标签:
Memcached有两个核心组件组成:服务端(ms)和客户端(mc)。
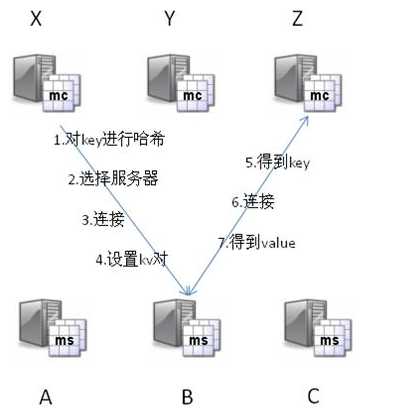
首先mc拿到ms列表,并对key做hash转化,根据hash值确定kv对所存的ms位置。
然后在一个memcached的查询中,mc先通过计算key的hash值来确定kv对所处在的ms位置。
当ms确定后,客户端就会发送一个查询请求给对应的ms,让它来查找确切的数据。
因为ms之间并没有护卫备份,也就不需要互相通信,所以效率较高。
Memcached Client目前有一下四种:
Memcached Client for Java,比 SpyMemcached更稳定、更早、更广泛;
SpyMemcached,比 Memcached Client for Java更高效;
XMemcached,比 SpyMemcache并发效果更好。
alisoft-xplatform-asf-cache阿里软件的架构师岑文初进行封装的。里面的注释都是中文的,比较好
Memcached的神奇来自两阶段哈希(two-stage hash)。
Memcached就像一个巨大的、存储了很多<key,value>对的哈希表。通过key,可以存储或查询任意的数据。
客户端可以把数据存储在多台memcached上。
当查询数据时,客户端首先参考节点列表计算出key的哈希值(阶段一哈希),进而选中一个节点;
客户端将请求发送给选中的节点,然后memcached节点通过一个内部的哈希算法(阶段二哈希),查找真正的数据(item)。
举个列子,假设有3个客户端1, 2, 3,3台memcached A, B, C:
Client 1想把数据"barbaz"以key "foo"存储。
Client 1首先参考节点列表(A, B, C),计算key "foo"的哈希值,假设memcached B被选中。
接着,Client 1直接connect到memcached B,通过key "foo"把数据"barbaz"存储进去。
Client 2使用与Client 1相同的客户端库(意味着阶段一的哈希算法相同),也拥有同样的memcached列表(A, B, C)。
于是,经过相同的哈希计算(阶段一),Client 2计算出key "foo"在memcached B上,然后它直接请求memcached B,得到数据"barbaz"。
各种客户端在memcached中数据的存储形式是不同的(perl Storable, php serialize, java hibernate, JSON等)。
一些客户端实现的哈希算法也不一样。但是,memcached服务器端的行为总是一致的。
最后,从实现的角度看,memcached是一个非阻塞的、基于事件的服务器程序。这种架构可以很好地解决C10K problem ,并具有极佳的可扩展性。
Memcached有一个很有特色的内存管理方式,为了提高效率,它使用预申请和分组的方式管理内存空间,
而并不是每次需要写入数据的时候去malloc,删除数据的时候free一个指针。
Memcached使用slab->chunk的组织方式管理内存。
整理内存以便重复使用最近的 memcached 默认情况下采用了名为 Slab Allocator 的机制分配、 管理内存。
在该机制出现以前,内存的分配是通过对所有记录简单地进行 malloc 和 free 来进行的。
但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比 memcached 进程本身还慢。
Slab Allocator 就是为解决该问题而诞生的。
下面来看看 Slab Allocator 的原理。
下面是 memcached 文档中的 slab allocator 的目 标:
the primary goal of the slabs subsystem in memcached was to eliminate memory fragmentation issues
totally by using fixedsize memory chunks coming from a few predetermined size classes.
