标签:
个人遇到问题:
某个文件1,里面有字符创"360云盘"
用cat看
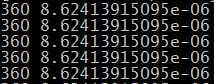
用less命令查看时如下:
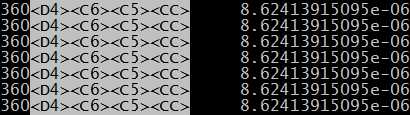
是用vim查看时如下:
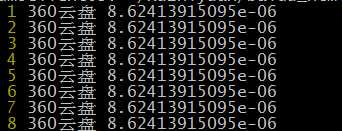
显然在vim是能够正确识别的,也就是说这3个命令查看文件时,编码方式是不一样的。
下面用file命令来查看本文件的编码方式如下:file 文件名
编码方式是:ISO-8859
这个是什么编码方式呢?它是中文编码方式,由于file命令不是取全文,而是截取文章前面部分进行一个判断的。ISO-8859-1 到ISO-8859-16,其实,也就认为是GB2312的汉字编码方式就行了。
这种不能够直接显示需要转为‘utf-8‘编码方式完成。
过程:
line="360云盘"
line=line.decode(‘GB2312‘).encode(‘utf-8‘)
这样就能够完成编码方式的转变了;那为什么不用‘ISO-8859‘,因为python里面说不是识别这种编码方式,改为GB2312就有效果了
另一个问题:
如果并不知道原来编码方式,而又想统一将输入的文件转为utf-8码,这种应用在爬虫中获取根据url获取html中常用;
这就需要用到python里面的一个模块叫chardet;下载地址如下:
http://download.csdn.net/detail/xzy_xuexi1/9085689
解压后通过如下代码即可:
import sys
sys.path.append(‘解压后的路径‘)
import chardet
print chardet.detect(“360云盘”)
-------
打印出来如下:

返回值是个字典型,key只有confidence就是表示可信度,encoding编码方式,使用时直接用chardet.detect(“360云盘”)[‘encoding’]
很方便就取得了字符的编码方式。
对于所有文件想转为utf-8则可用
line="360云盘"
line=line.decode(chardet.detect(line)[‘encoding’]).encode(‘utf-8‘)
这里还是出问题,因为chardet.detect(line)[‘encoding’]返回值是:

编码方式是EUC-TW,不知道是什么鬼,后来好搜一下,说
EUC-TW本来是台湾使用的其中一个汉字储存方法,以CNS11643字表为基础。但是台湾普遍使用大五码,EUC-TW甚少使用。
说白了也是一种汉字编码,这里Python是不支持这种编码的,没办法了,只能通过对EUC-TW,ISO-8859等汉字编码,通过判定后,让“GB2312”替换
也就是
if chardet.detect(line)[‘encoding’]==‘EUC-TW’ or chardet.detect(line)[‘encoding’]==‘ISO-8859.*’
line=line.decode(“GB2312”).encode(‘utf-8‘)
类似这种处理,这是鄙人简单的处理方式,有更好的方式望大家提供分享。
好了,到此,记录个人的遇到的这个问题,通过上述的方式成功解决了我的问题;
越学越感到自己文盲,努力前行,多多实践,多多解决实际问题。
标签:
原文地址:http://www.cnblogs.com/miner007/p/4788991.html