标签:
【所有参考资料皆来源与实验楼,特此声明】
【第六课】
文件打包与压缩
实验介绍
Linux 上常用的 压缩/解压 工具,介绍了 zip,rar,tar 的使用。
一、文件打包和解压缩
在讲 Linux 上的解压缩工具之前,有必要先了解以下常见常用的压缩包文件格式。在 Windows 上我们最常见的不外乎这三种*.zip,*.rar,*.7z后缀的压缩文件,而在 Linux 上面常见常用的除了以上这三种外,还有*.gz,*.xz,*.bz2,*.tar,*.tar.gz,*.tar.xz,*tar.bz2,简单介绍如下:
|
文件后缀名 |
说明 |
|
*.zip |
zip程序打包压缩的文件 |
|
*.rar |
rar程序压缩的文件 |
|
*.7z |
7zip程序压缩的文件 |
|
*.tar |
tar程序打包,未压缩的文件 |
|
*.gz |
gzip程序(GNU zip)压缩的文件 |
|
*.xz |
xz程序压缩的文件 |
|
*.bz2 |
bzip2程序压缩的文件 |
|
*.tar.gz |
tar打包,gzip程序压缩的文件 |
|
*.tar.xz |
tar打包,xz程序压缩的文件 |
|
*tar.bz2 |
tar打包,bzip2程序压缩的文件 |
|
*.tar.7z |
tar打包,7z程序压缩的文件 |
讲了这么多种压缩文件,这么多个命令,不过我们一般只需要掌握几个命令即可,包括zip,rar,tar。下面会依次介绍这几个命令及对应的解压命令。
1.zip压缩打包程序
$ zip -r -q -o shiyanlou.zip /home/shiyanlou
$ du -h shiyanlou.zip
$ file shiyanlou.zip
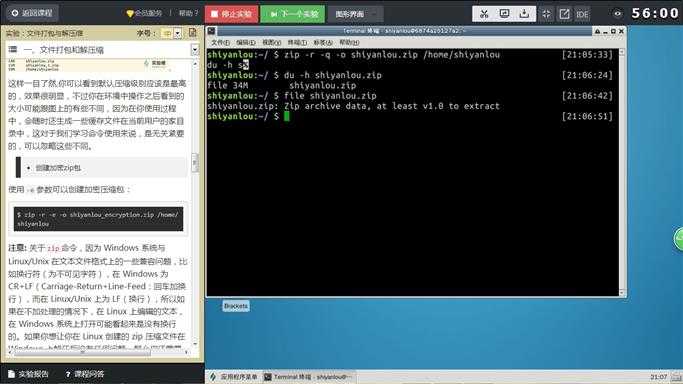
上面命令将 shiyanlou 的 home 目录打包成一个文件,并查看了打包后文件的大小和类型。第一行命令中,-r参数表示递归打包包含子目录的全部内容,-q参数表示为安静模式,即不向屏幕输出信息,-o,表示输出文件,需在其后紧跟打包输出文件名。后面使用du命令查看打包后文件的大小(后面会具体说明该命令)。
$ zip -r -9 -q -o shiyanlou_9.zip /home/shiyanlou -x ~/*.zip
$ zip -r -1 -q -o shiyanlou_1.zip /home/shiyanlou -x ~/*.zip
这里添加了一个参数用于设置压缩级别-[1-9],1表示最快压缩但体积大,9表示体积最小但耗时最久。最后那个-x是为了排除我们上一次创建的 zip 文件,否则又会被打包进这一次的压缩文件中,注意:这里只能使用绝对路径,否则不起作用。
我们再用du命令分别查看默认压缩级别、最低、最高压缩级别及未压缩的文件的大小:
$ du -h -d 0 *.zip ~ | sort
通过man 手册可知:
这样一目了然,你可以看到默认压缩级别应该是最高的,效果很明显,不过你在环境中操作之后看到的大小可能跟图上的有些不同,因为在你使用过程中,会随时还生成一些缓存文件在当前用户的家目录中,这对于我们学习命令使用来说,是无关紧要的,可以忽略这些不同。
使用-e参数可以创建加密压缩包:
