标签:
我们在编写Nodejs程序时,经常会用到回调函数,在一个操作执行完成之后对返回的数据进行处理,我简单的理解它为异步编程。
如果操作很多,那么回调的嵌套就会必不可少,那么如果操作非常多,那么回调的嵌套就会变得让人无法忍受了。
我们知道的Promises就是问了解决这个问题而提出来的。然而,promises并不是一种新的功能,它只是一种新的写法,原来横向发展的回调函数,被排成了队竖向发展。
然而,Generator不同,它是一种新的解决方案。
文章中提到的所有代码都可以在这里找到源码:[查看源码]。
文章目录:
Generator函数是ES6提供的一种异步编程解决方案,语法行为与传统函数完全不同。
虽然现在各个浏览器对ES6的支持度已经越来越高,但是始终不完整,同时也为了兼容不同版本的浏览器实现,于是在一些情况下我们可能需要借助于一些ES6的转码器将ES6代码转化成ES5标准的代码。
1.1 babeljs-online
在边理解ES6,边写一些ES6相关的代码片段时,我喜欢用[babeljs-online]。用它我们可以不用在文本编辑器和命令行控制台之间来回切换,就可以写并且实时运行ES6的代码了。
它是长成这个样子的:
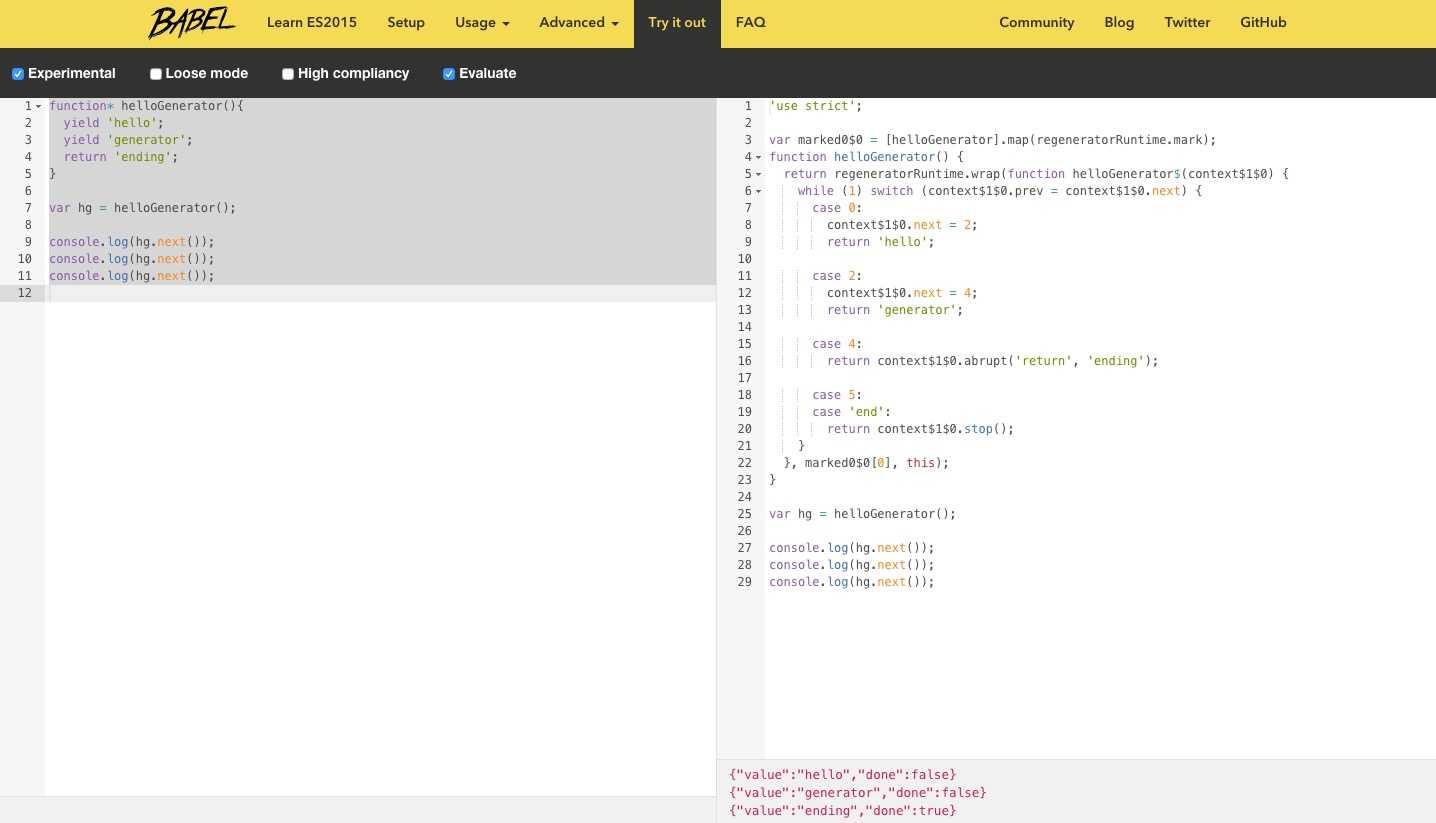
左边可以直接写ES6语法的代码,左下角提供实时的错误检测;
右边是实时编译成的ES5语法的代码,右下角可以输出console.log();
1.2 babel-node
当然我们也可以安装babel模块:
1 npm install --global babel
2 babel-node
这样就像在REPL中一样,我们可以写然后执行ES6代码了:
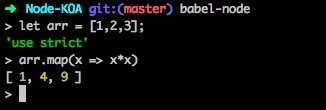
不过babel-node现在还不支持多行输入。
1.3 Traceur在线编辑器
Traceur同样是一个在线编辑器,在线的将ES6的代码转为ES5的代码。
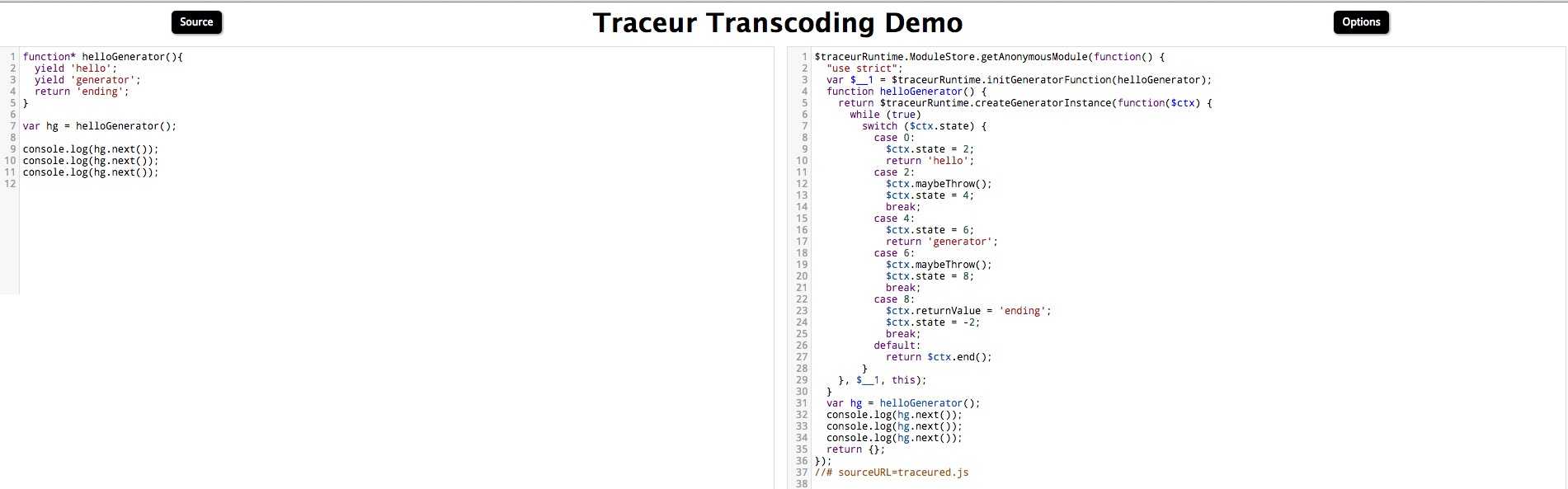
我比较喜欢babel的在线编辑器,有实时的语法错误提醒和运行结果的输出。一般情况下我选择它写一些代码片段。
通过一些简单的代码片段,我们来看一下Generator的含义和其中的一些要点。可以在[babeljs-online]中自行键入代码理解其含义。
这里有一个简单的例子:
 View Code
View Code查看运行结果:[helloGenerator代码片段]
2.1 yield语句的执行会暂停当前函数的执行并保存当前的堆栈,返回当前yield语句的值。
2.2 Generator函数与普通的函数不同,它只定义了遍历器,不会执行,每次调用这个遍历器的next方法,就从函数体的头部或者上一次停下来的地方开始执行,直到下一个yield语句为止。
