标签:
如果MongoDB仅仅是一个文档型的数据库,那就没有什么亮点了,然而MongoDB最大优点在于读扩展,热备份,故障恢复以及自动分片(写扩展)。这节系列结束篇就把这些功能介绍一下。
备份复制实现了数据库备份的同时,实现了读写分离,又实现了读操作的负载均衡,即一台主写服务器,多台从属备份和读服务器,并且支持备份和读的集群扩展。其中Replica Sets方式又支持故障切换,当主服务器down掉后会投票选出一台从服务器接替为主服务器实现写操作。而自动分片功能会将原先的集合(表),自动分片到其它服务器上,实现分布式存储,即缓解单表数据量过大,同时又实现写操作的负载均衡。
首先分别在MongoDB目录下分别创建data ,data\dbs(存放数据库文件目录),data\dbs\master(主服务器目录),data\dbs\slave(从服务器目录)。
先以默认端口方式创建一个MongoDB数据库服务
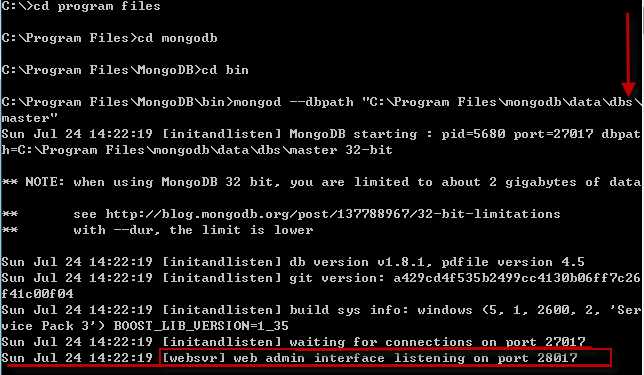
看最后两行,默认创建的MongoDB服务监听的是27017端口,而28017(监听端口+1000) 是web admin interface 监听端口,这个28017就是Http Console监控端口。
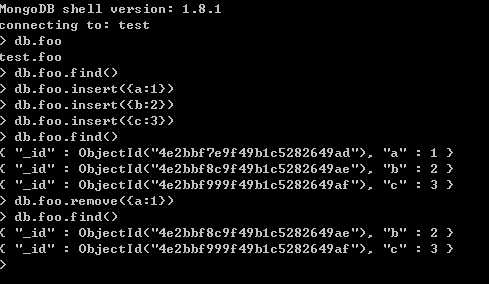
那就访问一下这个http://localhost:28017/地址看看,为了显示效果,先往默认的db.foo 数据添加几条记录
运行mongo.exe (默认连接的是测试库test,里面有个测试集合foo)
访问http console(http://localhost:28017/)查看监控结果
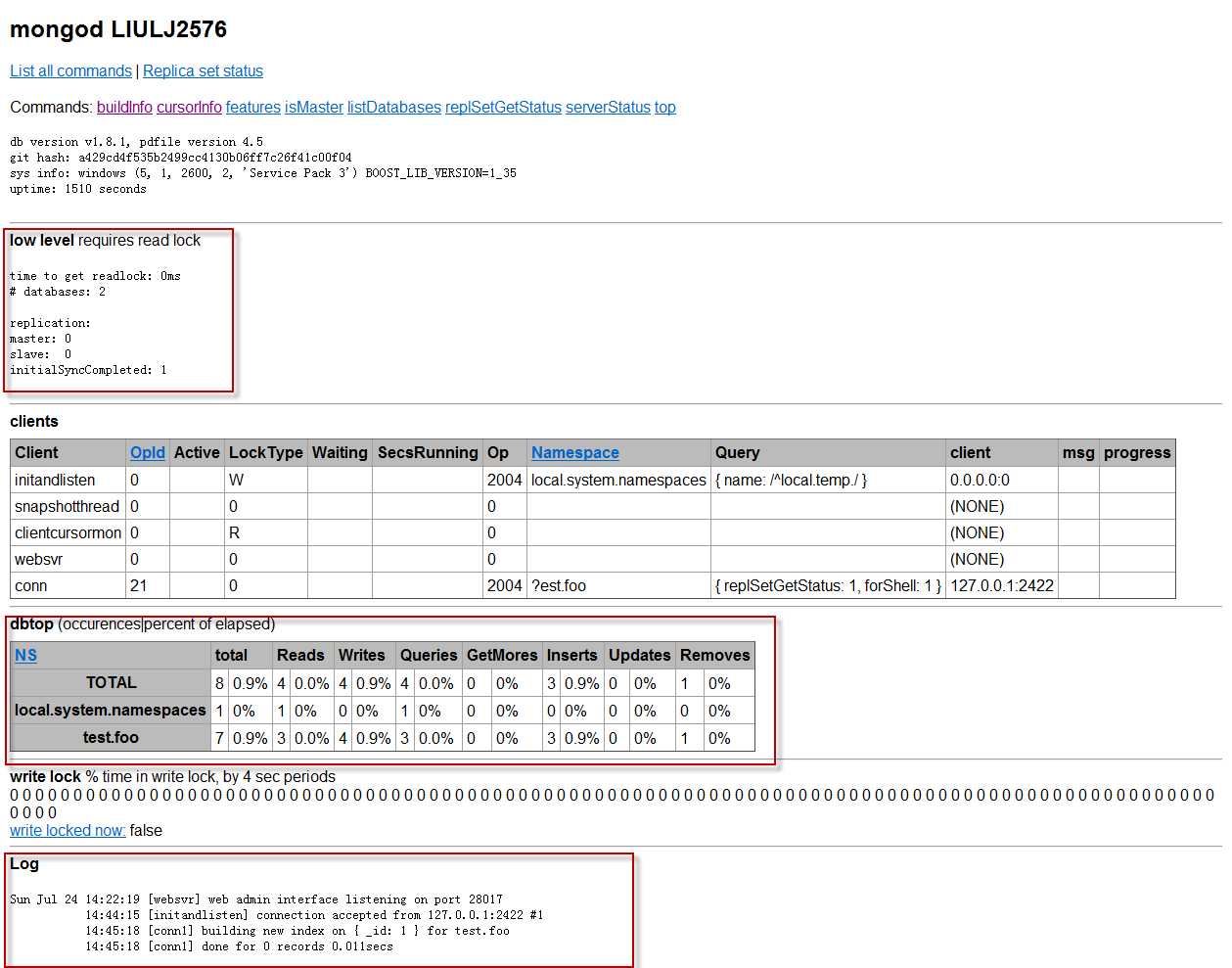
注意红色标记的地方,第一个标记在后面的备份复制会解释,后面是操作日志。
再来通过mongo shell 脚本来查询服务器状态
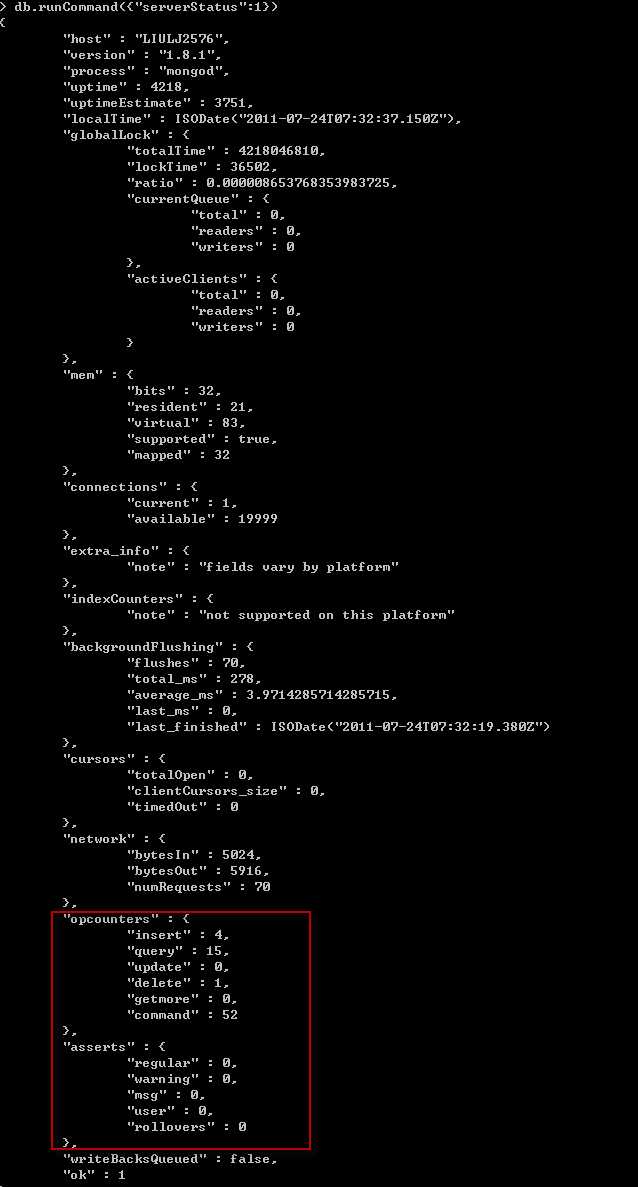
以上是两种简单的监控方式,当然还有更多的方式,可参考官方文档这一节:Monitoring and Diagnostics
不管是什么数据库都会考虑数据的备份复制,故障切换等。当一些数据库服务器读写比高时,我们还要考虑实现这些数据库服务器的负载均衡等功能。我们就来看看MongoDB是怎么实现这些功能。
在创建MongoDB服务的时候,通过--dbpath指定目录就是存放mongdb数据库文件目录,我们可以通过复制这些文件实现数据库的冷备,但是这种方式不太安全。因此在冷备前,要关闭服务器,这个在第一节中介绍过平滑关闭server的命令。
>use admin
