标签:
OPT文件,cd OPT,却显示not a directory,通过阅读《linux嵌入式》这本书使用mkdir创建目录,可能是因为OPT文件的存在,并不能创建新的目录
与网上得搜索,了解应建立OPT文件夹,而不是文件。
2.同上,在建立fortest这个文件的时候,不小心按了两次touch fortest,列出文件的时候,发现建了两个forloutest文件,修改访问权限得时候,哪怕修改两次,被修改得也只有一个文件,另一个文件修改不了,而且使用rm删除,好像也没有用。
体会:有时候按照实验指导做,但是并不是每一步都是告诉我们得,所以做实验之前最好要结合课本的知识。而且做实验的时候,觉得自己要学的还有很多。
知识点:
进入上一级目录:$ cd ..
进入你的“home”目录:$ cd ~ # 或者 cd /home/<你的用户名>
使用 pwd 获取当前路径
绝对路径,以根"/"目录为起点的完整路径,以你所要到的目录为终点
表现形式如: /usr/local/bin,表示根目录下的 usr 目录中的 local 目录中的 bin 目录。
相对路径,相对于你当前的目录的路径,相对路径是以当前目录 . 为起点,以你所要到的目录为终点,
表现形式如:usr/local/bin (这里假设你当前目录为根目录)。
实验截图:
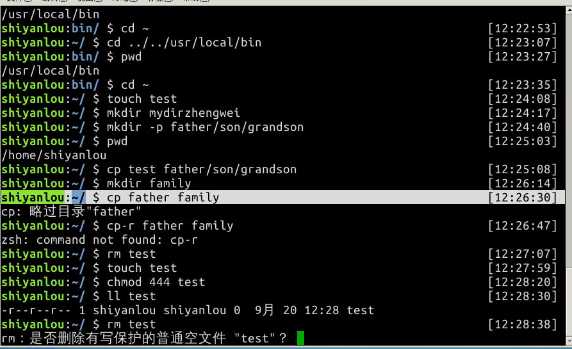
使用 touch 命令创建空白文件
创建名为 test 的空白文件,因为在其他目录没有权限,所以需要先 cd ~ 切换回用户的/home/shiyanlou 目录:
使用 mkdir(make directories)命令可以创建一个空目录,也可同时指定创建目录的权限属性
使用cp(copy)命令复制一个文件或目录到指定目录。
使用rm(remove files or directories)命令,删除一个文件或目录:
直接使用rm删除会显示一个提示,
想忽略这提示,直接删除文件,可以使用-f参数强制删除
跟复制目录一样,要删除一个目录,也需要加上-r或-R参数
使用mv(move or rename files)命令,移动文件(剪切)。
cat,tac和nl命令查看文件cat为正序显示,tac倒序显示。
标准输入输出:当我们执行一个 shell 命令行时通常会自动打开三个标准文件,即标准输入文件(stdin),默认对应终端的键盘;标准输出文件(stdout)和标准错误输出文件(stderr),这两个文件都对应被重定向到终端的屏幕,以便我们能直接看到输出内容。进程将从标准输入文件中得到输入数据,将正常输出数据输出到标准输出文件,而将错误信息送到标准错误文件中。
-n参数显示行号
nl命令,添加行号并打印
常用的几个参数:
-b : 指定添加行号的方式,主要有两种:
-b a:表示无论是否为空行,同样列出行号("cat -n"就是这种方式)
-b t:只列出非空行的编号并列出(默认为这种方式)
-n : 设置行号的样式,主要有三种:
-n ln:在行号字段最左端显示
-n rn:在行号字段最右边显示,且不加 0
-n rz:在行号字段最右边显示,且加 0
-w : 行号字段占用的位数(默认为 6 位)more和less命令分页查看文件tail命令,不得不提的还有它一个很牛的参数-f,这个参数可以实现不停地读取某个文件的内容并显示。这可让我们动态查看日志起到实时监视的作用
通常使用file命令可以查看文件的类型
专门的命令行编辑器比如(emacs,vim,nano)
使用declare命令创建一个变量名为 tmp 的变量:
变量名只能是英文字母,数字或者下划线,且不能以数字作为开头。
环境变量就是作用域比自定义变量要大
Shell 的环境变量作用于自身和它的子进程。
