标签:
目前postgresql中的部分函数在hive中也是存在的,所以今天就以postgresql为例来进行说明,这个过程同时可以应用到hive中。
1、创建表
CREATE TABLE employee ( empid INT, deptid INT, salary DECIMAL (10, 2) );
2、导入数据
INSERT INTO employee VALUES(1, 10, 5500.00); INSERT INTO employee VALUES(2, 10, 4500.00); INSERT INTO employee VALUES(3, 20, 1900.00); INSERT INTO employee VALUES(4, 20, 4800.00); INSERT INTO employee VALUES(6, 40, 14500.00); INSERT INTO employee VALUES(7, 40, 44500.00); INSERT INTO employee VALUES(10, 40, 44500.00); INSERT INTO employee VALUES(11, 40, 44501.00); INSERT INTO employee VALUES(8, 50, 6500.00); INSERT INTO employee VALUES(9, 50, 7500.00);
3、应用
--每个部门工资最高的 select * from ( select e.*,row_number() over(partition by e.deptid order by e.salary desc) rank from employee e ) ee where ee.rank =1;

--应该用rank,对于工资相同的应该都显示出来 select * from ( select e.*,rank() over(partition by e.deptid order by e.salary desc) rank from employee e ) ee where ee.rank =1;

--rank和dense_rank的区别就是前者占位,后者不占位 --ntile可以看作是把有序的数据集合平均分配到expr指定的数量的桶中,将桶号分配给每一行。 --如果不能平均分配,则较小桶号的桶分配额外的行,并且各个桶中能放的行数最多相差1。 select e.*, ntile(3) over(partition by e.deptid order by e.salary desc) ntile, rank() over(partition by e.deptid order by e.salary desc) rank, dense_rank() over(partition by e.deptid order by e.salary desc) drank, row_number() over(partition by e.deptid order by e.salary desc) rownum, first_value(salary) over(partition by e.deptid order by e.salary desc) fv, last_value(salary) over(partition by e.deptid order by e.salary asc) lv from employee e
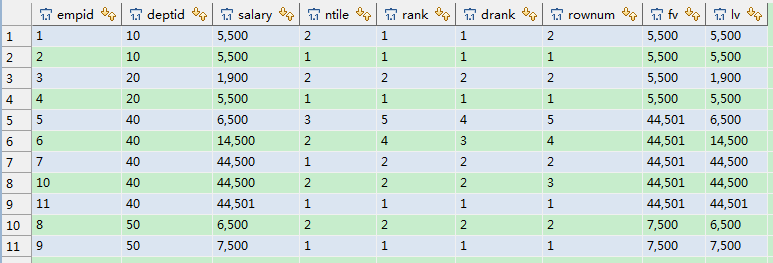
好了,就这些了,通过例子能很清楚的看到各个函数的应用
标签:
原文地址:http://my.oschina.net/sucre/blog/506188