$ zip -r -e -o shiyanlou_encryption.zip /home/shiyanlou
注意: 关于zip命令,因为 Windows 系统与 Linux/Unix 在文本文件格式上的一些兼容问题,比如换行符(为不可见字符),在 Windows 为 CR+LF(Carriage-Return+Line-Feed:回车加换行),而在 Linux/Unix 上为 LF(换行),所以如果在不加处理的情况下,在 Linux 上编辑的文本,在 Windows 系统上打开可能看起来是没有换行的。如果你想让你在 Linux 创建的 zip 压缩文件在 Windows 上解压后没有任何问题,那么你还需要对命令做一些修改:
$ zip -r -l -o shiyanlou.zip /home/shiyanlou
需要加上-l参数将LF转换为CR+LF来达到以上目的。
2.使用unzip命令解压缩zip文件
将shiyanlou.zip解压到当前目录:
$ unzip shiyanlou.zip
使用安静模式,将文件解压到指定目录:
$ unzip -q shiyanlou.zip -d ziptest
上述指定目录不存在,将会自动创建。如果你不想解压只想查看压缩包的内容你可以使用-l参数:
$ unzip -l shiyanlou.zip
注意: 使用unzip解压文件时我们同样应该注意兼容问题,不过这里我们关心的不再是上面的问题,而是中文编码的问题,通常 Windows 系统上面创建的压缩文件,如果有有包含中文的文档或以中文作为文件名的文件时默认会采用 GBK 或其它编码,而 Linux 上面默认使用的是 UTF-8 编码,如果不加任何处理,直接解压的话可能会出现中文乱码的问题(有时候它会自动帮你处理),为了解决这个问题,我们可以在解压时指定编码类型。
使用-O(英文字母,大写o)参数指定编码类型:
unzip -O GBK 中文压缩文件.zip
3.rar打包压缩命令
rar也是 Windows 上常用的一种压缩文件格式,在 Linux 上可以使用rar和unrar工具分别创建和解压 rar 压缩包。
$ sudo apt-get update
$ sudo apt-get install rar unrar
$ rm *.zip
$ rar a shiyanlou.rar .
上面的命令使用a参数添加一个目录~到一个归档文件中,如果该文件不存在就会自动创建。
注意:rar 的命令参数没有-,如果加上会报错。
$ rar d shiyanlou.rar .zshrc
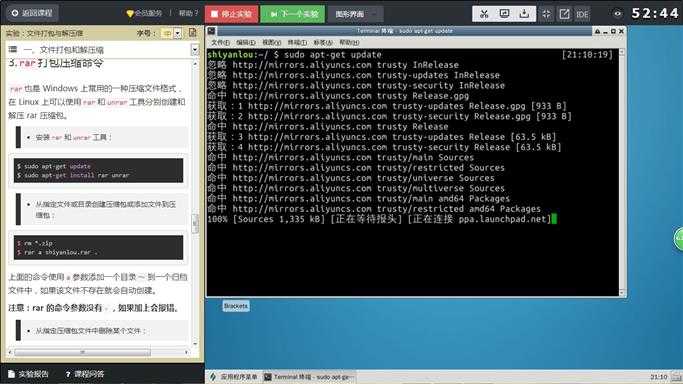
$ rar l shiyanlou.rar
全路径解压:
$ unrar x shiyanlou.rar
去掉路径解压:
$ mkdir tmp
$ unrar e shiyanlou.rar tmp/
rar命令参数非常多,上面只涉及了一些基本操作
4.tar打包工具
在 Linux 上面更常用的是tar工具,tar 原本只是一个打包工具,只是同时还是实现了对 7z,gzip,xz,bzip2 等工具的支持,这些压缩工具本身只能实现对文件或目录(单独压缩目录中的文件)的压缩,没有实现对文件的打包压缩,所以我们也无需再单独去学习其他几个工具,tar 的解压和压缩都是同一个命令,只需参数不同,使用比较方便。
