标签:
起因是因为这个网站:http://i.youku.com/kmsfan 这个是一个叫做冒险岛的游戏的资讯论坛,以前我经常在里面传视频,现在我不玩这个游戏了,但是很多玩家还是经常到我的网站里面去看视频,所以我觉得有点不好意思,我觉得开发出一款自动上传下载的工具比什么都好,也不耽误我时间。需要准备一些插件,这些插件都可以从Nuget里面找到,比如Newtonsoft.Json啊HtmlAgilityPack ,不过目前为止也只用到了这些东西。还有我没有做youtube视频的下载,我只做了Daum tv的视频解析,因为Insoya视频区大部分都是上传到Daum Tv 的视频。
我先不放代码,大家先要对网站的文件解析有个大概的了解才行吧?我的想法就是:解析当天的视频。因为Insoya是一个韩国网站,所以韩文什么的思密达什么的就不要再吐槽了。这是视频区的地址:http://www.insoya.com/bbs/zboard.php?id=ucc
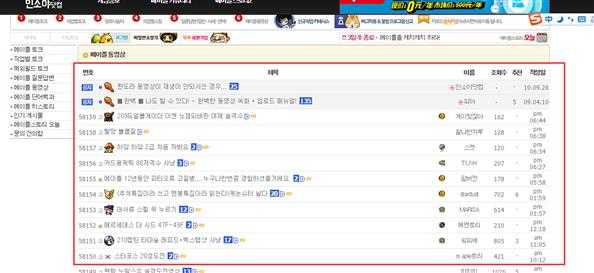
大家可以把手指指向链接,可以发现:视频的ID是一个自增长的。比如:
http://www.insoya.com/bbs/zboard.php?id=ucc&no=58158
http://www.insoya.com/bbs/zboard.php?id=ucc&no=58157
http://www.insoya.com/bbs/zboard.php?id=ucc&no=58156.....略掉了。。。
我们随便点一个进去,如果我们想获得视频的标题啊,URL啊,还有发布日期的话,就可以从里面获取,下面框框就是:
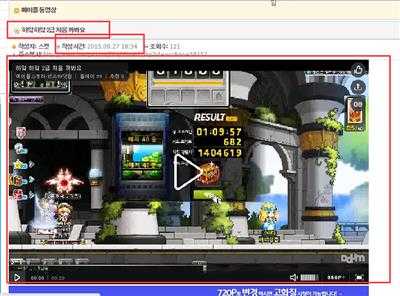
第一,我们从Daum Tv上面获取视频的真实地址,具体可以参考优酷,因为有点难度,视频的地址通常只是给了ID,所以我们还必须获取真实地址:不过StackoverFlow上面我得到了答案 ,哈哈多亏这位老兄。下面是daumTv 的调用API,后面的Vid是视频的ID.
public static string daumAPI = "http://videofarm.daum.net/controller/api/closed/v1_2/IntegratedMovieData.json?vid=";
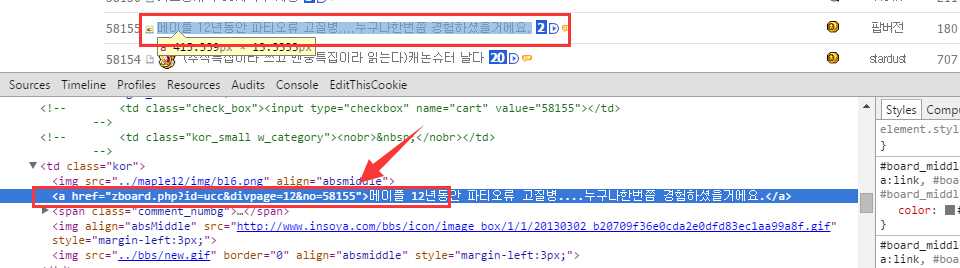
光有了api不行,因为我们是从inosya网站里面去得到视频的真实地址,所以我们还需要有一个解析工具就是HtmlAgilityPack .为此我们需要知道网站是怎么在HTML结点里面存储这些东西的(标题,URL等)。下面几张图可以帮你解惑。下面这张图中指向的是URL,我们想,如果这些ID都是连续的话,那我是不是在第一页获取一个最大的ID,那其他的ID是不是可以都得出来了呢?
