标签:
徒手用Java来写个Web服务器和框架吧<第一章:NIO篇>
接上一篇,说到接受了请求,接下来就是解析请求构建Request对象,以及创建Response对象返回。
多有纰漏还请指出。省略了很多生产用的服务器需要处理的过程,仅供参考。可能在不断的完整中修改文章内容。
先上图
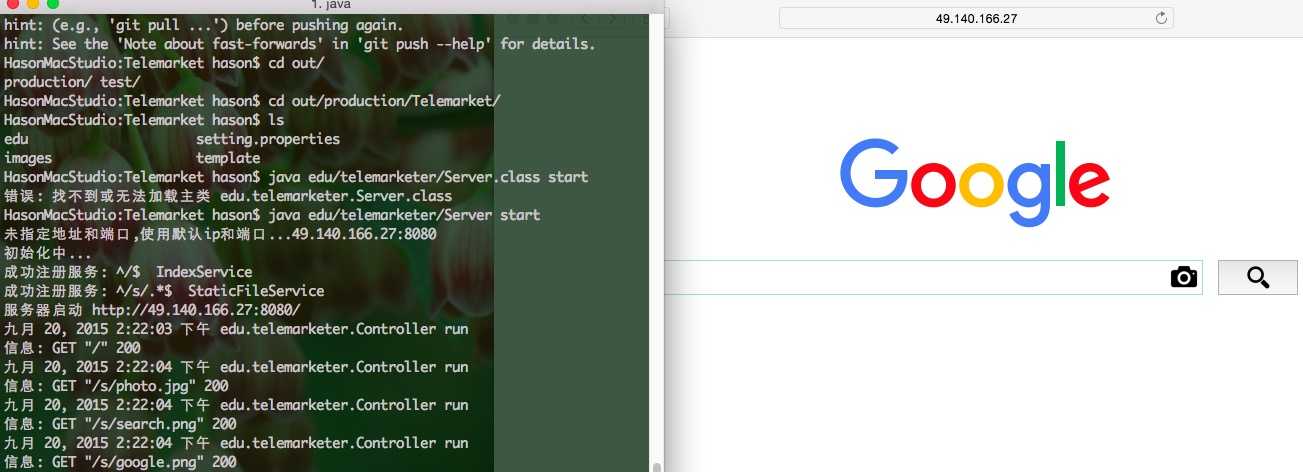
项目地址: https://github.com/csdbianhua/Telemarketer
首先看看如何解析请求
一个HTTP的GET请求大概如下所示。
GET / HTTP/1.1
Host: 123.45.67.89
Connection: keep-alive
Cache-Control: max-age=0
...
一个HTTP的POST请求大概如下
POST /post HTTP/1.1
Host: 123.45.67.89
Connection: keep-alive
Cache-Control: max-age=0
...
\r\n
one=23&two=123
请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本。 接下来就是一系列的头域,我们先不管每个的作用,先把他们提取出来保存到Request对象里再说。 每行结尾都有一个\r\n,并且除了作为结尾的\r\n外,不允许出现单独的\r或\n字符。 而post方法有个消息体,与HTTP头之间由一个\r\n隔开。
那么我们的Request对象就应该有这样几个成员
1 private String path; 2 private String method; 3 private Map<String, String> head; 4 private Map<String, String> requestParameters; 5 private byte[] messageBody;
其中path是请求的URI、method是请求的方法、head是各个头域、requestParameter是请求参数(比如123.45.67.89/?one=23&two=123,参数就是 one=23和two=123。或者post的表单里),由于messageBody里面可能有二进制数据,就统一先用byte[]表示
好,现在可以开始啃这块NIO读取的ByteBuffer了。
首先我们得分开头部和身子。
既然读取的是ByteBuffer,那么要读取的话首先当然是调整一下position的位置。不然顺着已写入的位置继续往下读是完全没有数据的。 那么这样
if (buffer.position() != 0) { buffer.flip(); }
flip()的作用不用多说了吧 看源代码就做了这么几件事 limit = position; position = 0; mark = -1;
接下来读取它的byte数组
1 int remaining = buffer.remaining(); 2 byte[] bytes = new byte[remaining]; 3 buffer.get(bytes);
然后就开始循环找到 两个\r\n同时出现的地方,那就是我们要砍的脖子的位置。
1 for (int i = 0; i < remaining; i++) { 2 if (bytes[i] == ‘\r‘ && bytes[i + 1] == ‘\n‘) { 3 position = i; 4 i += 2; 5 } 6 if (i + 1 < remaining && bytes[i] == ‘\r‘ && bytes[i + 1] == ‘\n‘) { 7 break; 8 } 9 } 10 buffer.rewind(); 11 byte[] head = new byte[position]; 12 buffer.get(head, 0, position); 13 byte[] body = null; 14 if (remaining - position > 4) { 15 buffer.position(position + 4); 16 body = new byte[remaining - position - 4]; 17 buffer.get(body, 0, remaining - position - 4); 18 }
同样记得在get完之后还要重新读得话得 rewind() 将position 归零。 注意这一句 buffer.position(position + 4) 因为都是从buffer.position开始读的。而buffer.position此时已经到了头的末尾,想要读body只要让position前进四位即可。
到这里就斩首完了,成了一个字节数组的头 byte[] head 和字节数组的身子byte[] head。
接下来才是真正关键的解析的时候。
头基本就是UTF-8编码了,直接br读就行。
BufferedReader reader = new BufferedReader(new StringReader(new String(head,"UTF-8")));
读第一行 用空格分开,第一个就是请求方法,第二个就是uri。 注意要使用 URLDecoder.decode(lineOne[1], "utf-8"); 进行解码uri,因为会可能会包括%20等转义字符。
接下来读取每一行 String[] keyValue = line.split(":"); 再去掉空格添加到headMap里 headMap.put(keyValue[0].trim(), keyValue[1].trim()); 头就读完了。
然后是参数,先弄Get的参数,再弄Post表单的参数。获得了那串字符串( one=23&two=123 )后就用这个方法解析出来。
