标签:
本人根据此文章进行学习:http://blog.jobbole.com/72624/
会不断更新内容主要分为四大模块:
很多会和网上资料一样,主要是自己学习不断梳理资料,追求:提及精华
1)副本集概念:
副本集合(Replica Sets),是一个基于主/从复制机制的复制功能,但增加了自动故障转移和恢复特性。一个集群最多可以支持7个服务器,并且任意节点都可以是主节点。所有的写操作都被分发到主节点,而读操作可以在任何节点上进行。
2) 副本集的工作原理:

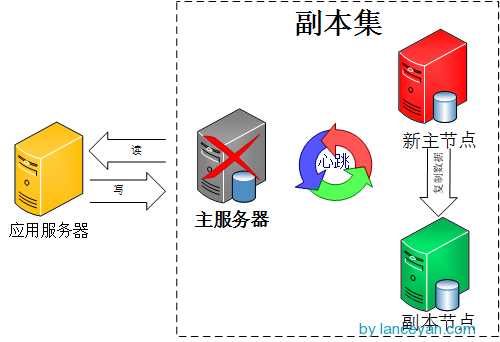
副本集特征:
3)准备环境:
Master ip:192.168.30.131
Slave1 ip:192.168.30.132
Slave2 ip:192.168.30.134
4)在每台机器上建立mongodb副本集测试文件夹
#存放整个mongodb文件
mkdir–p /data/mongodbtest/replset
#存放mongodb数据文件
mkdir/data/mongodbtest/replset/data
#进入mongodb文件夹
cd /data/mongodbtest
5)安装mongodb
这里不多说了,看上个文章,还是在/data/mongodbtest/single里
6)在每台机器上启动mongodb
/data/mongodbtest/single/mongodb/bin/mongod --dbpath /data/mongodbtest/replset/data/ --replSetrepset
可以看到控制台上显示副本集还没有配置初始化信息,如下:
[initandlisten] Did not find local replica set configuration document at startup; NoMatchingDocument Did not find replica set configuration document in local.system.replset
7)初始化副本集
在三台中,任意一台机登陆:
/data/mongodbtest/single/mongodb/bin/mongo
/data/mongodbtest/single/mongodb/bin/mongo > use admin; switched to db admin >config={_id:"repset","members:[ 2015-09-22T17:32:38.108+0800 E QUERY SyntaxError: Unexpected token ILLEGAL >config={_id:"repset",members:[ ... {_id:0,host:"192.168.30.131:27017"}, ... {_id:1,host:"192.168.30.132:27017"}, ... {_id:2,host:"192.168.30.134:27017"}] ... }; { "_id" : "repset", "members" : [ { "_id" : 0, "host" : "192.168.30.131:27017" }, { "_id" : 1, "host" : "192.168.30.132:27017" }, { "_id" : 2, "host" : "192.168.30.134:27017" } ] } >rs.initiate(config); { "ok" : 1 } #查看集群节点的状态 repset:PRIMARY>rs.status() { "set" : "repset", "date" : ISODate("2015-09-22T09:38:31.216Z"), "myState" : 1, "members" : [ { "_id" : 0, "name" : "192.168.30.131:27017", "health" : 1, "state" : 2, "stateStr" : "SECONDARY", "uptime" : 23, "optime" : Timestamp(1442914486, 1), "optimeDate" : ISODate("2015-09-22T09:34:46Z"), "lastHeartbeat" : ISODate("2015-09-22T09:38:29.246Z"), "lastHeartbeatRecv" : ISODate("2015-09-22T09:38:29.552Z"), "pingMs" : 1, "configVersion" : 1 }, { "_id" : 1, "name" : "192.168.30.132:27017", "health" : 1, "state" : 2, "stateStr" : "SECONDARY", "uptime" : 27, "optime" : Timestamp(1442914486, 1), "optimeDate" : ISODate("2015-09-22T09:34:46Z"), "lastHeartbeat" : ISODate("2015-09-22T09:38:29.488Z"), "lastHeartbeatRecv" : ISODate("2015-09-22T09:38:30.309Z"), "pingMs" : 0, "configVersion" : 1 }, { "_id" : 2, "name" : "192.168.30.134:27017", "health" : 1, "state" : 1, "stateStr" : "PRIMARY", "uptime" : 507, "optime" : Timestamp(1442914486, 1), "optimeDate" : ISODate("2015-09-22T09:34:46Z"), "electionTime" : Timestamp(1442914683, 1), "electionDate" : ISODate("2015-09-22T09:38:03Z"), "configVersion" : 1, "self" : true } ], "ok" : 1 }
搭建成功
8)测试副本集数据复制功能
主节点上:
repset:PRIMARY> use test; switched to db test repset:PRIMARY>db.testdb.insert({"test1":"restval1"}) WriteResult({ "nInserted" : 1 })
从节点上:
repset:SECONDARY> use test; switched to db test #默认是从主节点读写数据,副本节点上不允许读,需要设置副本节点可以读 repset:SECONDARY>db.getMongo().setSlaveOk(); repset:SECONDARY> show tables; system.indexes testdb
9)测试集群故障功能
这里就不做了,关掉主节点,就切换了,再开启就变成副本节点,自己玩吧。
上述集群的缺点:
因读写数据都是主节点负责,读写压力过大如何解决?
解决方案:
主负责写,副本节点负责读
1)设置读写分离需要先在副本节点SECONDARY 设置setSlaveOk。
2)在程序中设置副本节点负责读操作,如下代码:
public class TestMongoDBReplSetReadSplit { public static void main(String[] args) { try { List<ServerAddress> addresses = new ArrayList<ServerAddress>(); ServerAddress address1 = new ServerAddress("192.168.30.131" , 27017); ServerAddress address2 = new ServerAddress("192.168.30.132" , 27017); ServerAddress address3 = new ServerAddress("192.168.30.134" , 27017); addresses.add(address1); addresses.add(address2); addresses.add(address3); MongoClient client = new MongoClient(addresses); DB db = client.getDB( "test" ); DBCollectioncoll = db.getCollection( "testdb" ); BasicDBObject object = new BasicDBObject(); object.append( "test2" , "testval2" ); //读操作从副本节点读取 ReadPreference preference = ReadPreference. secondary(); DBObjectdbObject = coll.findOne(object, null , preference); System.out .println(dbObject); } catch (Exception e) { e.printStackTrace(); } } }
读参数除了secondary一共还有五个参数:primary、primaryPreferred、secondary、secondaryPreferred、nearest。
primary:默认参数,只从主节点上进行读取操作。
primaryPreferred:大部分从主节点上读取数据,只有主节点不可用时从secondary节点读取数据。
secondary:只从secondary节点上进行读取操作,存在的问题是secondary节点的数据会比primary节点数据“旧”。
secondaryPreferred:优先从secondary节点进行读取操作,secondary节点不可用时从主节点读取数据。
nearest:不管是主节点、secondary节点,从网络延迟最低的节点上读取数据。
上述方案的缺点:
副本节点增多,导致主节点的写压力不断增多?
副本集故障转移,主节点是如何选举的?能否手动干涉下架某一台主节点。
官方说副本集数量最好是奇数,为什么?
mongodb副本集是如何同步的?如果同步不及时会出现什么情况?会不会出现不一致性?
mongodb的故障转移会不会无故自动发生?什么条件会触发?频繁触发可能会带来系统负载加重
标签:
原文地址:http://www.cnblogs.com/lens/p/4830624.html