标签:
我写过不少文章来讨论为什么移动Web应用程序很慢,这也引起了不少的讨论。但是不幸的是,这些讨论没有像我喜欢的那样的基于事实。
所以我这篇文章的目地就是给这些问题带来一些真正的证据,而不是仅仅过来对骂。在这篇文章的中,你可以看到基准测试(benchmark),可以看到专家的观点,你甚至可以看到非常诚实(honest-to-God)的期刊文章。这篇文章有超过100个引用(不是开玩笑)。我不保证这篇文章能使你信服,甚至不保证这篇文章中的所有内容都是正确的(在这样大规模的文章中做到这一点几乎是不可能的),但是我可以保证这是一篇关于许多iOS开发者都抱有的想法——移动Web应用很慢并且会在可预计的未来继续如此——分析最完备和全面的文章。
现在我要警告你:这是一篇长得吓人的文章,差不多10000字。当然,这是我故意的。我更喜欢好文章,而不是流行的文章。我尝试使得这篇文章成为前者,同时宣扬我认同的风气:我们应该鼓励那些优秀的、基于证据的、有趣的讨论,不鼓励那些诙谐、哗众取宠的评论。
我写这篇的文章,在某种程度上是因为这是话题已经到了一种争论不休的地步。这不是另一篇争论的文章,如果你想看到30秒左右的对骂:“真的!Web应用很渣!”和“谁说的?Web程序挺好!”,那么这篇文章不适合你。另一方面,据我所知,到现在为止还没有一个关于这个话题全面的、正式的、理性的讨论。这篇文章中我尝试去理性地讨论这个激起千层浪的话题,尽管这可能是一个非常愚蠢的想法。这里我给自己辩护一下,我相信这个问题与那些本来可以更好地去讨论却没有这样做的人更有关系,而不是主题本身。
如果你想知道你那些原生代码(native code)程序员朋友为什么在如今开放的网络革命时期还在写着万恶的原生代码,那就把本页面加入书签吧,给自己倒杯咖啡,找出一个下午的时间,找到一个舒服的椅子,然后我们就正式开始吧!
我上一篇博客中写道:基于SunSpider的benchmark给出的数据可以看出当今的移动Web应用很慢。
如果你认为“Web应用程序”就是“一个网页加上一两个按钮”,那么你就可以让那些花哨的benchmark——比如SunSpider——滚一边去。但是如果你认为“Web应用程序”是指“简单的文字处理,简单的照片编辑,本地存储和屏幕之间的切换动画”,那么除非你有想死的心,否则你永远不会愿意在ARM上写Web应用程序。
你应该先读一下那篇文章,但是我还是在这边给你看下benchmark:
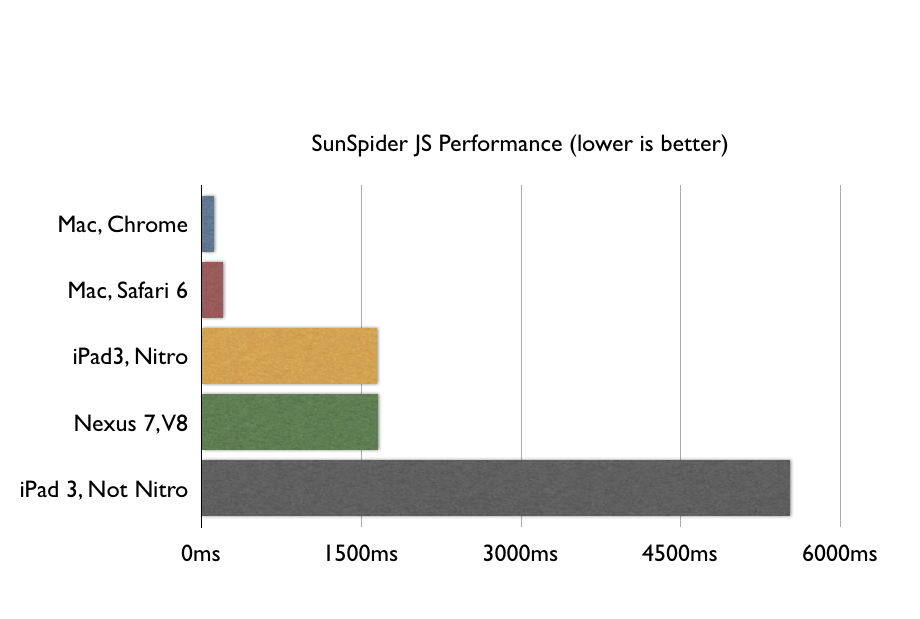
关于这个benchmark,主要三种主要的批评:
1. JS比原生代码要慢并不是什么新鲜事了,每个人在上第一学期的计算机基础课时讨论编译型语言、JIT语言和解释型语言是时候就知道了。问题是JS是不是慢到已经成为你现在所写软件的大问题了,但是像这样的benchmark并不能说明这个问题。
2. JS是很慢,这也的确是个问题,但是它在变得越来越快,所以在不久的未来,我们可以发现它不会那么慢了。所以大家一起学JS吧。
3. 我是Python/PHP/Ruby的服务器端的开发者,我不知道你们在说什么。我知道我的服务器比你们的移动设备快,但是如果我可以自信地保证使用真正的解释型语言写出支持上千个用户的代码,你们难道不能用一个带有高性能JIT的语言写出一个支持单个用户的代码吗?真的有那么难吗?
我有一个相当高的目标,那就是反驳以上所有观点:是的,JS的确是慢到一定程度了;不,它在不久的未来不会变得有多快;不,你在服务器端的编程经验不能正确地映射到移动应用中。
但是真正的问题在于,在所有讨论这个话题的文章里面,基本上没有人真正量化JS到底有多慢,或者提供某种真正有用的比较标准(相对于什么来说慢)。为了纠正这样的情况,我在这篇文章中提出了三种(不仅仅是一种)比较JavaScript性能的办法。我不会说“JS在什么情况下都慢”,而是真正量化它慢的程度,并且将它跟我们再平常编程经验中的事情做对比,这样你就可以根据这个结果结合自己的编程平台做出决定,你也可以自己计算下看看是否JavaScript适合你自己的特定问题。
这是一个好问题。为了回答这个问题,我从Benchmark Game中随意抓取了一个基准测试。然后我找到了一个做同样benchmark的较老的C程序(老到不像很多新程序有一些x86特性)。我在自己的iPhone 4S上分别测试Nitro和LLVM。所有的代码已经传到了Github。
这是一个随机的测试,正如日常生活中运行的代码一样。如果你想要一个更好的实验,可以自己运行。我运行这个实验还有另外一个原因,就是因为其它的实验都不存在LLVM和Nitro的对比。
在这个综合的基准测试中,LLVM一致地比Nitro快4.5倍:
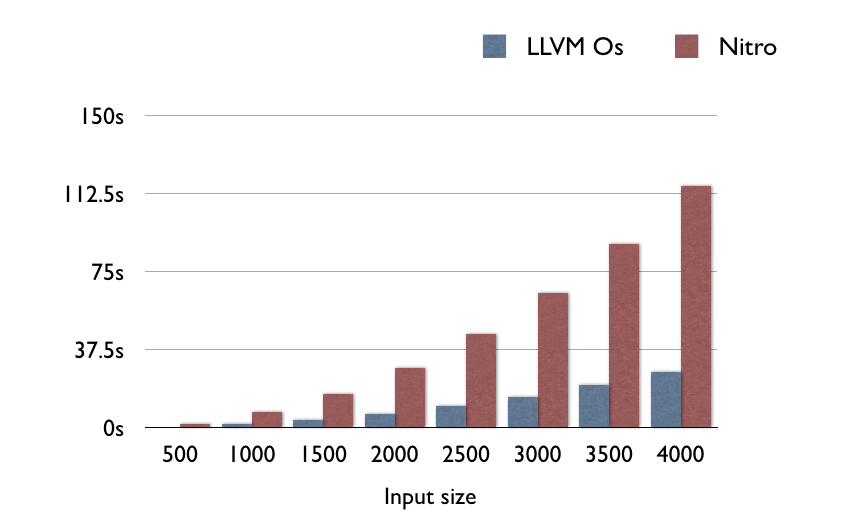