也就是说, Slab Allocator 的基本原理是按照预先规定的大小, 将分配的内存分割成特定长度的块,以完全解决内存碎片问题。
Slab Allocation 的原理相当简单。
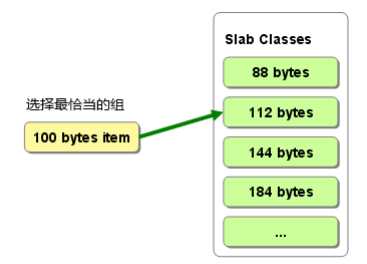
将分配的内存分割成各种尺寸的块( chunk), 并把尺寸相同的块分成组( chunk 的集合 slab class)(图 2.1)。

memcached给Slab分配内存空间,默认是1MB。
分配给Slab之后 把slab的切分成大小相同的chunk。
Chunk是用于缓存记录的内存空间。
Slab Class特定大小的chunk的组。
而且, slab allocator 还有重复使用已分配的内存的目的。
也就是说,分配到的内存不会释放,而是重复利用。
memcached 根据收到的数据的大小, 选择最适合数据大小的 slab(图 )。
memcached 中保存着slab 内空闲 chunk 的列表,根据该列表选择 chunk,然后将数据缓存于其中。
实际上, Slab Allocator 也是有利也有弊。 下面介绍一下它的缺点。
Slab Allocator 解决了当初的内存碎片问题, 但新的机制也给 memcached 带来了新的问题。
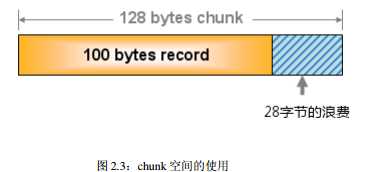
这个问题就是, 由于分配的是特定长度的内存,因此无法有效利用分配的内存。
例如, 将 100 字节的数据缓存到 128 字节的 chunk 中, 剩余的 28 字节就浪费了(图 )。
对于该问题目前还没有完美的解决方案, 但在文档中记载了比较有效的解决方案。
The most efficient way to reduce the waste is to use a list of size classes that closely matches (if that‘s at all
possible) common sizes of objects that the clients of this particular installation of memcached are likely tostore.
就是说,如果预先知道客户端发送的数据的公用大小, 或者仅缓存大小相同的数据的情况下, 只要使用适合数据大小的组的列表, 就可以减少浪费。
但是很遗憾,现在还不能进行任何调优, 只能期待以后的版本了。
但是, 我们可以调节 slab class的大小的差别。接下来说明 growth factor 选项。
memcached 在启动时指定 Growth Factor 因子(通过f选项), 就可以在某种程度上控制 slab 之间的差异。 默认值为 1.25。
但是,在该选项出现之前,这个因子曾经固定为 2, 称为“ powers of 2”策略。让我们用以前的设置,以 verbose 模式启动 memcached 试试看:
$ memcached f 2 vv
下面是启动后的 verbose 输出:
slab class 1: chunk size 128 perslab 8192
slab class 2: chunk size 256 perslab 4096
slab class 3: chunk size 512 perslab 2048
slab class 4: chunk size 1024 perslab 1024
slab class 5: chunk size 2048 perslab 512
slab class 6: chunk size 4096 perslab 256
slab class 7: chunk size 8192 perslab 128
slab class 8: chunk size 16384 perslab 64
slab class 9: chunk size 32768 perslab 32
slab class 10: chunk size 65536 perslab 16
slab class 11: chunk size 131072 perslab 8
slab class 12: chunk size 262144 perslab 4
slab class 13: chunk size 524288 perslab 2
可见,从 128 字节的组开始, 组的大小依次增大为原来的 2 倍。
这样设置的问题是, slab 之间的差别比较大,有些情况下就相当浪费内存。 因此,为尽量减少内存浪费,两年前追加了 growth factor这个选项。
来看看现在的默认设置( f=1.25) 时的输出(篇幅所限,这里只写到第 10 组):
slab class 1: chunk size 88 perslab 11915
slab class 2: chunk size 112 perslab 9362
slab class 3: chunk size 144 perslab 7281
slab class 4: chunk size 184 perslab 5698
slab class 5: chunk size 232 perslab 4519
slab class 6: chunk size 296 perslab 3542
slab class 7: chunk size 376 perslab 2788
slab class 8: chunk size 472 perslab 2221
slab class 9: chunk size 592 perslab 1771
slab class 10: chunk size 744 perslab 1409
可见, 组间差距比因子为 2 时小得多, 更适合缓存几百字节的记录。从上面的输出结果来看, 可能会觉得有些计算误差,这些误差是为了保持字节数的对齐而故意设置的。
将 memcached 引入产品, 或是直接使用默认值进行部署时,最好是重新计算一下数据的预期平均长度,调整 growth factor,以获得最恰当的设置。
内存是珍贵的资源, 浪费就太可惜了
1)memcached是缓存,所以数据不会永久保存在服务器上,其实数据不会真正从memcached中消失。
实际上memcached不会释放已分配的内存,记录超时后,客户端就无法再看见该记录,其存储空间即可重复使用。
2)Lazy Expiration:memcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。
这种技术被称为lazy(惰性)expiration。因此,memcached不会在过期监视上耗费CPU时间。
3)memcached会优先使用已超时的记录的空间,但即使如此,也会发生追加新记录时空间不足的情况,此时就要使用名为 Least Recently Used(LRU)机制来分配空间。
顾名思义,这是删除“最近最少使用”的记录的机制。因此,当memcached的内存空间不足时(无法从slab class 获取到新的空间时),
就从最近未被使用的记录中搜索,并将其空间分配给新的记录。
memcached 启动时通过“ M”参数可以禁止 LRU,如下所示:
$ memcached M m 1024
启动时必须注意的是, 小写的“ m”选项是用来指定最大内存大小的。不指定具体数值则使用默认值 64MB。
指定“ M”参数启动后,内存用尽时 memcached 会返回错误。 话说回来, memcached 毕竟不是存储器,而是缓存, 所以推荐使用 LRU。
不实现!