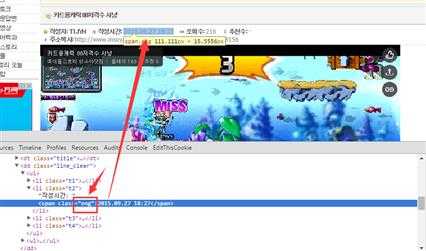
下面图是内容页的,我们可以看到时间是存储到这个CLASS里面的,也许我们有疑问,为什么我要标注CLASS呢,嘿嘿,别急,等下你就知道了。
因为我们是从INSOYA网站里面去获取,INSOYA采用的是iframe方式,所以我们并没有在daumTV里面弄。我的想法是弄到DAUM TV的真实页面地址。

public static string GetDownloadUrls(string videoUrl) { string vid = ""; if (videoUrl == null) { throw new ArgumentNullException("video Url can not be null"); } //是否是标准的daumtv链接,并输出链接地址和视频ID bool isDaumUrl = TryNormalizeDaumTvUrl(videoUrl, out videoUrl,out vid); if (!isDaumUrl) { throw new ArgumentException("It is not a daum Url"); } string vLink = ""; try { //通过DAUM API获得返回的JSON var json = LoadJson(daumAPI + vid); //通过JSON获得文件的真实地址。 vLink = GetVideLink(json); } catch (Exception ex) { } return vLink; }
/// <summary> /// 把从insoya.com中获取的视频地址转换为标准的DAUM TV的视频地址 /// </summary> /// <param name="url"></param> /// <param name="normalizeUrl"></param> /// <returns></returns> public static bool TryNormalizeDaumTvUrl(string url, out string normalizeUrl, out string vId) { url = url.Trim(); string videoId = ""; if (url.IndexOf("videofarm") != -1) { int firstParam = url.IndexOf(‘=‘); int secondParam = url.IndexOf(‘&‘)-1; videoId = url.Substring(firstParam + 1, secondParam - firstParam); url = "http://tvpot.daum.net/v/" + videoId; } vId = videoId; normalizeUrl = url; return true; }
private static JObject LoadJson(string url) { string pageSource = HttpHelper.DownloadString(url); if (!IsVideoValid(pageSource)) { throw new Exception("video not valid"); } return JObject.Parse(pageSource); } public class HttpHelper { public static string DownloadString(string url) { using (var client = new WebClient()) { client.Encoding = System.Text.Encoding.UTF8; return client.DownloadString(url); } } }
首先我们需要得到HTML结点的数据并存储。我的想法是从主页面进去也就是:http://www.insoya.com/bbs/zboard.php?id=ucc 然后再区最大的ID,那样就可以把第一页的所有东西都取到了 o(╯□╰)o。,用的是HtmlAgilityPack 有不懂的自己百度吧。
private static int getMaxIdOfVideo() { HtmlWeb docWeb = new HtmlWeb(); HtmlDocument doc = docWeb.Load("http://www.insoya.com/bbs/zboard.php?id=ucc&page=1&divpage=12"); IList<int> b = new List<int>(); foreach (HtmlNode numbers in doc.DocumentNode.Descendants("td").Where(d=>d.Attributes.Contains("class")&& d.Attributes["class"].Value.Contains("eng w_num"))) { int a; int.TryParse(numbers.InnerText, out a); if (a != 0) { b.Add(a); } } return b.Max(); }
下面的就是最重要的了,就是抓取视频标题,视频URL等,当然我们首先需要建立一个Model然后返回的是这个Model的List.
public class VideoModel { public int VideoId { get; set; } public string VideoUrl { get; set; } public string Title { get; set; } public DateTime PubTime { get; set; } }
public static IList<VideoModel> GrabVideoInfo() { int max=getMaxIdOfVideo(); int staticMax = max; IList<VideoModel> models = new List<VideoModel>(); do { VideoModel model=new VideoModel(); HtmlWeb innerDocWeb = new HtmlWeb(); HtmlDocument innerDoc = innerDocWeb.Load(insoyaUcc + max); //标题 foreach (HtmlNode title in innerDoc.DocumentNode.Descendants("a").Where(d => d.Attributes.Contains("name") && d.Attributes["name"].Value.Contains("pv9"))) { model.Title = title.InnerText; break; } //日期 foreach (HtmlNode title in innerDoc.DocumentNode.Descendants("span").Where(d => d.Attributes.Contains("class") && d.Attributes["class"].Value=="eng")) { DateTime date; DateTime.TryParse(title.InnerText,out date); if (date != null) { model.PubTime = date; break; } } //视频地址 foreach (HtmlNode title in innerDoc.DocumentNode.Descendants("iframe").Where(d => d.Attributes.Contains("title") && d.Attributes["title"].Value.Contains("maplestory_ucc"))) { string oldUrl = title.Attributes["src"].Value; string newUrl = GetDownloadUrls(oldUrl); model.VideoUrl = newUrl; break; } model.VideoId = max; models.Add(model); Console.WriteLine("ID:"+max + " has accomplish grabbed!"); --max; } while (max >= staticMax - 20); return models; }
好了,到此为止我们就可以抓取到视频模型了。
当然了,才完成了30%,还要自动上传视频到优酷,还有要把韩文翻译成最合适的中文,如果我做出来了,会和大家分享的,首先是上传到优酷。有兴趣的同好可以看看优酷开放平台。
C#控制台程序取得INSOYA视频区的视频的真实URL,视频标题,发布时间集合。
标签:
原文地址:http://www.cnblogs.com/kmsfan/p/4842758.html