如果你在想“如果是计算密集型(CPU-bound)的功能,本地代码比Nitro JS快多少呢”,那么答案是差不多5倍。这个结果大致上和Benchmark Game在x86/GCC/V8上面的结果一致,那里面的GCC/x86通常比V8/x86快2到9倍。所以结果大致上是正确的,无论是ARM还是x86。
在x86上是足够好了。当渲染一个电子表格的时候,CPU的计算能有多密集呢?其实并不是那么难。问题是,ARM不是x86。
根据GeekBench的结果,最新的MacBook Pro的性能是最新的iPhone性能的10倍。这其实不算太大问题——电子表格没那么复杂。我们可以忍受10%的性能。但是我还要把它除以5?好家伙!我们现在只有桌面性能的2%了。
OK,但是文字处理到底有多难?我们可不可以用一个m68k芯片加上一个协处理器来搞定呢?这是一个可以回答的问题。你可能记不起来,Google Doc的实时协作之前事实上还不是一个正式的功能,后来他们进行了大规模的重写并且在2010年4月份加入到Google Doc里面。我们来看一下2010年浏览器的性能:
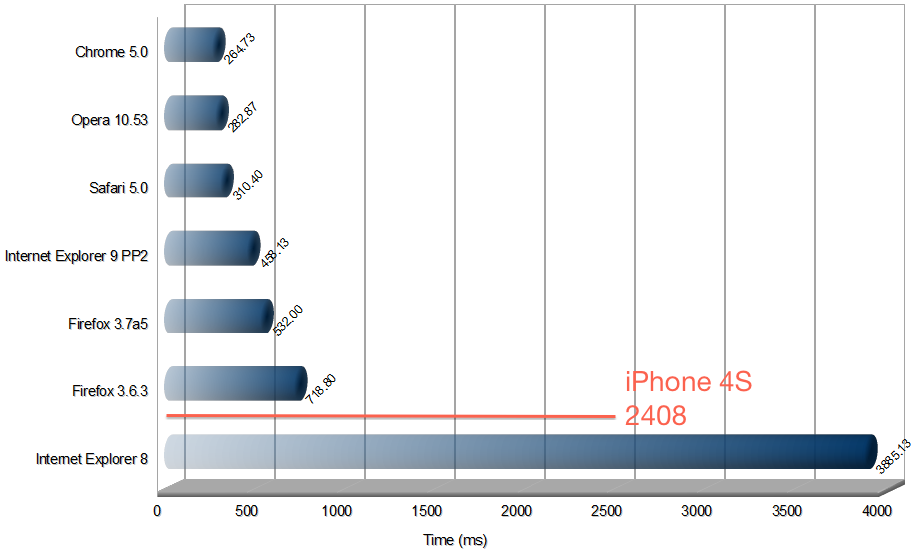
从图中可以清晰地看到,iPhone 4S在Google Docs的实时协作方面完全不是桌面网页浏览器的对手。当然了,它还是可以跟IE8比上一比的。恭喜iPhone 4S,可喜可贺。
我们再看看另外一个正经的JavaScript应用:Google Wave。Wave从来没有支持IE8,因为它实在是太慢了。
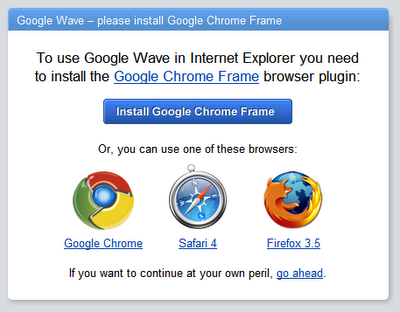
看到这些浏览器比iPhone 4S快多少了吗?
注意,所有支持的浏览器的得分都低于1000,其中那个得分3800的因为太慢了而被忽略了。iPhone得分为2400。差不多和IE8一样,太慢几乎无法运行。
这边要说明的是,在移动设备上实现实时协作是可能的,只是不太可能用JavaScript来实现。原生代码和Web应用的性能差距基本上和Firefox与IE8的性能差距差不多,这么大的差距足以影响正常的工作。
这取决于你怎么理解“接近”了。如果你的C程序运行了10ms,那么一个运行50ms的JavaScript程序差不多是接近C的速度了。如果你的C程序运行了10s,那么一个运行了50s的JavaScript程序对于大多数正常人来说很可能就不是接近C的速度了。
1/5的速度在x86上是没问题的,毕竟x86起点就比ARM快10倍,你还有很多上升空间。解决方案显然是让ARM变成10倍快,这样就可以跟x86竞争了,然后我们就可以不用做任何工作就可以得到桌面环境的JS性能了。
这个方法行不行得通取决于你是否相信摩尔定律,以及给每个芯片配置一个3盎司的电池是否可行。我不是一个硬件工程师,但是我曾经为一家大型半导体公司工作过,那里的人告诉我说当今硬件的性能基本上是制作工艺(process)起的作用。iPhone 5令人印象深刻的性能主要是因为其芯片工艺从45nm做到了32nm,减少了差不多1/3。但是如果想继续这么做,苹果就要达到22nm的工艺。
顺便提一下,Intel22nm工艺的Atom处理器现在还没上市。而且Intel不得不重新发明全新的半导体,毕竟原来的半导体在22nm级别已经不适用了。他们会把工艺授权给ARM?再好好想想吧。如今22nm的产品少之又少,而且大部分被Intel掌控着。
事实上,ARM似乎已经在着手在明年尝试28nm了(看看A7),同时Intel正在尝试22nm甚至在稍微晚些时候尝试20nm。从纯硬件的角度,我感觉具有x86级别性能的x86芯片很可能远远比具有x86性能的ARM芯片更早登录智能手机市场。
看一个前Intel工程师给我发的邮件:
我是一个前Intel工程师,刚开始从事于移动微处理器的工作,后来工作转向了Atom处理器。无论如何,我有一个很偏激的观点,即x86从较大的核心转向手机市场的难度远比ARM从头开始设计技术细节以达到x86的性能级别的难度要低很多。
再看一个机器人领域的工程师给我发的邮件:
你说得非常对,这些(译注:指的是ARM的发展)不会带来多大的性能提升,Intel可能在近几年之内就会有更高性能的移动处理器。事实上,移动处理器当前和桌面处理器面临着同样的问题,即工作频率达到3GHz左右的时候,再提高时钟速度就不可避免地使得功耗大大增加。这种情况同样会发生在下一代工艺上,尽管IPC(Instruction per Clock,即CPU每一时钟周期内所执行的指令多少)会得到一些提高(差不多10%-20%)。在面临这种限制的情况下,桌面处理器开始向双核和四核方向变化,但是移动处理器现在已经是双核和四核了,所以想提高性能不是那么容易。