yield语句就是暂停的标志,next方法遇到yield,就会暂停执行后面的操作,并将紧跟在yield后面的那个表达式的值,作为返回对象的value属性值。当下一次调用next方法时,再继续向下执行,知道遇到下一个yield语句。如果没有再遇到新的yield语句,就一直运行到函数结束,将return语句后面的表达式的值,作为value属性的值,如果该函数没有return语句,则value属性的值为undefined。
2.3 如果Generator函数不使用yield语句,这是它就变成了一个单纯地暂缓执行函数:
View Code查看运行结果:[暂缓执行的Generator函数]
2.4 yield语句不能用在普通函数中,否则会报错:
View Code查看运行结果:[在普通函数中使用yield语句报错的例子]
可以看到编辑器报错了。
2.5 yield语句本身没有返回值,或者说总是返回undefined。next方法可以带一个参数,该参数就会被当做上一个yield语句的返回值。但是由于next方法的参数表示上一个yield语句的返回值,所以第一次使用next方法时,不能带有参数,V8会直接忽略第一次使用next方法时的参数,只有从第二次使用next方法开始,参数才是有效的。
2.6 for...of循环可以自动遍历Generator函数,并且此时不需要再调用next方法:
View Code上面的代码会输出1,2,3,4并不会输出5,这是因为一旦next方法返回的对象的done属性为true,forof循环就会停止。
2.7 如果yield语句后面跟的是一个遍历器,需要在yield命令后面加上星号,表明它返回的是一个遍历器,这又叫yield*语句。
可以看下这个例子:
View Code查看运行结果:[yield*语句]
其实yield*语句就等同于在Generator函数内部部署一个for...of循环。
更多关于Generator函数的细节,严重推荐阅读阮一峰老师的ES6入门:[ES6 入门 - Generator]
虽然我们认识了Generator函数,知道它的含义,怎么使用。但是,为什么要使用Generator函数呢?它解决了什么问题?有什么优势?
我们从一个简单的[查找当前目录下得最大文件]的node程序开始,使用不同的解决方案来解决callback问题。
我们想写一个模块,然后在入口文件中调用它找到当前目录下的最大文件:
1 var findLargest = require(‘./readmaxnested‘);
2
3
4 //获取当前根目录下的最大的文件名称
5 findLargest(‘./‘,function(err,filename){
6 if(err) return console.log(err);
7 console.log(‘largest file was:‘, filename);
8 });
3.1 嵌套的解决方案
最先可以想到的方案:
1.读取当前文件夹下的所有文件;
2.获取到每个文件的stat,在确认IO操作都完成了的情况下比较文件大小;
3.过滤掉目录等 只比较文件;
4.通过callback返回最大的文件的filename。
实现起来应该是这个样子的:
View Code再正常和正确不过的方案了,但是其中会有一些问题。可以看到我们通过counter变量用于确保所有的IO操作都已完成时才开始文件的比较;通过errored变量来确保出错时只调用一次错误回掉。这样可以看到上面的这段程序在管理并行的操作的时候需要额外的小心。
3.2 模块化的解决方案
为了让代码的重用和测试变得简单些,我们可以稍稍改进下代码,提取出可充用的函数和方法:
View Code然而这还没有做出一些实质性的改进,可以看到,我们还是通过两个变量手动的管理了程序的流程。
3.3 使用async模块的解决办法
我们使用很流行的async模块来改写下我们的程序:
View Code这里比较关键的两个方法:
1.async.waterfall,它提供一系列的执行流程,通过一系列的回调data可以从一个函数传递到下一个函数;
2.async.map,可以并行的执行fs.stat然后返回一个结果数组;
可以看到async只提供了一个callback,我们不用在担心流程的控制和回调函数被调用的次数了。
3.4 使用promises的解决方案
promises是为了结局多重嵌套的回调而提出的一种解决办法。它不是新的语法功能,只是一种新的写法。它允许将回调函数的横向加载改成纵向加载。
我们来用promises写法改写下代码:
View CodeQ.all将会并行的获取到所有文件的stats并且返回一个数组。
其实代码一眼看上去是有些冗余的,原来的任务被promises包装了一下,看上去是好多的then,语义变得有些不清楚。
更多的关于promises和Q模块可以阅读:[Promises in nodejs with Q]
3.5 Generator的解决方案
我们使用ES6的Generator这个异步编程的解决方案,来改进代码:
View Code这里使用了co模块和Thunk函数,后面会有详细的解释,这里先跳过。
我们可以看到几行代码精巧的解决了问题,并且语义清晰,同时回调的问题也不复存在。
我们看到了使用co封装了Generator的更加优雅和简单的异步编程方式。
可以在这里查看上述所有代码:[查找当前目录下的最大文件]
从上面的最后一个代码片段中我们可以看出,这里的Generator与原生的Generator 有一定的不同,因为koa中的Generator使用了co进行了封装。
4.1 co的简单使用:
1 var co = require(‘co‘);
2 var fs = require(‘fs‘);
3
4 function read(file) {
5 return function(fn){
6 fs.readFile(file, ‘utf8‘, fn);
7 }
8 }
9 co(function *(){
10
11 var a = yield read(‘.gitignore‘);
12 console.log(a.length);
13
14 var b = yield read(‘package.json‘);
15 console.log(b.length);
16 });
co要求所有的异步函数都是thunk函数:
1 function read(file) {
2 return function(fn){
3 fs.readFile(file, ‘utf8‘, fn);
4 }
5 }
如果需要对thunk函数返回的数据做一些处理可以写在回调函数中:
1 function read(file) {
2 return function(fn){
3 fs.readFile(file, ‘utf8‘, function(err,result){
4 if (err) return fn(err);
5 fn(null, result);
6 });
7 }
8 }
我们也可以不用自己写thunk函数,使用thunkify模块就好了:
1 var thunkify = require(‘thunkify‘);
2 var fs = require(‘fs‘);
3
4 var read = thunkify(fs.readFile);
获取thunk函数的返回结果,就是用yield关键字就可以了:
1 var a = yield read(‘.gitignore‘);
2 console.log(a.length);
可以看到我们不用再使用next方法了,co将generator function的流转封装好了。
4.2 Thunk函数
我们将参数放在一个临时函数中,再将这个临时函数传入函数体,当用到该参数时对临时函数求值即可。这个临时函数就叫Thunk函数。
Thunk是“传名调用”的一种实现策略,用来替换某个表达式:
1 function f(m){
2 return m * 2;
3 }
4
5 f(x + 5);
6
7 // 等同于
8
9 var thunk = function () {
10 return x + 5;
11 };
12
13 function f(thunk){
14 return thunk() * 2;
15 }
JavaScript 语言是传值调用,它的 Thunk 函数含义有所不同。在 JavaScript 语言中,Thunk 函数替换的不是表达式,而是多参数函数,将其替换成单参数的版本,且只接受回调函数作为参数:
1 // 正常版本的readFile(多参数版本)
2 fs.readFile(fileName, callback);
3
4 // Thunk版本的readFile(单参数版本)
5 var readFileThunk = Thunk(fileName);
6 readFileThunk(callback);
7
8 var Thunk = function (fileName){
9 return function (callback){
10 return fs.readFile(fileName, callback);
11 };
12 };
更多详细请阅读:[Thunk函数的含义和用法]
现在看起来所有的Generator函数都在运行,我们使用yield关键字只是让它暂停了一下。那么难道这是传说中的多线程在js中的实现吗?