通常我们会涉及到的环境变量有三种:
也有三个与上述三种环境变量相关的命令,set,env,export。这三个命令很相似,都可以用于打印相关环境变量,区别在于涉及的是不同范围的环境变量,详见下表:
| 命令 | 说明 |
|---|---|
set |
显示当前 Shell 所有环境变量,包括其内建环境变量(与 Shell 外观等相关),用户自定义变量及导出的环境变量 |
env |
显示与当前用户相关的环境变量,还可以让命令在指定环境中运行 |
export |
显示从 Shell 中导出成环境变量的变量,也能通过它将自定义变量导出为环境变量 |
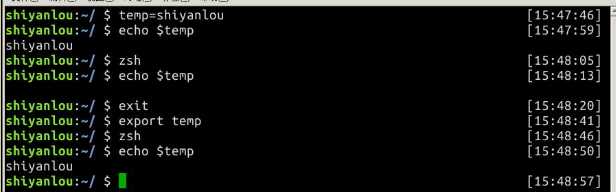
每个用户的 home 目录中有一个 Shell 每次启动时会默认执行一个配置脚本,以初始化环境,包括添加一些用户自定义环境变量等等。zsh 的配置文件是.zshrc,相应 Bash 的配置文件为.bashrc
变量的修改有以下几种方式
| 变量设置方式 | 说明 |
|---|---|
${变量名#匹配字串} |
从头向后开始匹配,删除符合匹配字串的最短数据 |
${变量名##匹配字串} |
从头向后开始匹配,删除符合匹配字串的最长数据 |
${变量名%匹配字串} |
从尾向前开始匹配,删除符合匹配字串的最短数据 |
${变量名%%匹配字串} |
从尾向前开始匹配,删除符合匹配字串的最长数据 |
${变量名/旧的字串/新的字串} |
将符合旧字串的第一个字串替换为新的字串 |
${变量名//旧的字串/新的字串} |
将符合旧字串的全部字串替换为新的字串 |
比如要修改我们前面添加到 PATH 的环境变量。
与搜索相关的命令常用的有如下几个whereis,which,find,locate。
whereis只能搜索二进制文件(-b),man帮助文件(-m)和源代码文件(-s)。如果想要获得更全面的搜索结果可以使用locate命令。
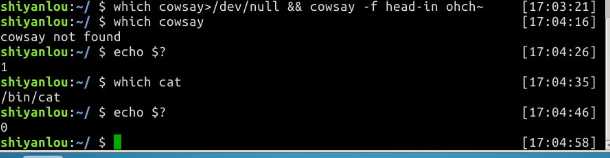
which小而精which本身是 Shell 内建的一个命令,我们通常使用which来确定是否安装了某个指定的软件,因为它只从PATH环境变量指定的路径中去搜索命令:
find精而细find应该是这几个命令中最强大的了,它不但可以通过文件类型、文件名进行查找而且可以根据文件的属性(如文件的时间戳,文件的权限等)进行搜索。
注意 find 命令的路径是作为第一个参数的, 基本命令格式为 find [path] [option] [action]
作业:
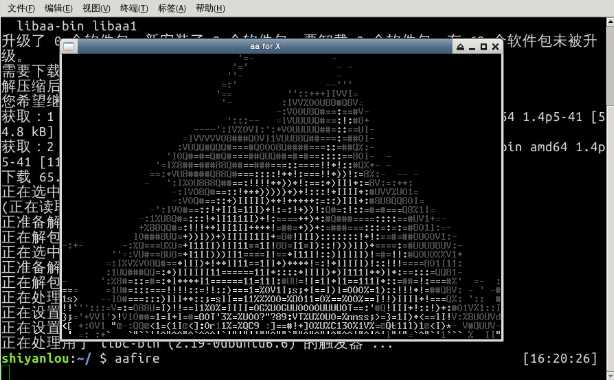
《黑客帝国》电影里满屏幕代码的“数字雨”,在 Linux 里面你也可以轻松实现这样的效果
Linux 上常用的 压缩/解压 工具,介绍了 zip,rar,tar 的使用。
zip压缩打包程序第一行命令中,-r参数表示递归打包包含子目录的全部内容,-q参数表示为安静模式,即不向屏幕输出信息,-o,表示输出文件,需在其后紧跟打包输出文件名。后面使用du命令查看打包后文件的大小
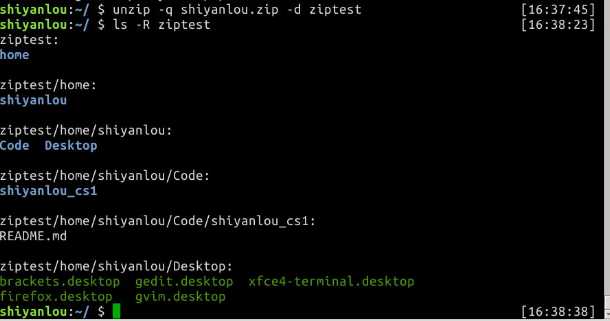
unzip命令解压缩zip文件
不想解压只想查看压缩包的内容你可以使用-l参数
使用-O(英文字母,大写o)参数指定编码类型:
rar打包压缩命令a参数添加一个目录~到一个归档文件中,如果该文件不存在就会自动创建。作业:天冷的时候,要是有个火炉就好了。

然后再使用mkfs格式化各分区
顺序执行、选择执行、管道、cut 命令、grep 命令、wc 命令、sort 命令等
&&就是用来实现选择性执行的,它表示如果前面的命令执行结果(不是表示终端输出的内容,而是表示命令执行状态的结果)返回0则执行后面的,否则不执行,你可以从$?环境变量获取上一次命令的返回结果