摩尔定律无论怎么说都可能是正确的,但是这需要整个移动生态环境向x86环境转变。这并非完全不可能,毕竟曾经有人做过这样的事。但那是在移动处理器一年才卖出去100万个的时候做的,不像现在,每个季度就可以卖出62万个芯片。那个时候现成的虚拟化环境可以模拟出老架构的60%的速度,而按照现在的研究来看,虚拟化系统上运行优化过的(O3)ARM代码的速度已经接近27%了。
如果你坚信JavaScript的性能最终会到达一个合理的水平,那么硬件性能的提升绝对是最好的方式。要么Intel会在5年之内开发出可行的iPhone芯片(这是有可能的),并且苹果迅速转向x86架构(这是不太可能的),或者ARM能够在未来的10年之内得到性能的飞跃。但是在我看来,10年是一个很长的时间,长到足够使某件事情可能成功。
恐怕我的硬件的知识只能分析到这里了。我可以告诉你的是,如果你相信ARM可以在未来的5年之内填补与x86之间的性能差距,那么第一步就是找到一个在ARM或者x86上工作的人(也就是真正懂硬件的人),让他同意你的看法。我写这篇文章之前,曾近咨询过很多有很高资质的硬件工程师,他们所有人都拒绝公开发表这个观点,这让我感觉这个观点不是很靠谱。
这是一个很多优秀软件工程师犯错误的地方。他们的思路是这样的:JavaScript已经变得更快了,并且它会变得更快。
这个观点的前一部分是正确的,JavaScript的确变得快很多。但是我们现在已经达到了JavaScript性能的顶点了,它不可能变得更快多少。
为什么?其实前一部分JavaScript的性能提升从某种程度上是硬件的原因,正如Jeff Atwood写道:
我感觉从1996到2006之间JavaScript的性能变快了100倍。如果Web 2.0主要建立在JavaScript上的话,这很可能主要是因为摩尔定律所带来的硬件性能提升。
如果我们把JS的性能提升总结为硬件性能提升的话,那么JS的已有的硬件性能提升不能预测未来的软件性能提升。这就是为什么如果你相信JS会变得更快的话,最有可能的方式就是硬件变得更快,因为历史趋势就是如此。
那么JIT如何呢?V8,Nitro/SFX,TraceMonkey/IonMonkey,Chakra等等?当然,当他们刚刚问世的时候,的确是很了不起的(但或许不像你认为的那么了不起)。V8在2008年9月发布,我找到了一份差不多那个时候同期的Firefox 3.0.3,看看它的性能:
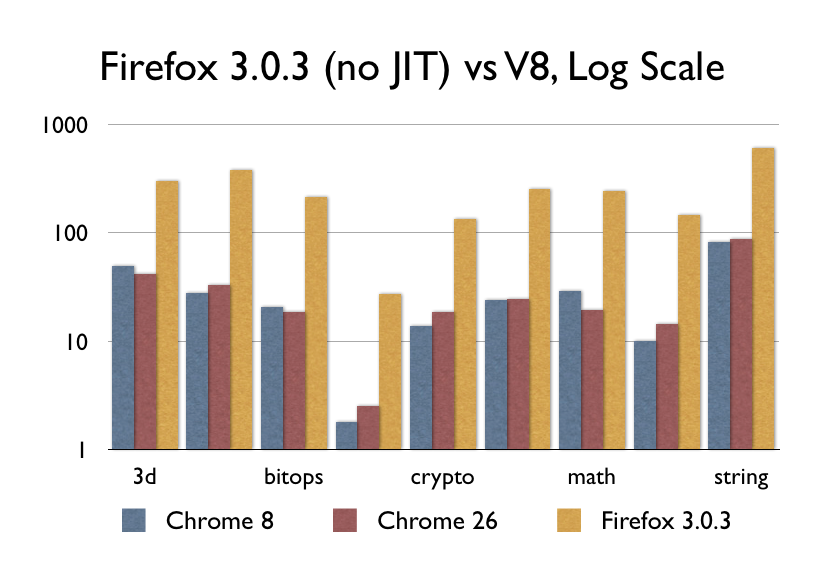
不要误解我的意思,9倍的性能提升的确值得称赞,毕竟这差不多是ARM和x86之间的性能差距了。即便如此,Chrome 8和Chrome 26之间的性能却呈现出了水平线,因为自从2008开始,几乎没有什么重大的事情发生。其他浏览器厂商都已经赶上来了,有些快有些慢,但是没人真正提高过JavaScript的性能了。
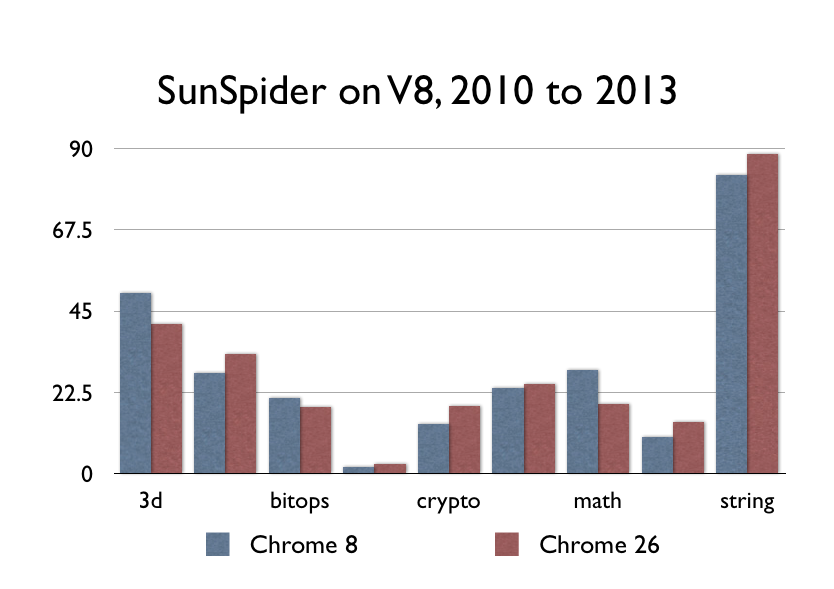
这是我Mac上的Chrome 8(可运行的最早版本,2010年12月份的版本)和Chrome 26。
看不出差别?因为根本没有差别。JavaScript的性能最近根本没有得到大的提升。
如果你感觉现在的浏览器比2010年的浏览器跑的快的话,那很可能是因为你有了一台更快的电脑,但是这与Chrome的性能提升没什么关系。
更新:有些聪明的人指出SunSpider现在不是一个好的benchmark(并且拒绝提供任何实际的数字或其它什么)。为了能够可以理性地讨论,我在一些旧版本的Chrome上面运行Octane(一个Google的benchmark),的确显示出了一些性能提升:
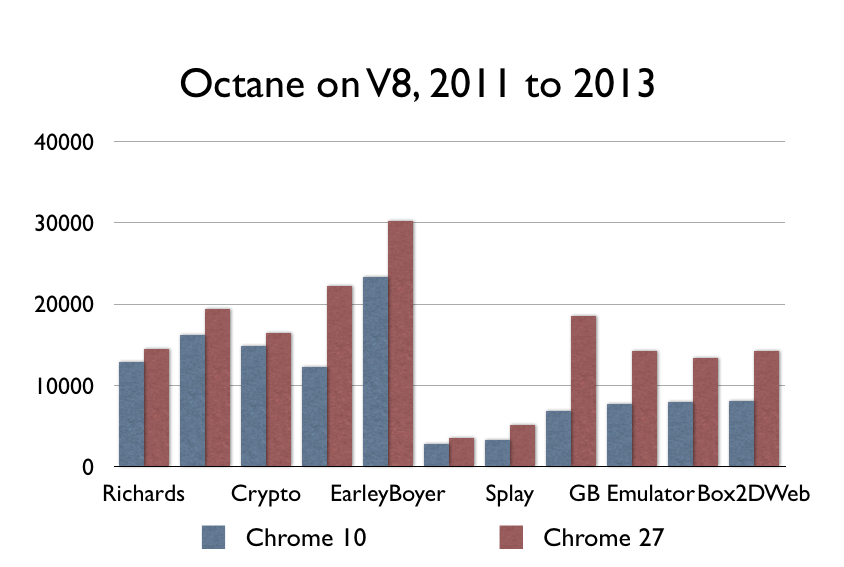
在我看来,在这个期间的性能提升还是太小,不足以支撑JS马上就会足够快这样的论调。然而,要说我过分强调这个情况也没错,毕竟JavaScript的计算密集型操作的确在发生变化。但是推我来说,这些数字可以得出更大的推断:这些性能提升的幅度还不足以在一定时间之内使得JavaScript的速度赶上原生代码。你需要性能达到2-9倍才能跟LLVM竞争。这些提升是好的,但还不足够好。更新结束。
问题是,让JavaScript采用JIT技术是一个60年前就有的想法,并且这60年来一直有人在研究。数以千计的你可能想到的编程语言对JIT的实现都证明这是一个好主意。但是既然我们已经做到了,我们已经用完了这个60年前的想法。伙计们,就是这样的,表演结束了。或许我们可以在未来的60年之内想到另一个好办法。
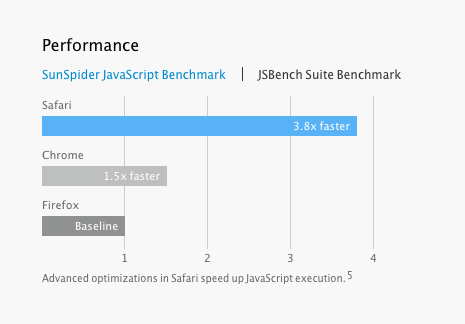
Safari 7 是不是比其它的浏览器快3.8倍?