下面先掌握tar命令一些基本的使用方式,即不进行压缩只是进行打包(创建归档文件)和解包的操作。
$ tar -cf shiyanlou.tar ~
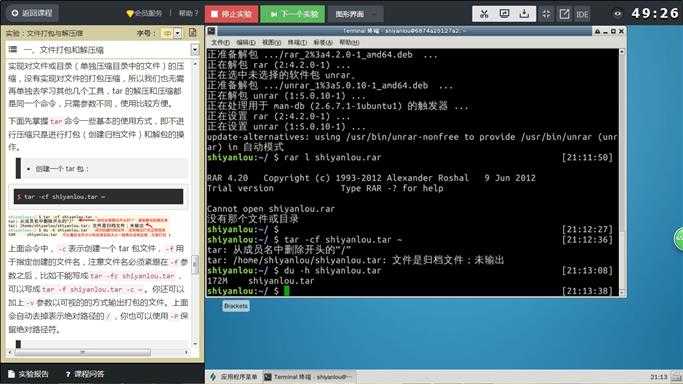
上面命令中,-c表示创建一个 tar 包文件,-f用于指定创建的文件名,注意文件名必须紧跟在-f参数之后,比如不能写成tar -fc shiyanlou.tar,可以写成tar -f shiyanlou.tar -c ~。你还可以加上-v参数以可视的的方式输出打包的文件。上面会自动去掉表示绝对路径的/,你也可以使用-P保留绝对路径符。
$ mkdir tardir
$ tar -xf shiyanlou.tar -C tardir
$ tar -tf shiyanlou.tar
$ tar -cphf etc.tar /etc
对于创建不同的压缩格式的文件,对于tar来说是相当简单的,需要的只是换一个参数,这里我们就以使用gzip工具创建*.tar.gz文件为例来说明。
$ tar -czf shiyanlou.tar.gz ~
$ tar -xzf shiyanlou.tar.gz
现在我们要使用其他的压缩工具创建或解压相应文件只需要更改一个参数即可:
|
压缩文件格式 |
参数 |
|
*.tar.gz |
-z |
|
*.tar.xz |
-J |
|
*tar.bz2 |
-j |
tar 命令的参数很多,不过常用的就是上述这些,需要了解更多你可以查看 man 手册获取更多帮助。
作业
天冷的时候,要是有个火炉就好了。这里有个有趣的程序:
$ sudo apt-get install libaa-bin
# 提示command not found,请自行解决
$ aafire
【第七课】
文件系统操作与磁盘管理
一、简单文件系统操作
1.查看磁盘和目录的容量
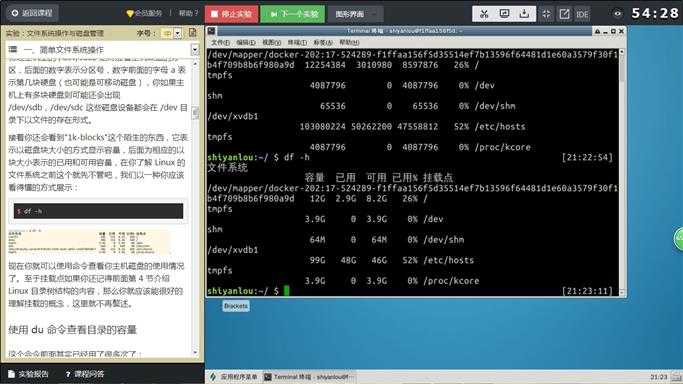
使用 df 命令查看磁盘的容量
$ df
在实验楼的环境中你将看到如下的输出内容:
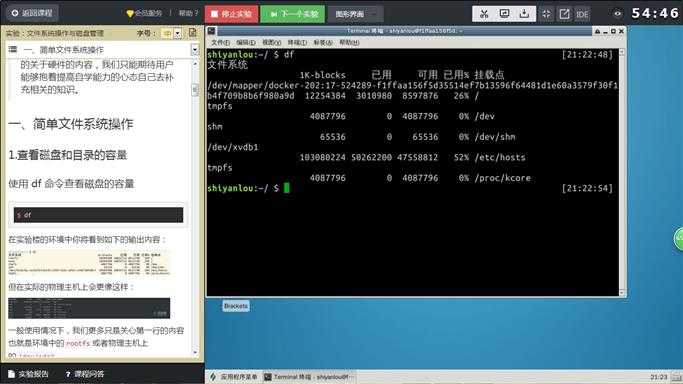
一般使用情况下,我们更多只是关心第一行的内容也就是环境中的rootfs或者物理主机上的/dev/sda2
"rootfs" : (Root File System)它是 Ramfs(Ramfs 是一个非常简单的 Linux 文件系统用于实现磁盘缓存机制作为动态可调整大小的基于 ram 的文件系统)或者 tmpfs 的一个特殊实例,它作为系统启动时内核载入内存之后,在挂载真正的的磁盘之前的一个临时文件系统。通常的主机会在系统启动后用磁盘上的文件系统替换,只是在一些嵌入式系统中会只存在一个 rootfs ,或者像我们目前遇到的情况运行在虚拟环境中共享主机资源的系统也可能会采用这种方式。
物理主机上的 /dev/sda2 是对应着主机硬盘的分区,后面的数字表示分区号,数字前面的字母 a 表示第几块硬盘(也可能是可移动磁盘),你如果主机上有多块硬盘则可能还会出现 /dev/sdb,/dev/sdc 这些磁盘设备都会在 /dev 目录下以文件的存在形式。
