳定。但是我们依然觉得引进更好的记忆方法是更高效更有长久发展意义的举动。)
LSTM
LSTM是指Long Short-term Memory。这是一种在1997年搞出来的一种结构。
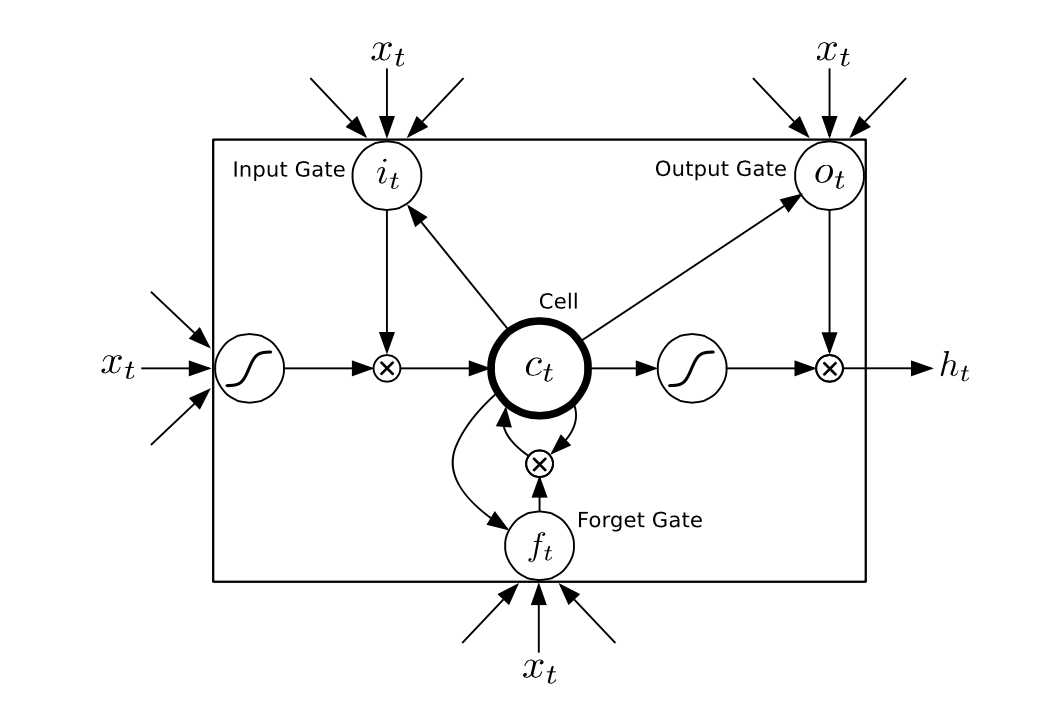
大概如图所示。
这种结构设计的非常精妙,包含了输入闸,遗忘闸和输出闸。这三种闸都是由特定的数据控制的,取值为{0, 1}(实际上会用一个sigmoid或者tanh函数来逼近,因为离散的0和1是不可求导的。)。其中输入闸,输出闸,遗忘闸和Cell都是和ht大小一样的{0,1}向量。
例如:
输入闸为0,遗忘闸为1,输出闸为1的时候这个LSTM单元就会不接受这次的输入数据而把上次的记录数据再次返回。(类似于只读)
输入闸为1,遗忘闸为0,输出闸为1的时候这个LSTM单元就会清空之前的“记忆”,只把这次来自Xt的信息传给ht,同时记录下来。(类似于刷新)
输入闸为1,遗忘闸为1,输出闸为0的时候这个LSTM单元会在记忆中加入这次的输入信息但是不会接着传递下去。(类似于存储)
等等。。。
如果没有太明白的话看一下他们之间的传递公式会比较好理解
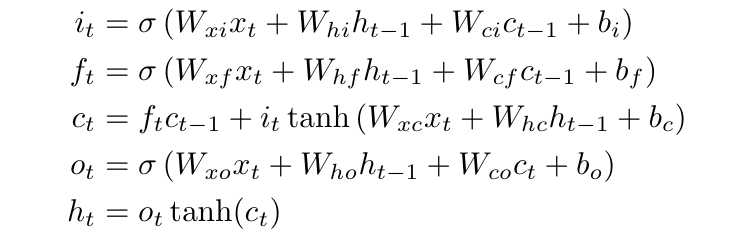
(其中σ(x)表示sigmoid函数)
其中W矩阵都是对角阵,表示每个闸的元素都是由对应维数的数据得到的,也就是说是互不干扰的!
原本的LSTM算法有一个自己定做的递降近似求法使得网络的权值能够在每一个时间点都进行更新,但是整个递降可以通过对时间的反向传播来完成,这也是这里用的方法。然而有个问题需要解决就是有些导数会变得非常的大,导致计算很困难。为了防止这种情况出现,本文的所有实验都将对整个网络的输入的求导停止在LSTM层(在sigmoid和tanh使用之前)。(这个之后再详细讲)
Recurrent Neural Network 学习笔记【二】RNN-LSTM
标签:
原文地址:http://www.cnblogs.com/lustralisk/p/RNN_2.html