标签:
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取Web站点并从页面中提取结构化的数据.它最吸引人的地方在于任何人都可以根据需求方便的修改。
MongoDB是现下非常流行的开源的非关系型数据库(NoSql),它是以“key-value”的形式存储数据的,在大数据量、高并发、弱事务方面都有很大的优势。
当Scrapy与MongoDB两者相碰撞会产生怎样的火花呢?与MongoDB两者相碰撞会产生怎样的火花呢?现在让我们做一个简单的爬取小说的TEST
1.安装Scrapy
pip install scrapy
2.下载安装MongoDB和MongoVUE可视化
[MongoDB下载地址](https://www.mongodb.org/)
下载安装的步骤略过,在bin目录下创建一个data文件夹用来存放数据的。
[MongoVUE下载地址](http://www.mongovue.com/)
安装完成后我们需要创建一个数据库。
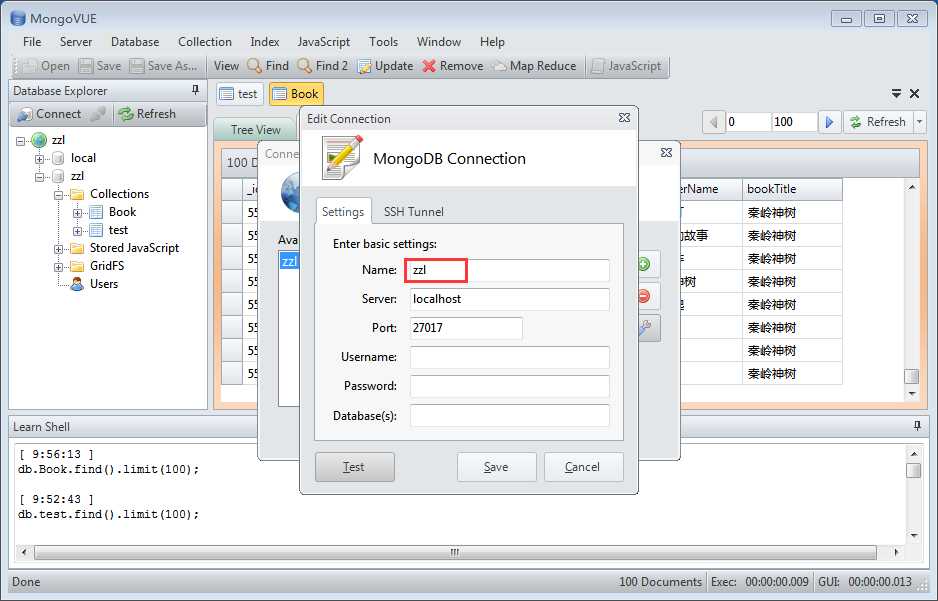
3.创建一个Scrapy项目
scrapy startproject novelspider
目录结构:其中的novspider.py是需要我们手动创建的(contrloDB不需要理会)
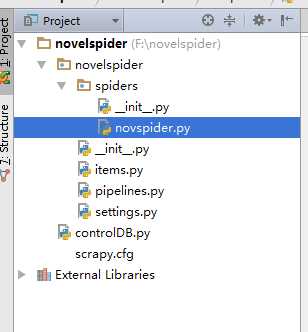
4.编写代码
目标网站:http://www.daomubiji.com/
settings.py
BOT_NAME = ‘novelspider‘ SPIDER_MODULES = [‘novelspider.spiders‘] NEWSPIDER_MODULE = ‘novelspider.spiders‘ ITEM_PIPELINES = [‘novelspider.pipelines.NovelspiderPipeline‘] #导入pipelines.py中的方法 USER_AGENT = ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:39.0) Gecko/20100101 Firefox/39.0‘ COOKIES_ENABLED = True MONGODB_HOST = ‘127.0.0.1‘ MONGODB_PORT = 27017 MONGODB_DBNAME = ‘zzl‘ #数据库名 MONGODB_DOCNAME = ‘Book‘ #表名
pipelines.py
from scrapy.conf import settings import pymongo class NovelspiderPipeline(object): def __init__(self): host = settings[‘MONGODB_HOST‘] port = settings[‘MONGODB_PORT‘] dbName = settings[‘MONGODB_DBNAME‘] client = pymongo.MongoClient(host=host, port=port) tdb = client[dbName] self.post = tdb[settings[‘MONGODB_DOCNAME‘]] def process_item(self, item, spider): bookInfo = dict(item) self.post.insert(bookInfo) return item