接着你还会看到"1k-blocks"这个陌生的东西,它表示以磁盘块大小的方式显示容量,后面为相应的以块大小表示的已用和可用容量,在你了解 Linux 的文件系统之前这个就先不管吧,我们以一种你应该看得懂的方式展示:
$ df -h
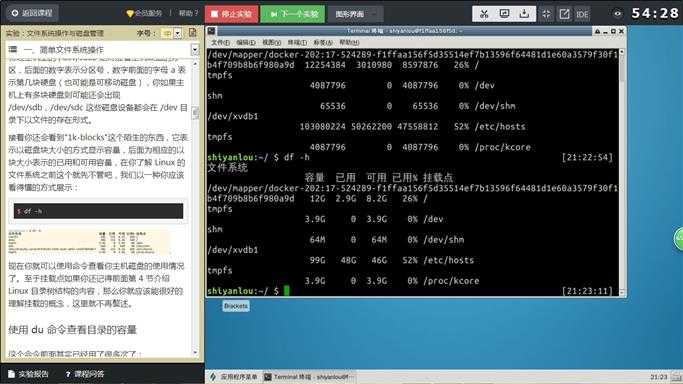
现在你就可以使用命令查看你主机磁盘的使用情况了。至于挂载点如果你还记得前面第 4 节介绍 Linux 目录树结构的内容,那么你就应该能很好的理解挂载的概念,这里就不再赘述。
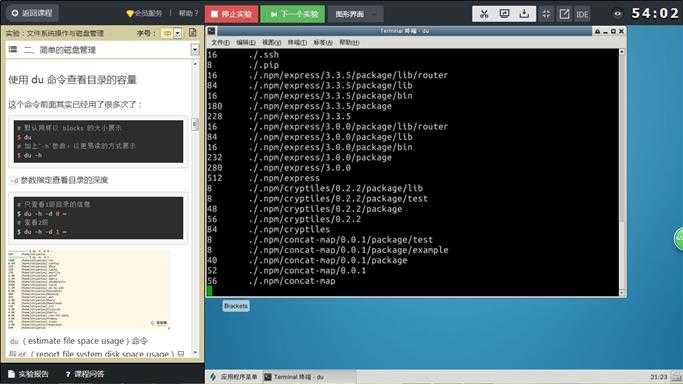
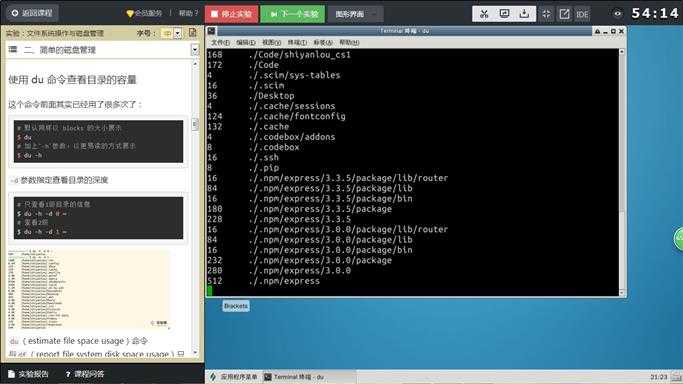
使用 du 命令查看目录的容量
这个命令前面其实已经用了很多次了:
# 默认同样以 blocks 的大小展示
$ du
# 加上`-h`参数,以更易读的方式展示
$ du -h
-d参数指定查看目录的深度
# 只查看1级目录的信息
$ du -h -d 0 ~
# 查看2级
$ du -h -d 1 ~
du(estimate file space usage)命令与df(report file system disk space usage)只用一字只差,首先就希望注意不要弄混淆了,以可以像我这样从man手册中获取命令的完整描述,记全称就不会搞混了。
二、简单的磁盘管理
下面涉及的命令具有一定的危险性,操作不当可能会丢失你的个人数据,初学者建议在虚拟环境中进行操作
通常情况下,这一小节应该直接将如何挂载卸载磁盘,如何格式化磁盘,如何分区,但如你所见,我们的环境中没东西给你挂,也没东西给你格和分,所以首先我们会先创建一个虚拟磁盘来进行后续的练习操作
1.创建虚拟磁盘
dd 命令简介
dd命令用于转换和复制文件,不过它的复制不同于cp。之前提到过关于 Linux 的很重要的一点,一切即文件,在 Linux 上,硬件的设备驱动(如硬盘)和特殊设备文件(如/dev/zero和/dev/random)都像普通文件一样,只要在各自的驱动程序中实现了对应的功能,dd 也可以读取自和/或写入到这些文件。这样,dd也可以用在备份硬件的引导扇区、获取一定数量的随机数据或者空数据等任务中。dd程序也可以在复制时处理数据,例如转换字节序、或在 ASCII 与 EBCDIC 编码间互换。
dd的命令行语句与其他的 Linux 程序不同,因为它的命令行选项格式为选项=值,而不是更标准的--选项 值或-选项=值。dd默认从标准输入中读取,并写入到标准输出中,但可以用选项if(input file,输入文件)和of(output file,输出文件)改变。
我们先来试试用dd命令从标准输入读入用户输入到标准输出或者一个文件:
# 输出到文件
$ dd of=test bs=10 count=1 # 或者 dd if=/dev/stdin of=test bs=10 count=1
# 输出到标准输出
$ dd if=/dev/stdin of=/dev/stdout bs=10 count=1
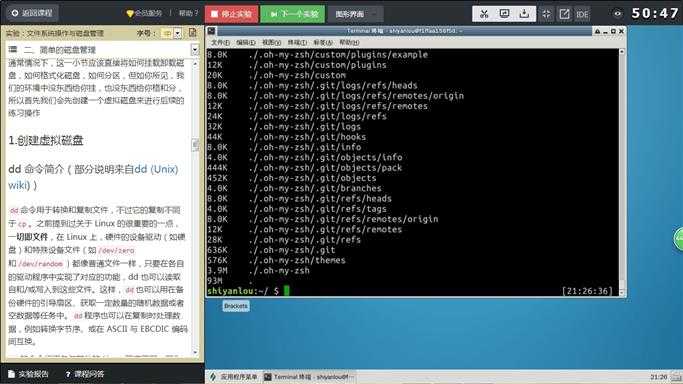