管道又分为匿名管道和具名管道
在使用一些过滤程序时经常会用到的就是匿名管道,在命令行中由|分隔符表示,|在前面的内容中我们已经多次使用到了。具名管道简单的说就是有名字的管道,通常只会在源程序中用到具名管道。下面我们就将通过一些常用的可以使用管道的"过滤程序"来帮助你熟练管道的使用。
uniq命令可以用于过滤或者输出重复行。
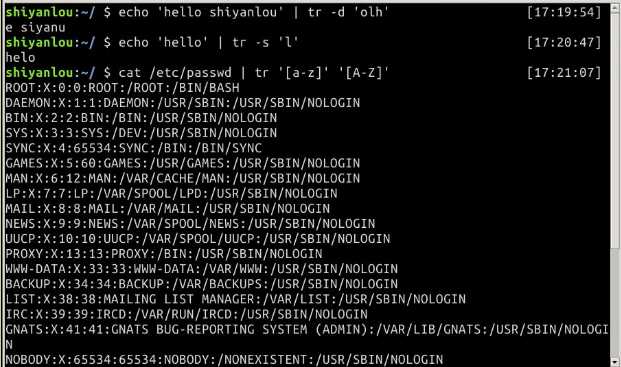
tr 命令可以用来删除一段文本信息中的某些文字。或者将其进行转换。
col 命令可以将Tab换成对等数量的空格建,或反转这个操作。
用于将两个文件中包含相同内容的那一行合并在一起。
paste这个命令与join 命令类似,它是在不对比数据的情况下,简单地将多个文件合并一起,以Tab隔开。
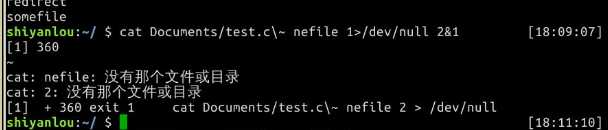
注意不要将管道和重定向混淆,管道默认是连接前一个命令的输出到下一个命令的输入,而重定向通常是需要一个文件来建立两个命令的连接
tee命令同时重定向到多个文件除了将需要将输出重定向到文件之外也需要将信息打印在终端
exec命令的作用是使用指定的命令替换当前的 Shell,及使用一个进程替换当前进程,或者指定新的重定向使用exec命令可以创建新的文件描述符
在 Linux 中有一个被成为“黑洞”的设备文件,所以导入它的数据都将被“吞噬”。
在类 UNIX 系统中,/dev/null,或称空设备,是一个特殊的设备文件,它通常被用于丢弃不需要的输出流,或作为用于输入流的空文件,这些操作通常由重定向完成。读取它则会立即得到一个EOF。
xargs 是一条 UNIX 和类 UNIX 操作系统的常用命令。它的作用是将参数列表转换成小块分段传递给其他命令,以避免参数列表过长的问题。
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法
一个正则表达式通常被称为一个模式(pattern),为用来描述或者匹配一系列符合某个句法规则的字符串。
|竖直分隔符表示选择,例如"boy|girl"可以匹配"boy"或者"girl"
数量限定除了我们举例用的*,还有+加号,?问号,.点号,如果在一个模式中不加数量限定符则表示出现一次且仅出现一次:
优先级为从上到下从左到右,依次降低:
rep命令用于打印输出文本中匹配的模式串,它使用正则表达式作为模式匹配的条件。grep支持三种正则表达式引擎,分别用三个参数指定:
| 参数 | 说明 |
|---|---|
-E |
POSIX扩展正则表达式,ERE |
-G |
POSIX基本正则表达式,BRE |
-P |
Perl正则表达式,PCRE |
虽然我们这一节的标题是正则表达式,但实际这一节实验只是介绍grep,sed,awk这三个命令,而正则表达式作为这三个命令的一种使用方式(命令输出中可以包含正则表达式)。正则表达式本身的内容很多,要把它说明清楚需要单独一门课程来实现,不过我们这一节中涉及到的相关内容通常也能够满足很多情况下的需求了。
想要更深入地学习使用正则表达式,在这里 正则表达式基础。
我们先找一个用于练习的文本文件:
$ cp /etc/passwd ~
# 打印2-5行
$ nl passwd | sed -n ‘2,5p‘
# 打印奇数行
$ nl passwd | sed -n ‘1~2p‘
# 将输入文本中"shiyanlou" 全局替换为"hehe",并只打印替换的那一行,注意这里不能省略最后的"p"命令
$ sed -n ‘s/shiyanlou/hehe/gp‘ passwd
注意: 行内替换可以结合正则表达式使用。