这个结论或许对苹果来说很容易得到,但是这个版本的Safari在NDA协议之下,所以没有人能够公开关于Safari性能的独立参数。但是我可以仅仅根据现在已经得到的信息来做一些分析。
我发现一些现象很有意思。第一、苹果官方在公开的JSBench上的数据要比在他们在较老的benchmark(如SunSpider)上给出的数据高出不少。现在JSBench背后有一些非常酷的名字,包括JavaScript之父Brenden Eich。但是和传统的benchmark不一样,JSBench的工作方式不会考虑整数和其它重要因素,它反而自动为Amazon、Facebook和Twitter提供的内容进行优化,而且根据它们提供的内容来建立benchmark。
如果你在写一个多数人用来浏览Facebook的浏览器,我可以理解用一个只测试Facebook性能的benchmark是很有用的。但是从另外的角度讲,如果你在写一个电子表格的程序,或者游戏,或是一个图片过滤应用,在我看来传统的benchmark(注重整数运算和md5哈希)会更能够准确地帮你预测出Facebook的分析代码有多快。
另一个重要的事实是,苹果声称的在SunSpider上性能的提升并不能代表其它东西的提升,Eich et al在这篇提到苹果所偏爱的benchmark的文章中写道:
图中清楚地显示出了Firefox的3.6版本比1.5版本在SunSpider的benchmark上性能提高了13倍。但是当我们看它在amazon的benchmark上的性能表现时,发现只有较谦虚的3倍的提升。更有意思的是,在过去的两年时间,在amazon的benchmark上的性能提升其实是被夸大了。这意味着在SunSpider上做的一些优化几乎对amazon没有太大作用。
在这篇文章中,JavaScript之父和Mozilla的首席架构师之一曾公开承认在过去的两年之内Amazon的JavaScript性能几乎没有提升,没有发生过什么特别重要的事情。从这一点你也可以看出来,那些营销人员这些年都在过分夸大自己产品的性能。
他们继续争辩道:对于那些人们用来浏览Amazon网页的浏览器来说,运行Amazon的benchmark比运行其它benchmark要更能准确地预测出浏览器的性能(这是当然了……),但是这些手段不会帮助你更好地写出一个照片处理程序。
但是无论怎么说,从我可以看到的公开信息来看,苹果声称的3.8倍的性能提升对你来说几乎没有什么太有用的东西。我可以告诉你,如果我有一些能够反驳苹果声称击败Chrome的benchmark的话,我将不被允许发布它们。
所以,我们总结一下这一节,如果有一些人拿出一个柱状图来显示网页浏览器变得更快了,那并不能真正说明整个JS变得更快了。
但是还有一个更大的问题。

下面这段话出自于Herb Sutter,现代C++中最著名的人物之一:
在过去的20年里,有一种很难根除的文化基因——只要的等下一代的(包括JIT和静态)编译器出来,托管语言就会变得和原生语言一样高效。是的,我完全希望C#和Java编译器能够不断提高,包括JIT和类NGEN的静态编译器。但是,它们永远不会消除与原生代码之间的效率差距,有两个原因:一、JIT编译不是主要问题。根本原因更为基本:托管语言在编程人员的开发效率(当时的确是个问题)和程序的运行效率之间从设计上做了故意的妥协。特别的,托管语言选择选择在所有的程序上添加额外的性能开销,尽管你根本没有用到一个特性,你都会受到这个特性带来的额外的性能开销。主要的例子是assumption/reliance、垃圾回收、虚拟运行环境和元数据等功能在托管语言中是默认打开。当然还有其它的例子,比如托管代码中函数默认是virtual的,而C++代码中的函数是默认inline的。1盎司(译注:12盎司=1磅)的内联阻止(inlining prevention)抵得上1磅的去虚拟化优化(devirtualization optimization cure)。
下面这段话出自于Mono项目组的Miguel de Icaza,他是为数不多的“维护着一个主流JIT编译器的人”。他说道:
关于主流托管语言(.NET、Java和JavaScript)的虚拟机之间的差异,有一个比较准确的说法。托管语言的设计者在他们设计一门语言的过程中更倾向于安全性,而不是性能。
或者你可以找Alex Gaynor谈一谈,他负责维护和优化Ruby的JIT编译器,并且也为Python的JIT的优化工作做出了贡献:
这是加在这些具有高生产力的动态语言身上的诅咒。它们使得创建一个哈希表十分容易。这是一件非常好的事情。我认为C程序员多数不太会使用哈希表,因为对他们来说用哈希表实在是是一件痛苦的事情。原因有二:第一,你没有一个内置的哈希表;第二、当你尝试去使用的时候,你会左右碰壁。对比来看,Python、Ruby和JavaScript程序员都过度使用哈希表了,因为使用它们实在太容易了……所以大家都不在乎。
Google似乎意识到了JavaScript正面临着性能的瓶颈:
复杂的Web应用(这是Google比较擅长的)在某些平台上正在面临着不小的挣扎,主要是因为这些应用用到了一些不能被性能调优的语言,这些语言有内在的性能问题。
最后,我们听听权威人士的意见。我的一个读者向我指出这段Brenden Eich的评论。正如你所知,他是JavaScript之父。
有一点Mike没有强调:得到一个更简单的语言。Lua比JS简单得多。这意味着你可以写出一个简单的解释器使得它跑得足够快,同时能够保持对trace-JIT代码的尊重(这和JS不同)。
稍微下面一点又提到:
关于JS和Lua之间的差别,你可以说这完全是正确的设计和工程上的问题,但是内在的复杂性区别还是很大。你当然可以把较难的案例从热路径中删除,但是他们也会因此付出代价。JS比Lua有更多的更难的案例。一个例子是:Lua(没有显式的元表使用)没有像JS中的原型对象链(prototype object chain)的东西。
在这些真正从事相关工作的人当中,持有JS或者是其它动态语言能够赶上C语言性能这个观点的,只占极少数(very much the minority)。到处都有和主流想法不同的人,所以根本无法没有什么办法能够达到真正的一致。但是,从语言的角度说到JIT语言是否能够赶上原生语言的效率,他们给出的答案都是“不,不可能,除非修改语言本身或者API”。
但是还有一个更更大的问题。
你可以发现,CPU问题、CPU相关的benchmark以及所有有关CPU的设计决定,都只是故事的一半。故事的另一半是内存。内存问题现在看来是如此的巨大,大到使整个CPU的问题看上去都仅仅是冰山一角。实际上可以讨论的是,所有关于CPU的讨论都是转移注意力的话题(red herring)。你接下来要阅读的应该会完全改变你对移动设备软件开发的理解。
2012年,苹果做了一件非常奇怪的事情(当然了,除非你是John Gruber,能够看到它的到来)。他们把垃圾回收从OSX中除去了。真的,你可以去看看程序员指南。标题右边有一个大大的“不推荐(Not Recommended)”。如果你之前是Ruby、Python、JavaScript、Java、C#或是其它任何1990年代之后诞生的语言的开发者,这应该会让你感觉很奇怪。但是这很可能不会影响到你,因为你很可能不在Mac下面使用ObjC,在HN点击下一个链接。但是这仍然看上去很奇怪,毕竟GC一直被大家使用着,而且它的价值也得到了证明。为什么你要反对它呢?苹果是这么说的:
我们十分坚信ARC才是内存管理的正确方式,所以我们决定使OSX上的垃圾回收变成过时的(deprecate)。——ession 101, Platforms Kickoff, 2012, ~01:13:50
这段话没有告诉你的是,当听到这句话的时候,台下的观众爆发出了热烈的掌声。OK,这就变得真的非常奇怪了。你是不是在告诉我有那么一个屋子里的程序员在为了垃圾回收之前的那种混乱的回归而鼓掌?你可以想象下如果Matz在RubyConf上宣布GC过时的时候整个会场的寂静,几乎一颗针掉在地上都听得到声音。而这群人却因此而高兴?太古怪了吧?