上述命令从标准输入设备读入用户输入(缺省值,所以可省略)然后输出到 test 文件,bs(block size)用于指定块大小(缺省单位为 Byte,也可为其指定如‘K‘,‘M‘,‘G‘等单位),count用于指定块数量。如上图所示,我指定只读取总共 10 个字节的数据,当我输入了“hello shiyanlou”之后加上空格回车总共 16 个字节(一个英文字符占一个字节)内容,显然超过了设定大小。使用和du和cat命令看到的写入完成文件实际内容确实只有 10 个字节(那个黑底百分号表示这里没有换行符),而其他的多余输入将被截取并保留在标准输入。
前面说到dd在拷贝的同时还可以实现数据转换,那下面就举一个简单的例子:将输出的英文字符转换为大写再写入文件:
$ dd if=/dev/stdin of=test bs=10 count=1 conv=ucase
你可以在man文档中查看其他所有转换参数。
使用 dd 命令创建虚拟镜像文件
通过上面一小节,你应该掌握了dd的基本使用,下面就来使用dd命令来完成创建虚拟磁盘的第一步。
从/dev/zero设备创建一个容量为 256M 的空文件:
$ dd if=/dev/zero of=virtual.img bs=1M count=256
$ du -h virtual.img
然后我们要将这个文件格式化(写入文件系统),这里我们要学到一个(准确的说是一组)新的命令来完成这个需求。
使用 mkfs 命令格式化磁盘(我们这里是自己创建的虚拟磁盘镜像)
# 进入磁盘分区模式
$ sudo fdisk virtual.img
在进行操作前我们首先应先规划好我们的分区方案,这里我将在使用 128M(可用 127M 左右)的虚拟磁盘镜像创建一个 30M 的主分区剩余部分为扩展分区包含 2 个大约 45M 的逻辑分区。
最后不要忘记输入w写入分区表。
使用 losetup 命令建立镜像与回环设备的关联
$ sudo losetup /dev/loop0 virtual.img
# 如果提示设备忙你也可以使用其它的回环设备,"ls /dev/loop*"参看所有回环设备
接着再是格式化,我们将其全部格式化为 ext4:
$ sudo mkfs.ext4 -q /dev/mapper/loop0p1
$ sudo mkfs.ext4 -q /dev/mapper/loop0p5
$ sudo mkfs.ext4 -q /dev/mapper/loop0p6
格式化完成后在/media目录下新建四个空目录用于挂载虚拟磁盘:
$ mkdir -p /media/virtualdisk_{1..3}
# 挂载磁盘分区
$ sudo mount /dev/mapper/loop0p1 /media/virtualdisk_1
$ sudo mount /dev/mapper/loop0p5 /media/virtualdisk_2
$ sudo mount /dev/mapper/loop0p6 /media/virtualdisk_3
# 卸载磁盘分区
$ sudo umount /dev/mapper/loop0p1
$ sudo umount /dev/mapper/loop0p5
$ sudo umount /dev/mapper/loop0p6
然后:
$ df -h
作业
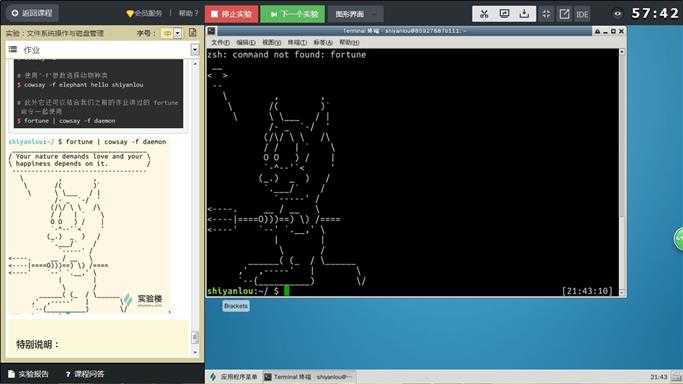
cowsay命令,可以让你在终端里以一种动物说话的形式打印出一段话。