1 void parseParameters(String s, Map<String, String> requestParameters) { 2 String[] paras = s.split("&"); 3 for (String para : paras) { 4 String[] split = para.split("="); 5 requestParameters.put(split[0], split[1]); 6 } 7 }
比如Get的
1 String[] pathPart = path.split("\\?"); 2 path = pathPart[0]; 3 if (pathPart.length == 2) { 4 parseParameters(pathPart[1], requestParameters); 5 }
怎么判断是不是Post表单呢,可以看看Content-Type里是不是 application/x-www-form-urlencoded
headMap.containsKey("Content-Type") && headMap.get("Content-Type").contains("application/x-www-form-urlencoded")
这样Request就出来了。
先看一个简化的Http响应
HTTP/1.1 200 OK
Date: Sun, 20 Sep 2015 05:04:55 GMT
Server: Apache
Content-Type: text/html; charset=utf-8
Content-Length: 100
\r\n
...
先不考虑其他设置Cookie等头域,浏览器主要想知道HTTP协议版本、返回码、内容种类和内容长度。 那我们就考虑这几项先。
Response的成员变量只需
private Status status;
private Map<String, String> heads;
private byte[] content;
先来看看Date
使用一个SimpleDateFormat格式化时间成rfc822,注意要将Locale设置成English。
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("EEE, d MMM yyyy HH:mm:ss zzz", Locale.ENGLISH);
但是这样时区不对,那我们再设置一下时区 static { simpleDateFormat.setTimeZone(TimeZone.getTimeZone("GMT")); }
如果是文本类型需要用户指定,比如Json。 使用 URLConnection.getFileNameMap().getContentTypeFor(path) 即可获得文件路径对应的MIME类型。同时如果是文本类型,需要写出charset。
if (contentType.startsWith("text")) {
contentType += "; charset=" + charset;
}
设置成content.length就好了。
如果内容是文件 Files.readAllBytes(FileSystems.getDefault().getPath(path)); 就可以读取所有的字节。 如果内容是文本,直接编码成UTF-8就好了。当然一般来说是Json文本,那么Content-Type需要设置为application/json; charset=utf-8 。这个可以用户指定。
由于最后写入SocketChannel需要ByteBuffer,那么我们需要将响应变成ByteBuffer。按格式写好转换成ByteBuffer就行。
1 private ByteBuffer finalData = null; 2 public ByteBuffer getByteBuffer() { 3 if (finalData == null) { 4 heads.put("Content-Length", String.valueOf(content.length)); 5 StringBuilder sb = new StringBuilder(); 6 sb.append(HTTP_VERSION).append(" ").append(status.getCode()).append(" ").append(status.getMessage()).append("\r\n"); 7 for (Map.Entry<String, String> entry : heads.entrySet()) { 8 sb.append(entry.getKey()).append(": ").append(entry.getValue()).append("\r\n"); 9 } 10 sb.append("\r\n"); 11 byte[] head = sb.toString().getBytes(CHARSET); 12 finalData = ByteBuffer.allocate(head.length + content.length + 2); 13 finalData.put(head); 14 finalData.put(content); 15 finalData.put((byte) ‘\r‘); 16 finalData.put((byte) ‘\n‘); 17 finalData.flip(); // 记得这里需要flip 18 } 19 return finalData; 20 }
这里使用了一个finalData保存最后的结果,一旦调用就不可修改了,同时防止重复读取时发送同一个内容。不然的话每读一次 hasRemaining 都为true。
徒手用Java来写个Web服务器和框架吧<第二章:Request和Response>
标签:
原文地址:http://www.cnblogs.com/imyijie/p/4823407.html