items.py
from scrapy import Item,Field class NovelspiderItem(Item): # define the fields for your item here like: # name = scrapy.Field() bookName = Field() bookTitle = Field() chapterNum = Field() chapterName = Field() chapterURL = Field()
在spiders目录下创建novspider.py
from scrapy.spiders import CrawlSpider from scrapy.selector import Selector from novelspider.items import NovelspiderItem class novSpider(CrawlSpider): name = "novspider" redis_key = ‘novspider:start_urls‘ start_urls = [‘http://www.daomubiji.com/‘] def parse(self,response): selector = Selector(response) table = selector.xpath(‘//table‘) for each in table: bookName = each.xpath(‘tr/td[@colspan="3"]/center/h2/text()‘).extract()[0] content = each.xpath(‘tr/td/a/text()‘).extract() url = each.xpath(‘tr/td/a/@href‘).extract() for i in range(len(url)): item = NovelspiderItem() item[‘bookName‘] = bookName item[‘chapterURL‘] = url[i] try: item[‘bookTitle‘] = content[i].split(‘ ‘)[0] item[‘chapterNum‘] = content[i].split(‘ ‘)[1] except Exception,e: continue try: item[‘chapterName‘] = content[i].split(‘ ‘)[2] except Exception,e: item[‘chapterName‘] = content[i].split(‘ ‘)[1][-3:] yield item
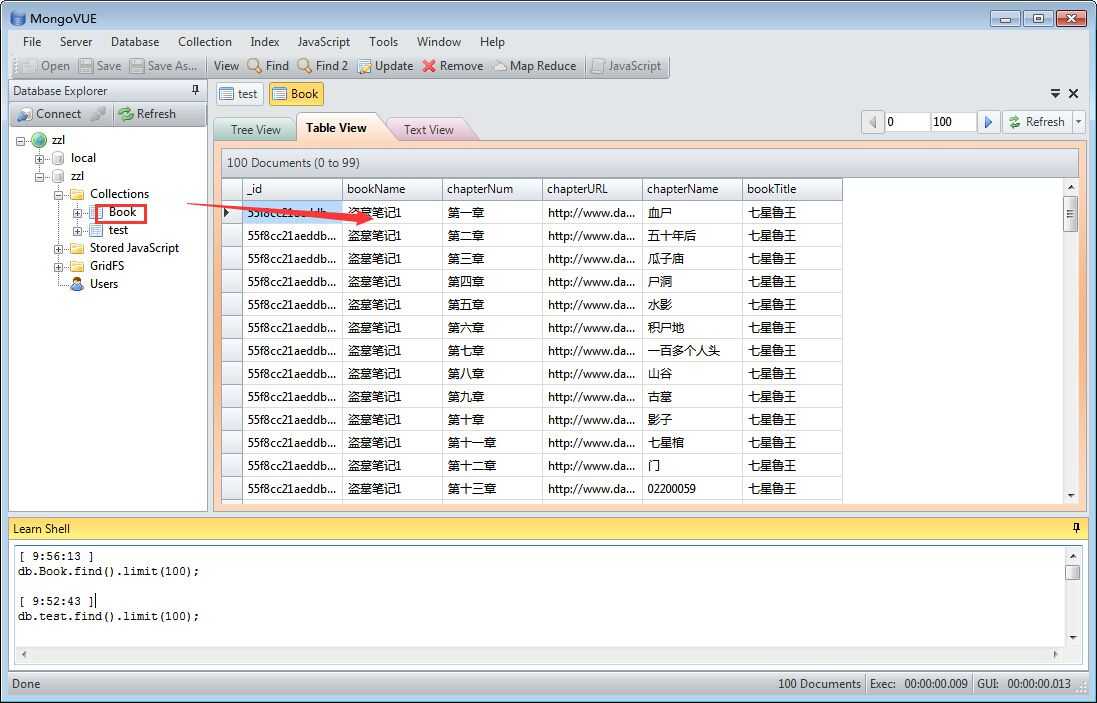
5.启动项目命令: scrapy crawl novspider.
抓取结果
标签:
原文地址:http://www.cnblogs.com/alarm1673/p/4812460.html