>db.shutdownServer()
或者可以通过fsync方式使MongoDB将数据写入缓存中,然后再复制备份
>use admin
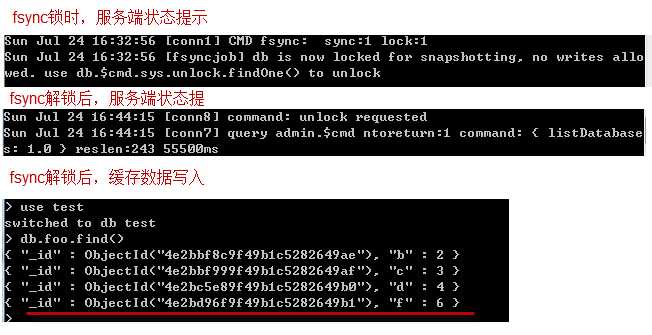
>db.runCommand({"fsync":1,"lock":1})
这个时候我往test.foo 插入了一条数据 f:6 ,在执行db.foo.find()后,并没有查到这条记录,说明记录没有直接写入数据库,而是被缓冲到缓存中了。
备份完后,要解锁(防止这个时候停电或其它原因,导致未缓存中的数据丢失)
>use admin
>db.$cmd.sys.unlock.findOne()
>db.currentOp() 如果currentOp 只返回{"inprog":[]}结果,说明解锁成功
解锁后,缓存中的数据会写入数据库文件中,我们去查询foo结果
上面是冷备的方式,我们可以在不停止服务的情况下,使用MongoDB提供的两个工具来实现备份和恢复。这个两个工具在MongoDB的bin目录下可以看到
mongodump.exe/mongorestor.exe
mongodump.exe备份的原理是通过一次查询获取当前服务器快照,并将快照写入磁盘中,因此这种方式保存的也不是实时的,因为在获取快照后,服务器还会有数据写入,为了保证备份的安全,同样我们还是可以利用fsync锁使服务器数据暂时写入缓存中。
备份命令:
......bin>mongodump -d test -o backup //( backup是备份目录,默认创建到bin目录)
恢复命令: (可以在恢复前往foo表插入一条记录 g:7)
.....bin>mongorestore -d test --drop backup/test/
看一下运行结果:
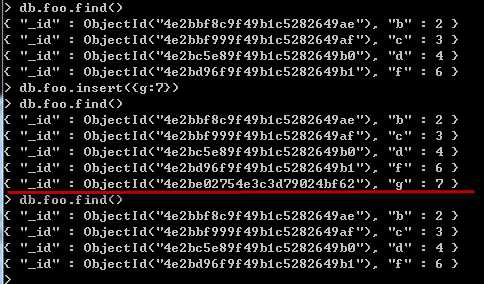
以上是就是mongodb的备份和恢复过程。当数据库文件出现问题或者损坏时,MongoDB还提供了修复数据文件的命令
在启动mongod服务时通过--repair 修改
....bin>mongod --dbpath "C:\Program Files\mongodb\data\dbs\master" --repair
另外我们也可以在mongo shell 中修复正在运行的数据库存
>use test
>db.repairDataBase()
详细细节可参照官网这一节:Backups
我们在来看一下另外二种读扩展式的备份机制