你应该根据这些古怪的反应发现一些你现在看不到但是却是在真正发生的事情,而不是仅仅把这些事情归结于这群人对于苹果的狂热。这些正在发生的事情就是我们下面就要讨论的主题。
思维过程是这样的:把一个工作得好好的垃圾回收器从一个语言中拿出来简直是疯了吧?一个简答的解释可能是ARC可能仅仅是苹果为了给垃圾回收披上一层美丽新装而创造的一个营销词汇,所以这些开发者是为了这种升级而不是降级而鼓掌的。事实上,这就是很多iOS簇拥们的抱有的想法。
所有的那些认为ARC是某种垃圾回收器的人,我想通过下面这个苹果的幻灯片给你迎头一击(beat your face):

这与和垃圾回收有类似名字的算法无关。它不是垃圾回收,他不是什么像垃圾回收的东西,它表现得一点都不像垃圾回收,它不会打乱任何保留周期,它没有去回收任何东西,它甚至没有去做扫描。OK,故事结束,它绝对不是垃圾回收。
因为正式的文档还在NDA协议下,所以有很多传言认为这并不是真的(但是细则已经可以看得到了,没有任何借口了),而且很多博客都纷纷说这些不是真的。它是真的。不要再讨论了。
这是苹果在压力之下给出的关于ARC和GC的说法:
在愿望清单的顶端上我们能为你们做的最重要的事情就是把垃圾回收带到了iOS中,而这恰恰是我们最不应该做的。不幸的是,垃圾回收给性能带来了很多次优的影响。你程序中的垃圾回收会使得你的内存使用率变得很高,而且垃圾回收器经常在不确定的时间点上被触发而导致非常高的CPU使用率,从而打断用户正在做的事情。这就是为什么GC不适合在我们的移动平台上使用的原因。对比来看,带有获取和释放(retain/release)的手动内存管理学起来比较难,坦率的讲有些像痔疮(译注:这个翻译可能不准确,原文是pain in the ass)。但是它产生了更好更可预测的性能,这也是为什么我们选择手动内存管理作为我们内存管理策略的基础的原因。因为在外面真实的世界,高性能以及用户体验的连续性是我们的用户最看重的。(译注:在苹果看来,用户体验要比开发者体验重要。)~Session 300, Developer Tools Kickoff, 2011, 00:47:49
但是这还是完全疯狂了,不是吗?这只是开始:
1. 这可能会直接影响你整个职业生涯对于垃圾回收语言给桌面和服务器上带来影响的理解;
2. Windows Mobile、Andriod、Mono Touch以及所有其它移动平台上的GC似乎都可以挺好地工作。
所以让我们反过来看这个问题。
我知道你在想什么,你是一个有了N年开发经验的Python程序员。现在是2013年了,垃圾回收完全可以解决问题。
这是一篇你想看到的文章,似乎问题并没有解决:
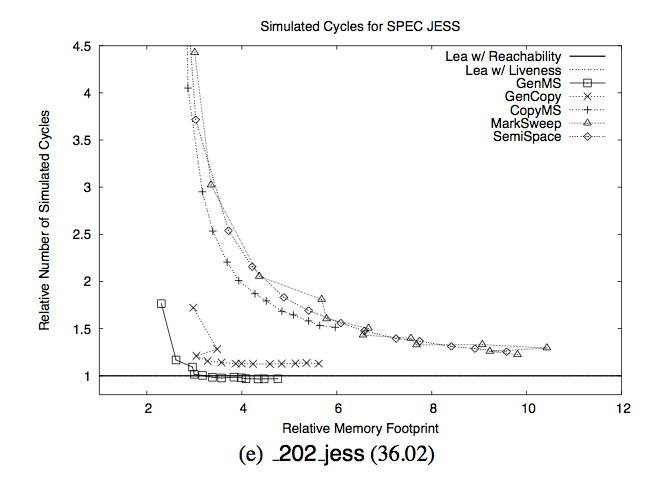
如果你在这篇文章中其它什么都记不得,那么请记住这张图。Y轴是垃圾回收所用的时间,X轴是“相对的内存足迹”,相对于什么?相对于所需的最小内存。
这张图想说明的是,“如果你有6倍以上你实际需要的内存,那么使用垃圾回收是没有问题的。但是如果你只有小于4倍你实际需要的内存,那么灾难就要降临了。”。但是不要相信我的话:
特别的,如果垃圾回收时系统拥有5倍于所需的内存时,它的运行时性能差不多甚至是超过显式内存管理。但是,垃圾回收的性能在必须使用小堆(small heap)的情况下会出现急剧下降。如果有3倍于所需的内存的话,它会跑得慢17%;如果只有2倍于所需的内存的话,会慢70%。垃圾回收比物理内存的换页更容易受到内存不足的影响。在这种情况下,我们所测试的所有垃圾回收器相对于手动内存管理都出现指数级的性能下降。
现在我们再来比较一下显式内存管理的策略:
这些图显示,如果可用内存在合理的范围的情况下(但不足以容得下整个应用),显式内存管理器都要比垃圾回收器快太多。比如说,pesudoJBB以63M的可用内存运行,Lea allocator在25s的时间内完成运行。在相同可用的内存下运行GenMS,花了超过10倍的时间来运行(255s)。我们可以看到其它benchmark套件的相同趋势。最值得一提的例子是213 javac和Lea allocator一起在36M的内存下运行,总体运行时间是14s,而与GenMS一起运行的情况下,运行时间为211s,用了超过15倍的时间。
基本的事实是,在内存受限的环境下垃圾回收性能的下降是指数级的。如果你在桌面电脑上写Python或者JS程序的话,你整个的体验可能是这幅图的右边部分,你可以一辈子都体会不到垃圾回收带来的性能问题。花点时间想想这幅图的左边部分,并且想想我们该如何应对。
这一点很难准确地描述。从iPhone 4到iPhone 5,这些设备上的物理内存从512M到1G不等。但是其中很大一部分为系统预留了,还有更大的一部分为多任务处理预留了。所以唯一真正的方法是在不同的情况下进行尝试。Jan Ilavsky写了一个非常有用的工具来完成这个任务,但是貌似没有人公开任何数据。但这一点现在已经改变了。
现在,在一种“正常”的情况下(这一点很难具体说清楚是什么意思)进行测试是非常重要的,因为如果你在一台刚刚启动的机器上测试的话,你会得到更好的数据,毕竟你的系统里面没有Safari所打开的页面。所以我就在“真实世界”的情况下拿出一些我公寓里的设备进行本次benchmark。

你可以点击进去看看详细的结果,大体上来说,在iPhone 4S上,当你的程序使用了40M内存的时候就会得到警告,而使用了213M内存的时候,程序就会被杀死;在iPad 3上,使用400M左右时获得警告,而使用550M左右的时候,程序被杀死。当然了,这些也仅仅是数字而已,如果你的用户在听音乐或者在后台跑一些程序,你可用的内存会比我测试里面可用的内存更少,这只是给你一个思路而已。这么多内存看上去不少(213M应该对每个人来说都足够了,是吧?),但实际上这还不够。举个例子,iPhone 4S拍照时的分辨率为3264*2448,每张照片有超过30M的位图数据。如果你在内存里加载了2张照片你就会获得警告,而如果加载了7张照片,程序就会被杀死。哦,你打算给你写个循环在你的相册中逐个处理?程序会被杀死。
还有一点需要十分注意:实际的情况下,一张照片可能存在于内存的多个位置。比如说,如果你在拍照片,那么你在以下位置都有数据:1) 你通过屏幕看到的摄像头中的数据,2) 摄像头实际上拍到的照片数据,3) 你尝试写到存储卡中的压缩JPEG缓冲数据;4) 你准备在下一个屏中显示的数据;5) 你准备上传到某个服务器中的数据。