Memcached应该是应用的缓存层。它的设计本身就不带有任何冗余机制。
如果一个memcached节点失去了所有数据,您应该从数据源(比如数据库)再次获取到数据。您应该特别注意,您的应用应该可以容忍节点的失效。
不要写一些糟糕的查询代码,寄希望于memcached来保证一切!如果您担心节点失效会大大加重数据库的负担,那么您可以采取一些办法。
比如您可以增加更多的节点(来减少丢失一个节点的影响),热备节点(在其他节点down了的时候接管IP),等等。
不处理!:)
在memcached节点失效的情况下,集群没有必要做任何容错处理。如果发生了节点失效,应对的措施完全取决于用户。节
点失效时,下面列出几种方案供您选择:
忽略它! 在失效节点被恢复或替换之前,还有很多其他节点可以应对节点失效带来的影响。
把失效的节点从节点列表中移除。做这个操作千万要小心!在默认情况下(余数式哈希算法),客户端添加或移除节点,会导致所有的缓存数据不可用!
因为哈希参照的节点列表变化了,大部分key会因为哈希值的改变而被映射到(与原来)不同的节点上。
启动热备节点,接管失效节点所占用的IP。这样可以防止哈希紊乱(hashing chaos)。
如果希望添加和移除节点,而不影响原先的哈希结果,可以使用一致性哈希算法(consistent hashing)。
您可以百度一下一致性哈希算法。支持一致性哈希的客户端已经很成熟,而且被广泛使用。去尝试一下吧!
两次哈希(reshing)。当客户端存取数据时,如果发现一个节点down了,就再做一次哈希(哈希算法与前一次不同),重新选择另一个节点(需要注意的时,客户端并没有把down的节点从节点列表中移除,下次还是有可能先哈希到它)。如果某个节点时好时坏,两次哈希的方法就有风险了,好的节点和坏的节点上都可能存在脏数据(stale data)。
没有身份认证机制!
memcached是运行在应用下层的软件(身份验证应该是应用上层的职责)。
memcached的客户端和服务器端之所以是轻量级的,部分原因就是完全没有实现身份验证机制。
这样,memcached可以很快地创建新连接,服务器端也无需任何配置。
key的最大长度是250个字符。
需要注意的是,250是memcached服务器端内部的限制,如果您使用的客户端支持"key的前缀"或类似特性,
那么key(前缀+原始key)的最大长度是可以超过250个字符的。我们推荐使用使用较短的key,因为可以节省内存和带宽。
简单的回答:因为内存分配器的算法就是这样的。
详细的回答:Memcached的内存存储引擎(引擎将来可插拔...),使用slabs来管理内存。内存被分成大小不等的slabs chunks(先分成大小相等的slabs,然后每个slab被分成大小相等chunks,不同slab的chunk大小是不相等的)。chunk的大小依次从一个最小数开始,按某个因子增长,直到达到最大的可能值。
如果最小值为400B,最大值是1MB,因子是1.20,各个slab的chunk的大小依次是:slab1 - 400B slab2 - 480B slab3 - 576B ...
slab中chunk越大,它和前面的slab之间的间隙就越大。因此,最大值越大,内存利用率越低。Memcached必须为每个slab预先分配内存,因此如果设置了较小的因子和较大的最大值,会需要更多的内存。
还有其他原因使得您不要这样向memcached中存取很大的数据...不要尝试把巨大的网页放到mencached中。把这样大的数据结构load和unpack到内存中需要花费很长的时间,从而导致您的网站性能反而不好。
如果您确实需要存储大于1MB的数据,你可以修改slabs.c:POWER_BLOCK的值,然后重新编译memcached;或者使用低效的malloc/free。其他的建议包括数据库、MogileFS等。
标签:
原文地址:http://www.cnblogs.com/wihainan/p/4792353.html