主从复制模式:即一台主写入服务器,多台从备份服务器。从服务器可以实现备份,和读扩展,分担主服务器读密集时压力,充当查询服务器。但是主服务器故障时,我们只能手动去切换备份服务器接替主服务器工作。这种灵活的方式,使扩展多如备份或查询服务器相对比较容易,当然查询服务器也不是无限扩展的,因为这些从服务器定期在轮询读取主服务器的更新,当从服务器过多时反而会对主服务器造成过载。
我们以之前创建的端口为27017做为主服务器,再创建个端口为27018从服务器
重新启动27017为主服务器 --master 主服务器
....bin>mongod --dbpath "C:\Program Files\mongodb\data\dbs\master" --master
创建27018为从服务器 --slave 从服务器 --source 指定主服务器
....bin>mongod --port 27018 --dbpath "C:\Program Files\mongodb\data\dbs\slave27018" --slave --source localhost:27017
主服务器可以通过自己local库的slave集合查看从服务器列表
从服务器可以通过自己local库的source集合查看主服务器信息或维护多个主服务器。 (一个slave服务器可以服务多个master服务器)
或者我们可以通过http console查看状态
详细可参照官网:Master Slave
副本集模式:具有Master-Slave模式所有特点,但是副本集没有固定的主服务器,当初始化的时候会通过多个服务器投票选举出一个主服务器。当主服务器故障时会再次通过投票选举出新的主服务器,而原先的主服务器恢复后则转为从服务器。Replica Sets的在故障发生时自动切换的机制可以极时保证写入操作。
创建多个副本集节点 --replSet (注意要区分大小写,官方建议命名空间使用IP地址)
....bin>mongod --dbpath "C:\Program Files\mongodb\data\dbs\replset27017" --port 27017 --replSet replset/127.0.0.1:27018 ....bin>mongod --dbpath "C:\Program Files\mongodb\data\dbs\replset27018" --port 27018 --replSet replset/127.0.0.1:27017
....bin>mongod --dbpath "C:\Program Files\mongodb\data\dbs\replset27019" --port 27019 --replSet replset/127.0.0.1:27017
首先建立3个是为了投票不会冲突,当服务器为偶数时可能会导致无法正常选举出主服务器。
