标签:
这是Kaihua Zhang发表在ECCV2012的paper,文中提出了一种基于压缩感知(compressive sensing)的单目标跟踪算法,该算法利用满足压缩感知(compressive sensing)的RIP(restricted isometry property)条件的随机测量矩阵(random measurement matrix)对多尺度(multiple scale)的图像特征(features)进行降维,然后通过朴素贝叶斯分类器(naive Bayes classifier)对特征进行分类从而预测目标位置。
首先介绍下paper涉及的知识点:
1、随机投影(Random Projection)
通过矩阵R(m*n维)将高维图像空间的x(m维)投影到低维空间v(n维)表示为:
v=Rx (n<<m)
这就是我们常说的降维,但是降维不能只是降低维度,还要尽最大可能的保留高维度的信息,如何做呢?Johnso-Lindenstrauss指出如果将向量空间中两个点能够投影到一个随机选取的合适的高维度的子空间中,则能够以高概率保留两点之间的距离关系,上一句中的“合适的高纬度”要比原先的维度要小,而且Baraniuk在论文中证明了满足Johnso-Lindenstrauss推论的随机矩阵同时满足compressive sensing的restricted isometry property(RIP)条件,所以如果随机矩阵R满足Johnso-Lindenstrauss推论,并且x是诸如语音或者图像这种可压缩的信号的话,我们就能以最小误差从低维的v中高概率的重构出高维的x。
2随机测量矩阵(random measurement matrix)
一个典型的满足RIP条件的随机测量矩阵是随机高斯矩阵(random Gaussian matrix)R,(R中的每个值rij服从N(0,1)),但是该矩阵有个缺点即一般是稠密的(dense),这样会导致在存取和计算时开销太大而难以忍受。
paper的亮点在于找到一个非常稀疏的随机测量矩阵


Achlioptas证明当s=2 or3时该矩阵满足Johnso-Lindenstrauss推论,而s=3时矩阵是非常稀疏的,因为矩阵中1-1/3=2/3的概率都是0,故减少了2/3的计算开销, paper中设定s=m%4,m为为压缩信号x的维度,这样对于R中的每一行只需要计算c=s(c小于等于4)个元素,所以矩阵的计算复杂度变为O(cn)。同时保存矩阵时只需要考虑非零元素,故空间复杂度也减少很多。
3尺度不变性(scale invariant)
为了处理跟踪中的尺度问题,对于每一个样本,paper中采用一组多尺度矩阵滤波器
对样本进行卷积,滤波器表示如下:
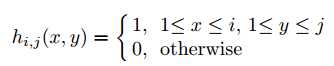
其中i,j分别表示矩形滤波器的宽和高,卷积后一个图像特征的维度为w*h,一共有w*h个滤波器,所以将所有的图像特征 reshape,得到维度为(w*h)2的列向量,然后将这些列向量连接成一个高维的多尺度的图像特征向量,维度为m= (wh)2,m的大小一般在106-1010,直接计算是难以忍受的,然后采用我们之前介绍的随机测量矩阵R将x投影到v上实现降维,说白了就是减少计算量在实际计算时,随机测量矩阵只需要在程序初始化时计算一次,然后矩阵相乘时只考虑非零的乘加,由于每行的非零数小于等于4,所以可以有效的计算矩阵乘法。
4.构建和更新分类器
假设v是独立分布的,通过朴素贝叶斯分类器naive Bayes classifier建模。
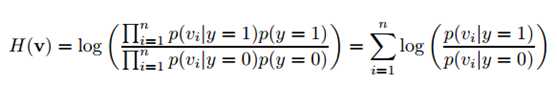
首先假设先验概率,Diaconisand Freedman[3]指出高维随机变量的随机投影几乎满足高斯分布,所以分类器H(v)中的条件分布假设满足
![]()
我们接下来需要做的就是对这四个参数进行建模,每一帧更新分类器即更新上面四个参数
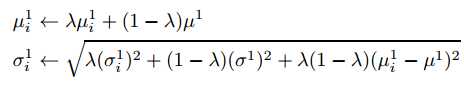
其中lamda>0表示学习速率。均值和方差初始化如下:
tracking的流程图如下所示:
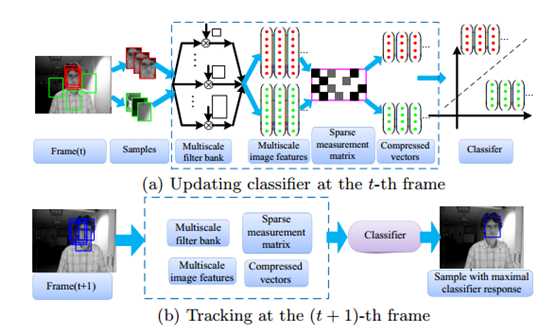
tracking algorithm如下:

1. 在第t帧时,以t-1帧的目标的位置为中心,r为半径,采样得到低纬度的特征。
2. 使用贝叶斯分类器H对采样特征进行分类,响应值最高的为第t帧的目标位置。
3. 确定第t帧的目标位置后在其附近搜集正样本,远离目标位置搜集负样本,更新分类器H用于下一帧目标位置的预测。
我验证了compressive tracking后发现在实际测试时该算法经常出现跟丢或者偏移的情况,在之后发表的跟踪文章的对比结果中也有相似结论,我分析了有以下几点原因:
首先文章采用的类haar特征,总所周知,haar特征比较简单,而且最为广泛的应用是在人脸检测,但是在跟踪诸如行人或者手等变化丰富的物体时该特征表现不尽如人意,所以可以换一些表达更为丰富的特征来提高算法的性能。
其次作者在更新分类器时选取特征时是随机在目标周围的一个小圆中选取正样本,一个圆环中选取负样本,在选择样本时没有考虑样本之间的重要程度,譬如算法中离目标中心近的样本和稍微远一些的样本在分类时的重要性是一样的,这样会导致分类不准确,在预测目标位置是随机在目标周围的一个小圆选取,这样我感觉有可能选择不到正确的位置。
总而言之压缩感知跟踪算法的优点在于快,这是文章的卖点,为了快作者选取了贝叶斯分类器,两个概率直接一除一加得结果,但是随着物体发生遮挡或者外观发生变化时分类器无法及时更新,导致分类的效果下降。
作者的文章作为入门来说是极好不过的,认真阅读之后容易理解,而且还有code直接上手实践,再次感觉作者的工作让我们觉得算法不是如此的高深莫测。
最后说说我的感想吧,目标跟踪作为计算机视觉研究领域的一个重要的研究方向,在最近几年可谓八仙过海,各显神通,各种算法诸如多示例学习的、时空上下文的、卷积神经网络的、结构化SVM的,FFT加速的、线性回归的等等都展示了强大的实力,性能也是一直在飙升,刚看完这篇又出来一篇,感觉应接不暇,脑子要爆炸的赶脚,但是让我有更大的兴趣去学习,之后我会把最近读的一些论文理解放上来和大家分享,如果有什么考虑不周之处还希望大家帮我指出。
大家如果有什么问题欢迎留言一起讨论,我把自己写的ct tracker的c++ code放到了我的github上,大家有兴趣的可以下载来看看。
我的新浪微博:http://weibo.com/1270453892/profile?topnav=1&wvr=6
我的github:https://github.com/pbypby
Real-Time Compressive Tracking,实时压缩感知跟踪算法解读
标签:
原文地址:http://www.cnblogs.com/gavin-vision/p/4828854.html