# 安装
$ sudo apt-get install cowsay
#默认是一只牛
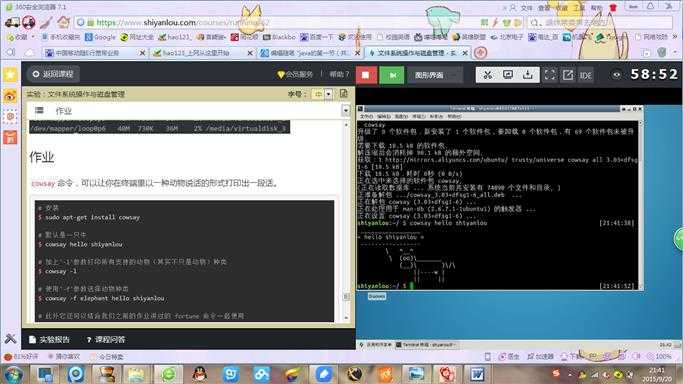
$ cowsay hello shiyanlou
# 加上‘-l‘参数打印所有支持的动物(其实不只是动物)种类
$ cowsay -l
# 使用‘-f‘参数选择动物种类
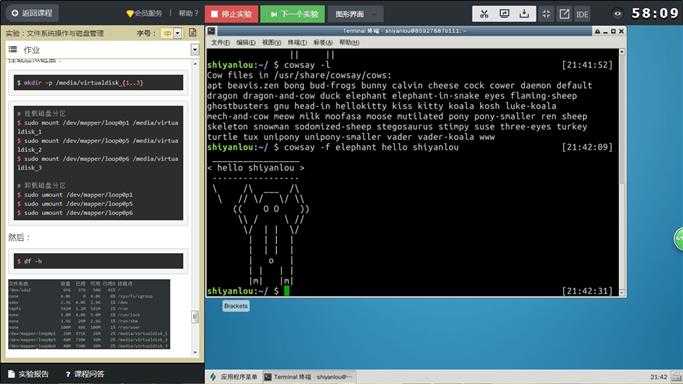
$ cowsay -f elephant hello shiyanlou
# 此外它还可以结合我们之前的作业讲过的 fortune 命令一起使用
$ fortune | cowsay -f daemon
【遇到的问题】1.加载过慢
2.找不到文件夹
【解决办法】1.刷新
2.重开虚拟环境,因为沿用上一课的环境导致这节课内容无法完成,重开即可
【第八课】
命令执行顺序控制与管道
实验介绍
顺序执行、选择执行、管道、cut 命令、grep 命令、wc 命令、sort 命令等,高效率使用 Linux 的技巧。
一、命令执行顺序的控制
1.顺序执行多条命令
通常情况下,我们每次只能在终端输入一条命令,按下回车执行,执行完成后,我们再输入第二条命令,然后再按回车执行…… 你可能会遇到如下使用场景:我需要使用apt-get安装一个软件,然后安装完成后立即运行安装的软件(或命令工具),又恰巧你的主机才更换的软件源还没有更新软件列表(比如之前我们的环境中,每次重新开始实验就得sudo apt-get update,现在已经没有这个问题了),那么你可能会有如下一系列操作:
$ sudo apt-get update
# 等待——————————然后输入下面的命令
$ sudo apt-get install some-tool
# 等待——————————然后输入下面的命令
$ some-tool
这时你可能就会想要是我可以一次性输入完,让它自己去一次执行各命令就好了,这就是我们这一小节要解决的问题。
简单的顺序执行你可以使用;来完成,比如上述操作你可以:
$ sudo apt-get update;sudo apt-get install some-tool;some-tool
# 让它自己运行
2.有选择的执行命令
关于上面的操作,不知你有没有思考过一个问题,如果我们在让它自动顺序执行命令时,前面的命令执行不成功,而后面的命令又依赖与上一条命令的结果,那么就会造成花了时间,最终却得到一个错误的结果,而且有时候直观的看你还无法判断结果是否正确。那么我们需要能够有选择性的来执行命令,比如上一条命令执行成功才继续下一条,或者不成功又该做出其它什么处理,比如我们使用which来查找是否安装某个命令,如果找到就执行该命令,否则什么也不做(虽然这个操作没有什么实际意义,但可帮你更好的理解一些概念):
$ which cowsay>/dev/null && cowsay -f head-in ohch~
你如果没有安装cowsay,你可以先执行一次上述命令,你会发现什么也没发生,你再安装好之后你再执行一次上述命令,你也会发现一些惊喜。
上面的&&就是用来实现选择性执行的,它表示如果前面的命令执行结果(不是表示终端输出的内容,而是表示命令执行状态的结果)返回0则执行后面的,否则不执行,你可以从$?环境变量获取上一次命令的返回结果:
学习过 C 语言的用户应该知道在 C 语言里面&&表是逻辑与,而且还有一个||表示逻辑或,同样 Shell 也有一个||,它们的区别就在于,shell中的这两个符号除了也可用于表示逻辑与和或之外,就是可以实现这里的命令执行顺序的简单控制。||在这里就是与&&相反的控制效果,当上一条命令执行结果为≠0($?≠0)时则执行它后面的命令:
$ which cowsay>/dev/null || echo "cowsay has not been install, please run ‘sudo apt-get install cowsay‘ to install"
除了上述基本的使用之外,我们还可以结合这&&和||来实现一些操作,比如:
$ which cowsay>/dev/null && echo "exist" || echo "not exist"
我画个流程图来解释一下上面的流程:
思考
上面我们讲到将&&和||结合起来使用,那么是否以任意顺序都行?比如上面我们是&&在前||在后,反过来可以么?会不会有问题?
二、管道
管道是什么,管道是一种通信机制,通常用于进程间的通信(也可通过socket进行网络通信),它表现出来的形式就是将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)。
管道又分为匿名管道和具名管道(这里将不会讨论在源程序中使用系统调用创建并使用管道的情况,它与命令行的管道在内核中实际都是采用相同的机制)。我们在使用一些过滤程序时经常会用到的就是匿名管道,在命令行中由|分隔符表示,|在前面的内容中我们已经多次使用到了。具名管道简单的说就是有名字的管道,通常只会在源程序中用到具名管道。下面我们就将通过一些常用的可以使用管道的"过滤程序"来帮助你熟练管道的使用。
1.试用
先试用一下管道,比如查看/etc目录下有哪些文件和目录,使用ls命令来查看:
$ ls -al /etc
有太多内容,屏幕不能完全显示,这时候可以使用滚动条或快捷键滚动窗口来查看。不过这时候可以使用管道:
$ ls -al /etc | less
通过管道将前一个命令(ls)的输出作为下一个命令(less)的输入,然后就可以一行一行地看。
2.cut 命令,打印每一行的某一字段
打印/etc/passwd文件中以:为分隔符的第1个字段和第6个字段分别表示用户名和其家目录:
$ cut /etc/passwd -d ‘:‘ -f 1,6
打印/etc/passwd文件中每一行的前N个字符:
# 前五个(包含第五个)
$ cut /etc/passwd -c -5
# 前五个之后的(包含第五个)
$ cut /etc/passwd -c 5-
# 第五个
$ cut /etc/passwd -c 5
# 2到5之间的(包含第五个)
$ cut /etc/passwd -c 2-5
3.grep 命令,在文本中或 stdin 中查找匹配字符串
grep命令是很强大的,也是相当常用的一个命令,它结合正则表达式可以实现很复杂却很高效的匹配和查找,不过在学习正则表达式之前,这里介绍它简单的使用,而关于正则表达式后面将会有单独一小节介绍到时会再继续学习grep命令和其他一些命令。
grep命令的一般形式为:
grep [命令选项]... 用于匹配的表达式 [文件]...