其次上面3个replset 节点没有全部串联起来,是因为replset 有自检测功可以自动搜索连接其它服务器。
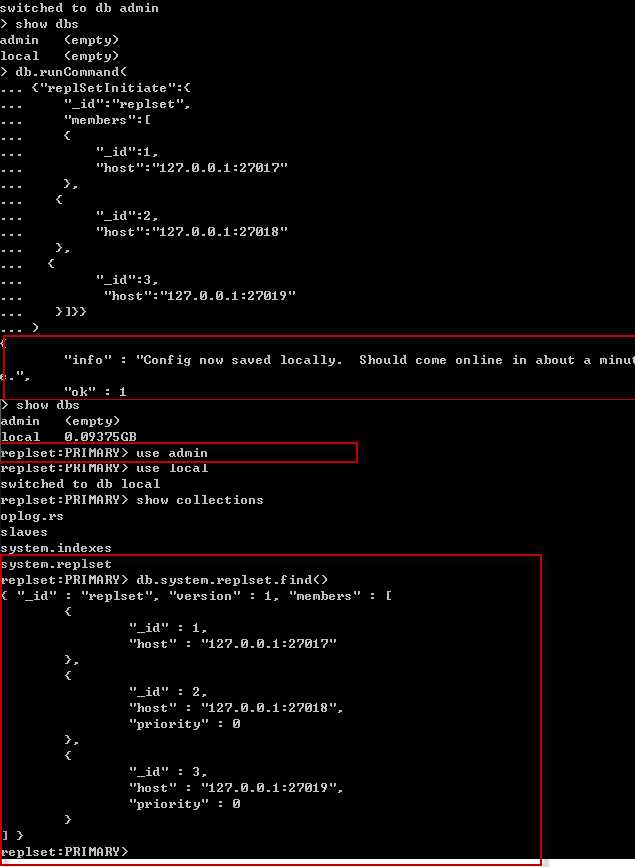
完成上面的工作后,要初始化副本集,随便连接一台服务器执行以下命令 (priority 0~1,被选为主服务器的优先级)
>use admin
>db.runCommand(
{"replSetInitiate":{ "_id":"replset", "members":[ { "_id":1, "host":"127.0.0.1:27017",
"priority":1 }, { "_id":2, "host":"127.0.0.1:27018",
"priority":1 }, { "_id":3, "host":"127.0.0.1:27019",
"priority":1 }]}}
)
查看结果,可以看出127.0.0.1:27017 被自动选为replSet:Primary>
在增加一个从服务器节点
....bin>mongod --dbpath "C:\Program Files\mongodb\data\dbs\replset27020" --port 27020 --replSet replset/127.0.0.1:27017
通过rs.add命令往system.replset添加新的从服务器成员
rs.add("127.0.0.1:27020"); 或者rs.add({"_id":4,"host":"127.0.0.1:27020"})
Replica Sets 介绍就到这里了,详细可参照官网:Replica Sets
oplog记录了增删改操作的记录信息(不包含查询的操作),但是oplog有大小限制,当超过指定大小,oplog会清空之前的记录,重新开始记录。
Master Slave 方式 主服备器会产生 oplog.$main 的日志集合
Replica Sets 方式 所有服务器都会产生oplog.rs 日志集合
两种机制下,所有从服务器都会去轮询主服务器oplog日志,若主服务器的日志较新,就会同步这些新的操作记录。但是这里有个很重要的问题,从服务器由于网络阻塞,死机等原因无法极时同步主服务器oplog记录:一种情况 主服务器oplog不断刷新,这样从服务器永远无法追上主服务器。另外一种情况,刚好主服务器oplog超出大小,清空了之前的oplog,这样从服务器就与主服务器数据就可能会不一致了,这第二种情况,我是推断的,没有证实。
另外要说明一下Replica Sets 备份的缺点,当主服务器发生故障时,一台从服务器被投票选为了主服务器,但是这台从服务的oplog 如果晚于之前的主服务器oplog的话,那之前的主服务器恢复后,会回滚自己的oplog操作和新的主服务器oplog保持一致。由于这个过程是自动切换的,所以在无形之中就导致了部分数据丢失。