$ nl passwd | grep "shiyanlou"
# 删除第21行
$ sed -n ‘21c\www.shiyanlou.com‘ passwd
关于sed命令就介绍这么多,你如果希望了解更多sed的高级用法,你可以参看如下链接:
看到上面的标题,你可能会感到惊异,难道我们这里要学习的是一门“语言”么,确切的说,我们是要在这里学习awk文本处理语言,只是我们并不会在这里学习到比较完整的关于awk的内容,还是因为前面的原因,它太强大了,它的应用无处不在,我们无法在这里以简短的文字描述面面俱到,如果你有目标成为一个linux系统管理员,确实想学好awk,你一不用担心,实验楼会在之后陆续上线linux系统管理员的学习路径,里面会有单独的关于正则表达式,awk,sed等相关课程,敬请期待吧。下面的内容,我们就作为一个关于awk的入门体验章节吧,其中会介绍一些awk的常用操作。
AWK是一种优良的文本处理工具,Linux及Unix环境中现有的功能最强大的数据处理引擎之一.其名称得自于它的创始人Alfred Aho(阿尔佛雷德·艾侯)、Peter Jay Weinberger(彼得·温伯格)和Brian Wilson Kernighan(布莱恩·柯林汉)姓氏的首个字母.AWK程序设计语言,三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。最简单地说,AWK是一种用于处理文本的编程语言工具。
在大多数linux发行版上面,实际我们使用的是gawk(GNU awk,awk的GNU版本),在我们的环境中ubuntu上,默认提供的是mawk,不过我们通常可以直接使用awk命令(awk语言的解释器),因为系统已经为我们创建好了awk指向mawk的符号链接。
$ ll /usr/bin/awk
nawk: 在 20 世纪 80 年代中期,对 awk语言进行了更新,并不同程度地使用一种称为 nawk(new awk) 的增强版本对其进行了替换。许多系统中仍然存在着旧的awk 解释器,但通常将其安装为 oawk (old awk) 命令,而 nawk 解释器则安装为主要的 awk 命令,也可以使用 nawk 命令。Dr. Kernighan 仍然在对 nawk 进行维护,与 gawk 一样,它也是开放源代码的,并且可以免费获得; gawk: 是 GNU Project 的awk解释器的开放源代码实现。尽管早期的 GAWK 发行版是旧的 AWK 的替代程序,但不断地对其进行了更新,以包含 NAWK 的特性; mawk 也是awk编程语言的一种解释器,mawk遵循 POSIX 1003.2 (草案 11.3)定义的 AWK 语言,包含了一些没有在AWK 手册中提到的特色,同时 mawk 提供一小部分扩展,另外据说mawk是实现最快的awk
awk所有的操作都是基于pattern(模式)—action(动作)对来完成的,如下面的形式:
$ pattern {action}
你可以看到就如同很多编程语言一样,它将所有的动作操作用一对{}花括号包围起来。其中pattern通常是是表示用于匹配输入的文本的“关系式”或“正则表达式”,action则是表示匹配后将执行的动作。在一个完整awk操作中,这两者可以只有其中一个,如果没有pattern则默认匹配输入的全部文本,如果没有action则默认为打印匹配内容到屏幕。
awk处理文本的方式,是将文本分割成一些“字段”,然后再对这些字段进行处理,默认情况下,awk以空格作为一个字段的分割符,不过这不是固定了,你可以任意指定分隔符,下面将告诉你如何做到这一点。
awk [-F fs] [-v var=value] [-f prog-file | ‘program text‘] [file...]