在一些点上你会发现,保留30M的缓冲区去显示照片缩略图是一个非常不好的想法,因为这样你会引入更多的数据:6) 用来保留下一屏显示合适大小照片的缓存;7) 用于在后台重新调整照片大小的缓存(在前台做实在太慢了)。然后你发现你可能真正需要5个不同的大小,然后你的程序就不是一般的慢了,而是慢到让人抓狂。在实际的应用程序中,仅仅是处理一个照片就会遇到内存的瓶颈并非罕见的事情。但是不要相信我说的话:
你能做的最糟糕的事情就是在内存不充足的情况下在内存中缓存图片。当一张图片被画成位图或者显示到屏幕上时,我们就不得不把照片解码为位图。位图的每个像素点为4字节,无论原始图片多大都是如此。每当我们将它解码一次,位图就会绑定到图片本身并且一直维持到这个对象生命周期结束之时。所以如果你把图片加载到内存而且曾经显示过一次,那你现在就会在内存中保留整个位图,直到你释放它为止。所以永远不要把UIImage或者CGImage放到缓存中,除非你有一个非常明确(但愿是非常短期的)的目标。- Session 318, iOS Performance In Depth, 2011
你甚至不要相信上面的话!你给自己分配的内存其实只是冰山一角。下图是苹果一张幻灯片中给出的冰山的全图。Session 242, iOS App Performance – Memory, 2012:

你可以从两方面考虑这个问题。第一、在213M可用内存的情况下,在iOS上写一个照片处理程序比在桌面上写一个要困难许多。第二,你在iOS上写一个照片处理程序时,你对内存的需要会更多,因为你的桌面程序没有一个可以放进你口袋的摄像头。
我们可以看看另外一个例子:在iPad 3上,你要显示一个视频,这种照片的大小很可能比你电脑上的视频要大不少(后面的高分辨率摄像头,差不多2000-4000像素)。每一帧要显示的就是一个12M的位图。如果你对内存的使用很节省的话,每一时刻你可以在内存中保留45帧的未压缩视频或动画缓存,也就是在30fps的情况下每1.5s,在60fps的情况下0.75s。你想为一个全屏的动画预留缓存?应用被杀死。值得指出的是,AirPlay的延迟是2s,所以对于任何多媒体类型的应用,你几乎是保证没有足够的内存。
这种情况下我们同样面临着和照片的多个数据拷贝差不多的问题。比如说,苹果指出,“每一个UIView背后都有一个CALayer,而且只要CALayer存在于在这个层次中,对应的图片数据会一直保存在内存中”。这意味着,很可能有许多中间的渲染数据的拷贝存在于内存中。
还有剪切矩形和备份存储这些可能会占用内存的事情。这样的数据处理架构事实上是非常高效的,但是这带来的代价是程序会尽可能地占用内存。iOS不是为低内存使用而设计的,它是为了快速运行而设计的。这没有和垃圾回收扯在一起。
我们同样需要从两个方面考虑问题。第一,你在一种内存非常紧缺的情况下做出动画效果;第二、做出这样超级高质量的视频和动画是需要极大的内存的。而为了使得普通消费者买得起消费级别的、具有高摄像头分辨率的产品,这种糟糕的、内存受限的环境几乎是必然的选择。如果你想写一个软件来毫无压力地播放视频,那么你就得说服别人为了屏幕多花700美元,或者花500美元买一个iPad,它实际上已经包含了一个内置的电脑。
一些聪明的人说:“OK,你说了很多关于我们不会有更快的CPU。但是我们应该回有更多的内存吧?这正是桌面环境上发生的事情。”
这种理论的一个问题是,ARM平台上的内存就在处理器本身上,这被称为package on package。所以在ARM上获得更多的内存几乎和提高CPU性能是同一个问题,因为它们归根结底是同一件事情:在CPU上集成更多的晶体管。内存晶体管处理起来稍微容易一些,因为它们是统一的,所以不是那么难,但实际上也不是那么简单。
如果你看看iFixit的A6的照片,你会发现在CPU模具最表面的硅几乎100%都是内存。这意味着,如果你想拥有更多的内存,你要么使得制作工艺更精细,要么提高模具的大小。事实上,如果你把工艺的大小做归一化处理,那么其实伴随着每次内存升级,你的模具都在变得更大。
硅其实是一种不完美的材料,为了获得更大的尺寸所付出的的代价是指数级增长的。它们也很难维持较低的温度,也很难放进小设备中。它们和制作出更好的CPU的目标是重复的,因为内存也面临同样的问题:CPU最上层的硅中需要放进更多的晶体管。
我搞不懂的是,面临着PoP的这些问题,CPU厂商们继续使用PoP的方式为系统提供内存。我还没有遇到任何ARM工程师能够解释这一点。或许以下的评论可能会帮助我们理解。我们有可能从PoP架构转向电脑中采用的分离内存模块,而且我感觉这比较可行。原因很简单,将内存分为单独的模块比制造出更大的芯片和进一步减小制作工艺对厂商来说毫无疑问成本是更低的。但是现在所有的厂商都在不停地尝试提高制作工艺或者制作出更大的芯片,而不是把内存模块独立出来。
然而,一些聪明的工程师曾经给我发了邮件让我填补了这方面的空白。
一个前Intel工程师说道:
PoP内存模型可以大量减少内存延迟,也可以减轻路由问题。但是我不是ARM工程师,也不确定这是否是全部的原因。
一个机器人学的工程师提到:
当PoP内存不够用时,“3D”内存会提供足够大的内存:内存芯片在生产的时候堆叠在一起,1G的RAM在同一层堆成10层向上,就像现在的硬件模型一样。但是,这样的开销会很大,频率和电压都要相应地降低使得电力消耗处于一个合理的水平。
移动RAM的带宽不会像最近提高得这么快了。带宽被连接SoC和RAM包的总线的数量所限制。当前RAM的总线多数使用的是高性能SoC的圆柱体表面。SoC的中间部分不能用来加入RAM总线,因为这些RAM包是层叠的。接下来的重大改变应该回来自于将SoC和内存放在一个单独的、高度集成的包中,允许更小、更密集和大量的RAM总线(更大的带宽),并给SoC设计和更低的RAM电压带来更多自由。根据这样的设计,更大的缓存也就可能成为现实,因为RAM可能用更高的带宽放在SoC模具中。
这个问题事实上有两个答案。第一个答案我们可以从图中看出。如果你发现你有6倍于所需的内存,垃圾回收其实是非常快的。举个例子来说,如果你在写一个文本编辑器,你可能可以用35M的内存完成自己要做的所有事情,这是我的iPhone 4S会崩溃内存上界的1/6。你可能在Mono上写个文本编辑器,看到非常不错的性能,然后从这个例子中得出如下结论:垃圾回收十分适合这个任务。你是对的。
然而Xamarin框架在案例中有一个飞行器模拟器。很显然的是,垃圾回收对于现实生活中的较大的应用程序来说是不适合的。难道不是吗?