自动分片:将原先数据库中集合依据一定的规则切分成若干小块,这些分片小块统一由mongos路由管理,当有请求查询或写入时,路由会依据分片shard key规则找到对应的分片操作。分片解决了写密集操作,用于分散单一写服务器负载。亦或者原先的存储空间不够了,这个时候可能通过分片操作将之后的数据写入其它存储空间上。可以看出,集合的分片和数据库的分表类似,并且每个分片都支持写操作。由于分片的出现,导致数据被分布式的存储到不同的服务器上,当某一服务器出现问题时就可能导致数据丢失,其次路由mongos也会出现问题,另外存储分片的信息的配置服务器也可能会发生问题。当然我们可以利用master salve/Replica sets机制去备份每个分片、Mongos、configs 。如下官网配置图示,即使我们使用服务器交叉备份也需要大量的服务器资源,因此分片是一件极具耗费资源的事情。官网的配置图示
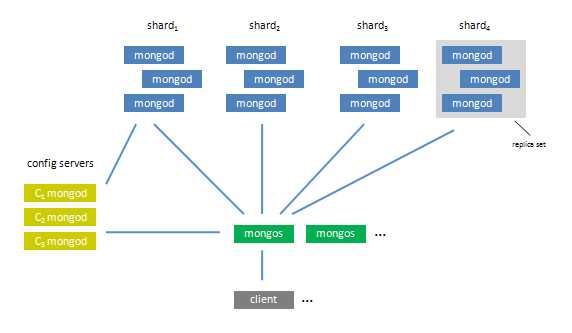
首先路由从config中读取配置信息,发生的分片动态增加也会通过mongos写入config servres中,当client有请求时通过mongos查找到对应的分片。可以看出分片使用的replica set备份模式,而mongos/config servrs则是多个服务器配置。(详细内容见官网:Sharding),下面就手动实现一下分片的过程。(换环境了继续昨天未完成的,前2天在笔记本上)
1)创建configs服务器
....bin>mongod --dbpath "e:\mongodb\data\configs" --port 23017
2)创建mongos服务器 并指定依赖的配置服务器 (mongos依赖于配置服务器,mongos查询的分片信息都存储在configs中)
....bin>mongos --port 25017 --configdb 127.0.0.1:23017
3)创建多个分片服务器 (负责数据存储)
....bin>mongod --port 27017 --dbpath "e:\mongodb\data\dbs\shard27017"
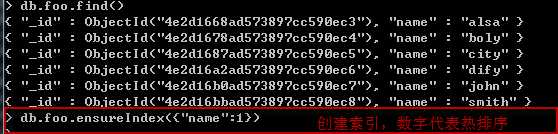
为shard27017分片服务器 创建test库foo集合,并且为foo集创建name索引
4)连接mongos 服务器 添加shard27017分片服务器到configs服务器中
>use admin