然而并不是的.. 我们只要牢牢的记住,js真的是单线程的。我们只是具备了在一个函数中暂停的能力。
并且,如果在对性能要求很高的情况下,generator可能不适合作为首选。
我们可以跑一个耗费CPU的例子来看一下。
使用普通的函数和Generator函数分别来实现斐波那契数列的计算:
1 var suite = new (require(‘benchmark‘)).Suite; 2 3 function fib(n){ 4 var current = 0,next = 1,swap; 5 for(var i=0;i<n;i++){ 6 swap = current,current = next; 7 next = swap + next; 8 } 9 return current; 10 } 11 12 function* fibGen(n){ 13 var current = 0,next = 1,swap; 14 for(var i=0;i<n;i++){ 15 swap = current,current = next; 16 next = swap + next; 17 yield current; 18 } 19 } 20 21 suite 22 .add(‘regular‘,function(){ 23 fib(20); 24 }) 25 .add(‘generator‘,function(){ 26 for(var n of fibGen(20)); 27 }) 28 .on(‘complete‘,function(){ 29 console.log(‘results:‘); 30 this.forEach(function(result){ 31 console.log(result.name,result.count); 32 }) 33 }) 34 .run()
这里我们使用了benchmark模块,来测量执行时间。
然后我们执行:
1 node --harmony fibonacci.js
就可以查看到执行的结果:
1 results: 2 regular 1434583 3 generator 39962
可以看到generator的效率并不比普通的函数要好(这里面数值越大越好)。
我们看了这么多generator的东西,写了一些例子,那么它的闪光点到底在那些方面呢? 我们来总结一下。
6.1 懒惰的执行
也就是传说中的lazy evaluation。其实我们通过闭包也可以实现,但是通过使用yield使事情变得简单了。我们可以在我们需要获取相应的值得时候才去获取:
1 var fibIter = fibGen(20) 2 var next = fibIter.next() 3 console.log(next.value) 4 5 setTimeout(function () { 6 var next = fibIter.next() 7 console.log(next.value) 8 },2000)
如果我们想从头到尾的执行也可使用上面说到的for of循环:
1 for (var n of fibGen(20) { 2 console.log(n) 3 }
6.2 无限的执行
既然generator函数的执行是懒惰的,在我们需要的时候去执行获取相应的值就可以了,那么就可能实现无限执行的情况:
1 function* fibGen () { 2 var current = 0, next = 1, swap 3 while (true) { 4 swap = current, current = next 5 next = swap + next 6 yield current 7 } 8 }
6.3 同步的控制流
最初使generator用于同步控制流程的是task.js(现在已经不复存在)。这个概念因为co模块和其他一些promise实现而变得流行了起来。
但是在如何实现呢?
在Node中,我们总是把一些事情都放到回调里去做,来时先同步的效果,这可能是比较初级的同步实现。前面也有例子,一步一步的进化成简介高效的generator版本。
这里有个简单的例子,使我们得到了同步的版本,但是写起来就像异步实现的一样:
1 var fs = require(‘fs‘); 2 var thunkify = require(‘thunkify‘); 3 var readFile = thunkify(fs.readFile); 4 5 run(function* (){ 6 try{ 7 var file = yield readFile(‘./fibonacci.js‘); 8 console.log(file.toString()); 9 }catch (er){ 10 console.error(er); 11 } 12 }); 13 14 function run(genFn){ 15 var gen = genFn(); 16 next(); 17 function next(er,value){ 18 if(er) return gen.throw(er); 19 var continuable = gen.next(value); 20 21 if(continuable.done) return; 22 var cbFn = continuable.value; 23 cbFn(next); 24 } 25 }
文章中提到的所有代码都可以在这里找到源码:[查看源码]。
[sync 模块]
[async函数的含义和用法]
标签:
原文地址:http://www.cnblogs.com/skylar/p/es6-generator-koa-co-nodejs-js.html