你在开发和维护这个游戏时一定会遇到什么样的问题?“性能一直是一个大问题,而且将持续是我们再跨平台中会遇到的最大的问题之一。最初的Windows Phone设备是非常慢的,我们不得不花很多时间来优化程序,使得它达到一个体面的帧率。我们不仅仅在飞行模拟代码上进行优化,而且在3D引擎上优化。垃圾回收和GPU的弱点是最大的瓶颈。
程序员不约而同地声称垃圾回收是最大的瓶颈。当你的案例中的人在抱怨的时候,那应该是一个足够引起你重视的线索了。但是Xamarin可能是一个局外人,我们还是来看看Andriod开发者怎么说的吧:
请记住下面是我在我的Galaxy Nexus上运行的情况:无论怎么说都是性能非常不错的设备。但是看看渲染的时间!我在电脑上只要花几百毫秒就可以渲染出这些图片,可是在这台手机上却花了超过两个数量级的时间。渲染“inferno”图片超过6s?这简直是疯了吧!要生成一副图片,需要10-15倍的时间来运行垃圾回收器。
另一个开发者:
如果你想在Andriod手机上为实时物体识别或者基于内容的现实增强进行对照相机图片的处理,那么你很可能听说过照相机预览回调(Camera Preview Callback)的内存问题。每次Java程序尝试从系统获取预览图片时,系统就会创建一大块新的内存。当垃圾回收器释放这块内存时,系统会卡住(freezes)100ms到200ms。如果系统在高负载的情况下,事情可能会变得非常糟糕(我曾经在手机上做过物体识别——天呐,它几乎把整个CPU都占用了)。如果你看过Andriod 1.6的源代码你就会知道,这只是因为这个功能的包装类(wrapper,用来包装原生代码)每次在一个新的帧可用时都会申请一个新的字节数组。当然,内置的原生代码可以避免这个问题。
或者,我还可以去看看Stack Overflow:
我负责在Andriod平台上为Java写的交互式游戏进行性能调优。很多时候,当候垃圾回收开始工作会让使得游戏的画图和交互功能发生打嗝。通常情况下这种打嗝持续不到1/10s,但有的时候在比较慢的设备上会长达200ms。如果我在一个内部循环中使用树或者哈希表,我就就知道我要很小心,或者甚至不用Java标准的Collections框架,而是自己重新实现一个,因为我承担不起垃圾回收带来的额外开销。
这是一个“接受的答案(accepted answer)”,有27个人赞同:
我也是Java手机游戏的开发者……避免垃圾回收(垃圾回收可能在某个点被出发从而大幅降低你游戏的性能)的最好方法就是不要再游戏的主循环中创建对象。实在没有什么“简洁”的方式来处理这种问题,或许只有手动追踪这些对象了,真悲哀。这地也是目前大部分当前移动设备上性能优良的Java游戏所采取的的方式。
我们来看看Facebook的Jon Perlow怎么看待这个问题:
对于开发流畅的安卓应用来说,GC是一个非常大的性能问题。在Facebook,我们遇到的最大问题之一是GC会使得UI线程暂停。当我们处理很多位图数据时,GC被触发的频率很高,而且难以避免。GC经常导致掉帧的问题。即使GC只会阻塞UI线程几毫秒,但这却会严重影响原本需要16毫秒的帧渲染。
OK,我们再听听一个微软MVP的说法:
通常情况下,你的代码在33.33ms之内就会完成执行,从而使得30fps的帧率变得很不错。但是当GC运行的时候,它会占用那个时间。如果你的堆比较整洁和简单,那么GC一般可以运行得不错,不会对程序产生什么影响。但是让一个简单的堆处于一个使GC可以快速运行的情形是一件困难的编程任务,它要求大量的计划和/或程序重写,即使是这样也不是完全安全的(有时在一个复杂的、有很多玩意的游戏中你的堆里面有很多内容)。更简单的方法是(假设你能这么做),在游戏过程中限制甚至是禁用内存分配。
在有垃圾回收的情况下,在游戏中保证一定会赢的方法就是不要玩(作者的幽默,原文:the winning move is not play)。比这种哲理稍弱的一种形式如Andriod官方文档中所说的:
对象创建永远不是免费的。带有线程级别内存池的垃圾回收器使得内存分配的成本变得稍微低一些,但是分配内存永远比不分配内存开销大。因为当你在程序中分配对象时,你会强制垃圾回收周期性地工作,从而使得用户体验不是那么流畅。Andriod 2.3当前引入的垃圾回收器有一些作用,但是要是应该避免不必要的工作。因此,你应该避免创建你不需要的对象实例。一般而言,尽可能不要创建短期临时对象。越少的对象创建就意味着越低频率的垃圾回收,从而提高用户体验。
还不信?那让我来问问一位真正从事垃圾回收工作的工程师,他为移动设备实现垃圾回收器。
然而,WP7系统的手机CPU和内存性能正在大幅度地提升。游戏和大型Silverlight应用越来越多,这些程序会占用100M左右的内存。随着内存的变得越来越大,很多对象拥有的引用会指数级地变多。在上面解释的模式中,GC不得不去遍历每个对象以及他们的引用,标记它们,然后清理没哟引用指向的内存。所有GC的时间也大幅增加,并且成为这个应用的工作集(workingset)的一个函数。这会在大型XN游戏中和SL应用中导致程序卡住,体现在很长的启动时间(因为GC有可能在游戏启动的时候运行)或者游戏过程中的小问题。
还是不信?Chrome有一个测量GC性能的benchmark。我们来看看它都干嘛了:

你可以看到很多GC导致的卡顿。当然了,这是一个压力测试,但还是能说明问题的。你真的愿意花几秒时间来渲染一帧?你疯了吧。
结论是:移动设备上的内存管理很难。iOS平台的开发者已经形成了一种文化,即手动做大部分事情,让编译器做其它容易的部分。Andriod平台形成的文化是,提高垃圾收集器的性能,但事实上开发者在实际开发中尽量避免使用它。这两者的共同点是,大家在开发移动应用时,开始越来越多地考虑内存管理问题了。
当JavaScript、Ruby或是Python开发者听到“垃圾收集器”这个词时,他们习惯将它理解为“银弹(silver bullet)垃圾收集器”,也就是“让我不要让我再考虑内存问题的垃圾收集器”。但是移动设备上根被没有银弹可言,每个人写移动应用时都在考虑内存问题,不管他们是否使用了垃圾收集器。获得“银弹”内存管理方式的唯一方式就像我们在桌面环境上一样,拥有10倍于程序实际需要内存。
JavaScript的整个设计基于一个思想,即不要担心内存。看看Chromium开发者们怎么说:
有没有任何一种方式强制chrome的js引擎进行垃圾回收?一般意义而言,没有,这是从设计的角度就已经确定了的。
ECMAScript规范没有提到“分配(allocation)”这个词,唯一与“内存”相关的话题本质上就是说整个主题都是“实现相关的(host-defined)”。
ECMA 6的维基页面上有几页提案的草稿,归根结底是说(不是开玩笑):
“垃圾回收器不可以回收那些程序需要继续使用来完成正确执行的内存。所有不能从根节点传递遍历到的对象都应该最终被销毁,防止程序因为内存耗尽而发生错误。”
是的,他们的确在思考将这个需求规约:垃圾回收器不应该回收那些不应该被回收的东西,但是应该回收那些需要被回收的。欢迎来到tautology club。但是下面这段话可能与我们的话题更相关:
然而,并没有规范说明单个对象占用多少内存,也不太可能会有。因此当任何程序在内存耗尽的情况下,我们永远不会得到任何保证,所以任何准确的、可观察的下界。
用英语来说就是,JavaScript的思想(如果这算是一种思想的话)是你不应该能够观察到系统内存中的情况,想都不要想。这种思想和人们在写实际的程序时候的想法简直是令人难以置信的背道而驰(so unbelievably out of touch),我甚至找不到正确的词语来向你形容。我的意思是,在iOS的世界里,我们并不相信垃圾回收器,我们感觉Andriod开发者都疯了(nuts)。我怀疑Andriod开发者会这么认为:iOS开发者竟然会用手动内存管理,简直是疯子。但是你知道这两个水火不容的阵营的人可以在哪件事情上达成共识吗?那就是JavaScript开发者是真正的疯子。你在移动平台上写出一个有点意思的程序,而从来不关心系统内存的分配和释放,是绝对不可能的(absolutely zero chance)。绝对不可能。暂时把SunSpider的benchmark上的问题和CPU计算密集型的问题都抛开,我们可以得出这样的结论:JavaScript,尽管现在存在着,是和移动平台软件开发过程中绝对重要的思想,即永远要考虑内存问题,从根本上是背道而驰的。
只要人们想要人们想在移动设备上开发各种视频和照片处理程序(不像桌面电脑),只要移动设备的内存不是那么充足,这个问题就是非常棘手的。你在移动设备上需要理性的、正式的内存管理保证。而JavaScript从设计上来说是拒绝提供这些的。
现在你可能会问,“OK,桌面环境上的JS开发者不会移动设备上的开发者遇到的问题。假设他们相信你说的,或者假设有一些知道这些问题的移动开发者们根据JS重新设计一门语言。你感觉理论上他们可以做哪些事情?”