>db.runCommand({addshard:"127.0.0.1:27017",allowLoacl:true}) //添加分片服务器,allowLoacl 充许本地部署 默认情况不充许本地部署多个分片的
一旦分片添加成功,在mongos服务器中执行 show dbs就可以看到分片服务器的数据库,并且可以操作分片服务器的数据 ,下面为分片服务器的test库foo集合设置分片以及分片shard key。
>db.runCommand({"enablesharding":"test"}) //对test库启用分片功能
注意:需要分片的集合 的shard key必须是索引键, (我们也可以在mongos为分片foo集合创建索引)
>db.runCommand({"shardcollection":"test.foo","key":{"name":1}}) //数字代表排序
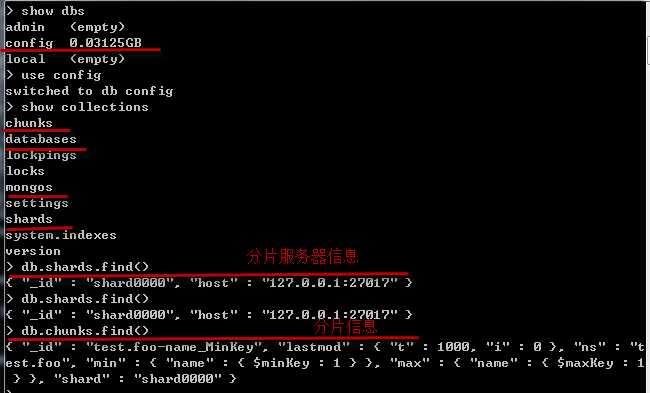
至此自动分片就创建完成了,可以在mongos或configs服务器查询分片信息
当一个分片服务器存储不够时,通过像3)方式继续添加分片服务器,monogs会自实现这些分片的集群工作。
当需要移除分片时运行下面的命令,同时mongos路由会将此分片服务器上的信息移到其它分片上。
>db.runCommand({"removeshard":"127.0.0.1:27017"})
简单的分析一下这个shard key,当不是写密集操作时,而仅仅是因为存储空间不够了,这个shard key我们可以选用一些无上限范围的key,如创建时间等,这样新创建的记录都会写入新的分片服务器上。
当需要使每个分片均匀分布数据时,或者写入密集时,最好选用有一定范围值的key ,当然这个范围不能太小,像性别,真假等,这会导致只自动产生两个分片,所以一定要选择合适的shard key才能达到理想的效果。
MongoDB 拥有强大的读写扩展能力,而且配置比较灵活容易。虽然上面提到的这些功能,每一种都有一定的缺点,但是这些缺点可以通过合理设计归避的。比如备份,因为备份是要消耗一定主服务性器性能,这个时候可以通过备份从服务器,来避免影响到主服务器性能。比如 oplog虽然有大小限制,我们可以通过观察主服务器连续一段时间(周/月/年)更新操作,来确定一个合适的oplog大小,以便从服务器不会丢失对这些操作记录的同步。亦或者每天某段时间强制主服务器的写入缓存操作,以便从服务器可以同步追赶上主服务器。Mongodb入门就到此结束了。具体想了解更多,可以照官方文档和论坛(文档很详细,示例也很简洁,即使命令错语,也能根据提示信息找到解决方法,Mongodb入门还是容易的)。
标签:
原文地址:http://www.cnblogs.com/smallstupidwife/p/4836797.html