还是先体验一下,我们搜索/home/shiyanlou目录下所有包含"shiyanlou"的所有文本文件,并显示出现在文本中的行号:
$ grep -rnI "shiyanlou" ~
-r 参数表示递归搜索子目录中的文件,-n表示打印匹配项行号,-I表示忽略二进制文件。这个操作实际没有多大意义,但可以感受到grep命令的强大与实用。
当然也可以在匹配字段中使用正则表达式,下面简单的演示:
# 查看环境变量中以"yanlou"结尾的字符串
$ export | grep ".*yanlou$"
其中$就表示一行的末尾。
4. wc 命令,简单小巧的计数工具
wc 命令用于统计并输出一个文件中行、单词和字节的数目,比如输出/etc/passwd文件的统计信息:
$ wc /etc/passwd
分别只输出行数、单词数、字节数、字符数和输入文本中最长一行的字节数:
# 行数
$ wc -l /etc/passwd
# 单词数
$ wc -w /etc/passwd
# 字节数
$ wc -c /etc/passwd
# 字符数
$ wc -m /etc/passwd
# 最长行字节数
$ wc -L /etc/passwd
注意:对于西文字符来说,一个字符就是一个字节,但对于中文字符一个汉字是大于2个字节的,具体数目是由字符编码决定的
再来结合管道来操作一下,下面统计 /etc 下面所有目录数:
$ ls -dl /etc/*/ | wc -l
5.sort 排序命令
这个命令前面我们也是用过多次,功能很简单就是将输入按照一定方式排序,然后再输出,它支持的排序有按字典排序,数字排序,按月份排序,随机排序,反转排序,指定特定字段进行排序等等。
默认为字典排序:
$ cat /etc/passswd | sort
反转排序:
$ cat /etc/passwd | sort -r
按特定字段排序:
$ cat /etc/passwd | sort -t‘:‘ -k 3
上面的-t参数用于指定字段的分隔符,这里是以":"作为分隔符;-k 字段号用于指定对哪一个字段进行排序。这里/etc/passwd文件的第三个字段为数字,默认情况下是一字典序排序的,如果要按照数字排序就要加上-n参数:
$ cat /etc/passwd | sort -t‘:‘ -k 3 -n
6. uniq 去重命令
uniq命令可以用于过滤或者输出重复行。
我们可以使用history命令查看最近执行过的命令(实际为读取${SHELL}_history文件,如我们环境中的~/.zsh_history文件),不过你可能只想查看使用了那个命令而不需要知道具体干了什么,那么你可能就会要想去掉命令后面的参数然后去掉重复的命令:
$ history | cut -c 8- | cut -d ‘ ‘ -f 1 | uniq
然后经过层层过滤,你会发现确是只输出了执行的命令那一列,不过去重效果好像不明显,仔细看你会发现它趋势去重了,只是不那么明显,之所以不明显是因为uniq命令只能去连续重复的行,不是全文去重,所以要达到预期效果,我们先排序:
$ history | cut -c 8- | cut -d ‘ ‘ -f 1 | sort | uniq
# 或者$ history | cut -c 8- | cut -d ‘ ‘ -f 1 | sort -u
这就是 Linux/UNIX 哲学吸引人的地方,大繁至简,一个命令只干一件事却能干到最好。
# 输出重复过的行(重复的只输出一个)及重复次数
$ history | cut -c 8- | cut -d ‘ ‘ -f 1 | sort | uniq -dc
# 输出所有重复的行
$ history | cut -c 8- | cut -d ‘ ‘ -f 1 | sort | uniq -D
文本处理命令还有很多,下一节将继续介绍一些常用的文本处理的命令。
作业
使用以前介绍过的方法,安装aview和imagemagick,然后用asciiview命令显示图片,使用方法可以用 man 命令查看。
标签:
原文地址:http://www.cnblogs.com/20135213lhj/p/4824322.html