我不确定这是否是解决的,但是我可以在这个问题上放一些边界。有另一群人曾经尝试在JS的基础上设计一门适合移动开发者的语言——RubyMotion。
这些人非常聪明,他们很了解Ruby。然后这些Ruby开发者认为垃圾回收对于他们的语言来说是一个糟糕的想法。(GC倡导者们,你们看到我说的了吗?)所以他们用了一种非常类似ARC的技术然后嫁接到语言当中,然而却没有成功。
总结:很多人正经历着由于RM-3或者其它难以辨别的问题所导致的内存相关议题,我们可以看看他们怎么说。
Ben Sheldon说:
不仅仅是你,我也面临着内存相关的程序崩溃(比如SIGSEGV和SIGBUS)生产环境下有10-20%的用户遇到过这种情况。
有一些人怀疑这个问题是否易于处理:
我在最近的一次Motion Meetup会上提出关于RM-3的问题,Laurent和Watson都对此提出了自己的看法。Watson提到说,RM-3是最难修复的bug;Laurent说他尝试了很多方法,但最终都没有很好地解决这个问题。他们两个人都是非常聪明和厉害的程序员,所以我相信他们说的话。
还有一些人怀疑编译器理论上是否能够解决这个问题:
很长的一段时间内,我都认为编译器可以简单明确地处理程序块,即静态地分析程序块内部的内容来判断程序块是否引用了这个程序块外部的变量。我认为,对于所有这些变量,编译器可以在程序块创建时获取,在程序块销毁时释放。这个过程吧这些变量的生命周期绑定到程序块上(当然,在某种情况下不是“完整的”生命周期)。有一个问题是instance_eval(译注:Ruby中Object类的方法)。程序块中的内容或许是按你提前知道的方式使用的,但也有可能并不是你能够提前知道的。
RubyMotion还有一个对立的问题:内存泄露,而且它还有可能有其它问题。没有人真正知道程序崩溃时内存泄露有2个原因还是有200个原因。
所以不管怎么说,我们的结论是:一部分世界上最好的Ruby程序员专门为移动设备开发设计了一种语言,他们设计了一个系统,这个系统不仅会崩溃,而且还会内存泄露,这些问题都是你可能会面临到的。至今为止他们并没有能够处理这个问题,尽管他们已经非常尽力了。对了,他们也表示他们“自己尝试了不少次,但没有能够能够找到一个好的并且能够保持高性能的解决方案”。
我并不是说在JavaScript的基础上创建一门具有较高内存性能的语言是不可能的,我只是想说很多证据显示这个问题会非常难。
更新:一个Rust语言的贡献者提到:
我为Rust项目工作,我的主要目标是实现零额外开销的内存安全。我们通过“@-boxes”(@T声明的类型是任何类型T)的方式来支持通过GC处理的对象,而我们最近遇到的比较麻烦的事情是,GC触碰到语言中的所有内容。如果你想支持GC但却不需要它,你就要非常仔细地设计你的怨言来支持零额外开销的非GC指针。这不是一个简单的问题,我不认为可以通过建立在JS的基础上创建一门新语言来解决。
asm.js就比较有趣了,因为它提供了一个JavaScript模型,但这个模型严格意义上不是建立在垃圾回收的基础上的。所以从理论上讲,使用正确的网页浏览器,使用正确的API就可以了。问题是,“我们会得到正确的浏览器吗?”
Mozilla显然在这个概念上被出卖了,作为这个技术的作者,他们的实现今年晚些时候实现了它。Chrome的反应一直是含糊不清的,因为这个技术显然和Google的其它提案,包括Dart和PNaC1有直接的竞争关系。关于它有一个开发的bug清单,但是一个V8的黑客对此不满意。至于Apple阵营,按照我现在看来,WebKit那群人对比完全保持沉默。IE?我从来就没有抱任何希望。
无论如何,现在还不能说asm.js就是真正解决JavaScript问题,且能够击败所有其它提案的方法。另外,如果它能做到,它真的不可能是JavaScript,毕竟它能够可行的原因就是抛开了麻烦的垃圾回收器。所以它有可能和C/C++或者其它手动管理内存的语言的前端一起工作,但肯定不和我们现在知道并且喜欢的动态语言一样。
当一些文章里面说“X慢”和“X不慢”的时候,一个问题是,没有人真正说的清楚它们的参照系是什么。对于一个网页浏览器开发者,和对于一个高性能集群的开发者,以及对于一个嵌入式系统的开发者,等等,“慢”的含义是不一样的。既然我们已经闯过了战壕而且做了这么多benchmark,我可以给出你三个有用且大致正确的坐标系。
如果你是一个Web开发者,把iPhone 4S的Nitro当做IE8来看,因为它们的benchmark成绩差不多。这就给了你写代码时的正确坐标系。写代码的时候应该谨慎地使用JS,否则你会面临一大堆平台相关的性能问题要处理。有些应用用JS来写性价比是不高的,即使是流行的浏览器。
如果你是x86平台上的C/C++开发者,把iPhone 4S的Web开发环境当成只有桌面开发环境性能的1/50。其中1/10来自于ARM相对于x86的性能差距,1/5来自于JavaScript相对于C/C++的性能差距。在非JavaScript、性能为桌面环境1/10的情况下,仔细考虑正反面的因素。
如果你是Java、Ruby、Python或者C#开发者,按照以下方式去理解iPhone 4S的Web开发环境:它的性能是你电脑的1/10(ARM的因素),并且如果你的内存使用超过35M,性能会指数级下降,这是由垃圾回收的工作方式决定的。还有,如果你的程序分配了超过213M的内存,程序就会崩溃。注意,没有人“从设计的角度”在运行时刻给你这个信息。对了,人们都希望你在这种环境下写出很耗内存的照片处理和视频应用。
下面是你应该记得的内容:
毫无疑问的一点是,我不久就将收到上百封邮件,这些邮件圈出我说的某句话,然后在不提供任何实际的证据(或者根本不能算是证据)的情况下,指出我说得不对。或者说“我曾经用JavaScript写过一个文本编辑器,挺好”,或者说“有些我从来没见过的人写了一个飞行模拟器,但是从来没有给我写邮件说明他们遇到性能问题”,这些邮件我会一律删除。
如果我们想要在移动Web开发(或者是原生应用,或者是任何其它事情)上取得一些进展,我们都需要各种至少看上去有说服力(at least appear to have a plausible basis)的讨论,包括benchmark、期刊以及编译器作者们的引用等等。网上有很多HN关于“我曾经写了一个Web应用,挺好”的评论,还有很多关于Facebook在知道他们将会知道现在应该知道的东西的情况下(译注:原味knowing what they would have known then what they could have known now,不知这样翻译对不对?)是选择HTML5还是原生应用是对是错的争论(译注:原文为bikeshedding,这是一个比较有意思的词,意思是在还没完成自行车车架还没弄好的情况下就去讨论车的颜色,意指过于关心细节和边缘的问题,而忽视主要问题)。
对于我们来说,剩下来的任务是,明确地量化如何使得移动Web和原生生态环境变得越来越好,接着为此做出一些事情。正如你所知,这也是一个软件开发者应该做的事情。
201509281125_《为什么移动app会很慢的深度分析(摘自司徒正美博客园文章)》
标签:
原文地址:http://www.cnblogs.com/beesky520/p/4843631.html