其中-F参数用于预先指定前面提到的字段分隔符(还有其他指定字段的方式) ,-v用于预先为awk程序指定变量,-f参数用于指定awk命令要执行的程序文件,或者在不加-f参数的情况下直接将程序语句放在这里,最后为awk需要处理的文本输入,且可以同时输入多个文本文件。现在我们还是直接来具体体验一下吧。
先用vim新建一个文本文档
$ vim test
包含如下内容:
I like linux
www.shiyanlou.com
# "quote>" 不用输入
$ awk ‘{
> print
> }‘ test
# 或者写到一行
$ awk ‘{print}‘ test
说明:在这个操作中我是省略了patter,所以awk会默认匹配输入文本的全部内容,然后在"{}"花括号中执行动作,即print打印所有匹配项,这里是全部文本内容
$ awk ‘{
> if(NR==1){
> print $1 "\n" $2 "\n" $3
> } else {
> print}
> }‘ test
# 或者
$ awk ‘{
> if(NR==1){
> OFS="\n"
> print $1, $2, $3
> } else {
> print}
> }‘ test
说明:你首先应该注意的是,这里我使用了awk语言的分支选择语句if,它的使用和很多高级语言如C/C++语言基本一致,如果你有这些语言的基础,这里将很好理解。另一个你需要注意的是NR与OFS,这两个是awk内建的变量,NR表示当前读入的记录数,你可以简单的理解为当前处理的行数,OFS表示输出时的字段分隔符,默认为" "空格,如上图所见,我们将字段分隔符设置为\n换行符,所以第一行原本以空格为字段分隔的内容就分别输出到单独一行了。然后是$N其中N为相应的字段号,这也是awk的内建变量,它表示引用相应的字段,因为我们这里第一行只有三个字段,所以只引用到了$3。除此之外另一个这里没有出现的$0,它表示引用当前记录(当前行)的全部内容。
$ awk -F‘.‘ ‘{
> if(NR==2){
> print $1 "\t" $2 "\t" $3
> }}‘ test
# 或者
$ awk ‘
> BEGIN{
> FS="."
> OFS="\t" # 如果写为一行,两个动作语句之间应该以";"号分开
> }{
> if(NR==2){
> print $1, $2, $3
> }}‘ test
一、Linux 上的软件安装
通常 Linux 上的软件安装主要有三种方式:
APT是Advance Packaging Tool(高级包装工具)的缩写,是Debian及其派生发行版的软件包管理器,APT可以自动下载,配置,安装二进制或者源代码格式的软件包,因此简化了Unix系统上管理软件的过程。APT最早被设计成dpkg的前端,用来处理deb格式的软件包。现在经过APT-RPM组织修改,APT已经可以安装在支持RPM的系统管理RPM包。这个包管理器包含以
apt-开头的的多个工具,如apt-getapt-cacheapt-cdrom等,在Debian系列的发行版中使用。
标签:
原文地址:http://www.cnblogs.com/KG35/p/4824413.html