标签:
一、线性时间排序算法历史概览
计数排序首先是由 Harold H. Seward 于1954年提出,而且他还提出将计数排序和基数排序进行结合的思想;基数排序是L.J.Comrie于1929年首次在一篇描述卡片穿孔机文档中提出的一种方法,它是从最低有效位开始,对一个有多位数组成的数进行排序的方法;而桶排序的基本思想则由E.J.Isaac和R.C.Singleton于1956年提出的,之后很多研究人员在这三种算法的基础上针对不同的应用场景又进一步改进,到了今天一个很成熟、很通用的地步。
二、O(nlgn)到O(n)的排序转变
从最初的O(n^2)到O(nlgn),再到O(n),排序算法的时间复杂度从非线性的时间要求到线性时间要求,这里面汇集了多少算法大牛的心血和智慧,从另外一个侧面也说明了算法的世界充满了多少奇思妙想的可能,只要稍微改动一下语句的表达,或许就能对算法的性能有一定的提升。本书这一部分都是着眼于排序算法,经历了从O(n^2)到O(n)的转变,让我惊叹算法的神奇之余,也让我有很大的动力去探索这些算法是怎么样一步步地进行优化改进,它们的主要的思想体现在什么地方,为什么稍微加点东西就能对算法性能有了质的提升。这些问题迫使我不由自主的思考,从而加快阅读的速度,也让自己的理解、记忆能力进一步得到了提升。虽然之前这些算法都有接触,也都写过,但是当时只是学着怎么应用,根本没有懂本质,所以,再一次看的时候,感觉仍然在看新东西一样,想不起来这个算法大概的一个思路。所以,在看书,尤其是在看专业书的时候,带着问题和好奇去阅读,会让自己阅读的质量有很大的提高,而且能够加深理解和记忆,达到事半功倍的效果。
这一章介绍的几种排序:计数排序、基数排序、桶排序都是线性时间排序算法,即这几个算法的时间复杂度都可以达到O(n);而之前几章介绍的几种算法:快速排序、堆排序、归并排序,插入排序等算法最好情况下的时间复杂度都为O(nlgn)。再进一步对这些算法分析可以发现一个有趣的性质:在排序的最终结果中,各元素的次序依赖于它们之间的比较,也就是说任何比较排序在最好情况下都要经过Ω(nlgn),即比较排序的下界为Ω(nlgn)。而本章所介绍的三种算法之所以时间复杂度降为线性的,就是因为没有出现比较,而是通过运算的方式。
1、决策树模型
决策树模型是对比较算法的时间复杂度为什么至少为O(nlgn)的理论性证明。如下图所示,显示了插入排序算法作用于包含3个元素的输入序列的决策树情况:
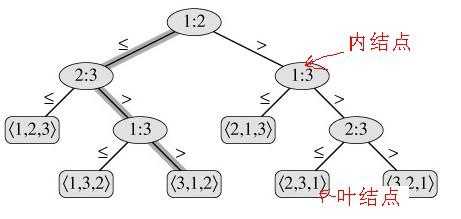
在这样的一棵决策树中,每个内部节点都以i:j标记,排序算法的执行对应于一条从树的根节点到叶节点的路径。每个内部节点表示一次比较ai <= aj,左子树表示ai <= aj的后续比较,右子树表示ai > aj的后续比较,一旦到达叶子节点,表示一次排序完成。如果有n个节点,根据组合问题可知一共有n!种可能的排序序列。因此,在一棵决策树中,从根到任意一个可达叶结点之间的最长路径的长度,就表示对应的排序算法中最坏情况下的比较次数。这样,一个比较算法的最坏情况的比较次数就是其决策树的高度。通过树的相关概念的证明,可知一棵具有n个节点的树的高度为lgn,所以最坏情况下,任何比较排序算法的时间复杂度为Ω(nlgn)。
三、计数排序
计数排序假设n个输入元素都是在0~k区间上的一个整数,其中k为常数。算法的基本思想是:对于每一个输入元素x,通过确定小于x的元素个数,可以直接把x放到属于它的正确位置上,比如10这个数比它小的数有5个,那么它就放到6号位置上,如果有相同的数,则略作修改。所以,为了实现算法的要求,我们需要两个临时数组C[0,,,k]和B[1,,,n]来分别表示“计数数组”和“输出数组”。代码如下:
1 //计数排序 2 void CountingSort(int arrA[], int arrB[], int len, int k) 3 { 4 int *arrC = new int[k+1]; 5 for (int i = 0; i <= k; i ++) 6 arrC[i] = 0; 7 8 for (int i = 0; i < len; i ++) 9 arrC[arrA[i]] = arrC[arrA[i]] + 1;//arrC[i] contains the number of elements equal to i. 10 11 for (int i = 1; i <= k; i ++) 12 arrC[i] = arrC[i] + arrC[i-1]; //arrC[i] contains the number of elements less than or equal to i. 13 14 //(1) from back to front !stable 15 for (int j = len-1; j >=0; j --) { 16 arrB[arrC[arrA[j]]-1] = arrA[j]; //index start from 0 17 arrC[arrA[j]] = arrC[arrA[j]] - 1; 18 } 19 //(2) from front to back ! not stable 20 // for (int j = 0; j < len; j ++) { 21 // arrB[arrC[arrA[j]]-1] = arrA[j]; 22 // arrC[arrA[j]] = arrC[arrA[j]] - 1; 23 // } 24 }
四、基数排序
基数排序是一种用在卡片排序机上的算法,普通的卡片有80列,每一列有12个孔,操作员根据卡片给定列上的数字来选定应该放入哪个孔,从而对所有的列的数字完成排序,如下一种直观的显示:
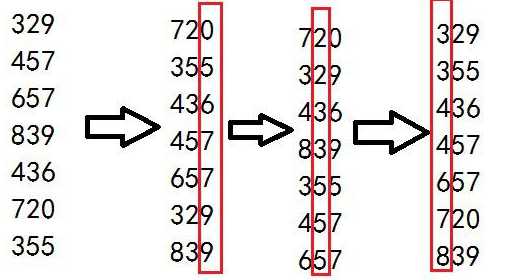
对于10进制数来说,每列只会用到10个数字,有多少位数就表示有多少列,对于每一列的数字,我们可以采用任何排序算法,但最好使用稳定排序,由于每一列的输入的所有元素都为0~10之间的元素(对于10进制数),很明显,我们应该采用计数排序来进行。如下为使用计数排序来实现基数排序的代码:
1 void RadixSort(int arrA[], int arrB[], int len, int d) 2 { 3 int *arrC = new int[10]; //most 10 numbers; 4 5 int radix = 1; 6 for (int k = 1; k <= d; k ++) { 7 //using CountingSort for every bit; 8 for (int i = 0; i < 10; i ++) 9 arrC[i] = 0; 10 11 for (int i = 0; i < len; i ++) { 12 int temp = (arrA[i]/radix) % 10; //find every bit of a number 13 arrC[temp] = arrC[temp] + 1; 14 } 15 for (int i = 1; i < 10; i ++) 16 arrC[i] = arrC[i] + arrC[i-1]; 17 18 for (int j = len-1; j >= 0; j --) { 19 int temp = (arrA[j]/radix) % 10; 20 arrB[arrC[temp] - 1] = arrA[j]; 21 arrC[temp] = arrC[temp] - 1; 22 } 23 radix *= 10; //another bit; 24 memcpy(arrA, arrB, len * sizeof(int)); //note this line; 25 } 26 }
五、桶排序
与计数排序类似,桶排序也对输入数据作了某种假设:假设输入数据服从均匀分布。具体来说,桶排序假设输入由一个随机过程产生,该过程将元素均匀、独立地分布在[0,1)区间上。也就是桶排序将[0,1)区间划分为n个大小相同的子区间,或称为桶(这就是桶排序名称的由来),然后n个输入数据分别放到各个桶中,因为输入数据是均匀、独立地分布在[0,1)区间上,所以一般不会出现很多数落在同一个桶中的情况。
1、桶排序的思路
假设输入是一个包含n个均匀分布的元素的数组A,为了完成桶排序,需要一个临时数组B来充当桶(一般是10个桶,因为对于数字来说,一位的数字有10个)。算法的核心就是将n个数根据其对应的“数字大小”均匀地分配到各个桶中,如果有相同的数字,则放在一个桶中,并进行一定移位操作使它们有序。如下:
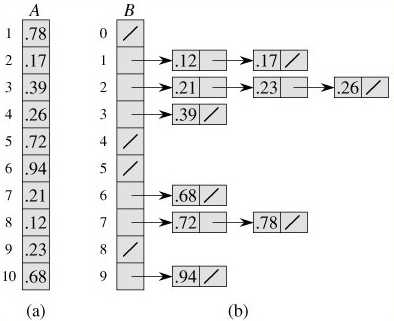
BUCKET-SORT(A) 1 n ← length[A] 2 for i ← 1 to n 3 do insert A[i] into list B[⌊n A[i]⌋] 4 for i ← 0 to n - 1 5 do sort list B[i] with insertion sort 6 concatenate the lists B[0], B[1], . . ., B[n - 1] together in order
其中桶的形式可以采用数组(二维),也可以采用链表。两种方式我们都用代码实现一遍,如下:
二维数组作为桶:

1 #include <iostream> 2 #include <iomanip> 3 #include <ctime> 4 using namespace std; 5 6 void BucketSort(double arrA[], int nLen); 7 void PrintArr(double *arr,int n); 8 void InitialArr(double *arr, int n); 9 10 void BucketSort(double arrA[], int nLen) 11 { 12 //the bucket; 13 double **pBucketB = new double *[10]; //!!! 14 for (int i = 0; i < nLen; i ++) 15 pBucketB[i] = new double[nLen]; 16 17 //the count 18 int *pCount = new int[nLen]; 19 for (int i = 0; i < nLen; i ++) 20 pCount[i] = 0; 21 22 for (int i = 0; i < nLen; i ++) { 23 double nTemp = arrA[i]; 24 int nValue = int(arrA[i]*10); 25 26 int nCount = pCount[nValue]; 27 if (nCount == 0) { 28 pBucketB[nValue][nCount] = nTemp; 29 pCount[nValue] ++; 30 } 31 else { 32 //using the InsertSort; 33 for (; nCount > 0 && nTemp < pBucketB[nValue][nCount-1]; nCount--) { 34 pBucketB[nValue][nCount] = pBucketB[nValue][nCount-1]; 35 } 36 pBucketB[nValue][nCount] = nTemp; 37 pCount[nValue] ++; 38 } 39 } 40 41 //link all elements 42 int k = 0; 43 for (int i = 0; i < 10; i ++) { 44 for (int j = 0; j < pCount[i]; j ++) { 45 arrA[k++] = pBucketB[i][j]; 46 } 47 } 48 49 //delete all bucket; 50 for (int i = 0; i < 10; i ++) { 51 delete pBucketB[i]; 52 pBucketB[i] = NULL; 53 } 54 delete []pBucketB; 55 pBucketB = NULL; 56 } 57 58 // initial arr 59 void InitialArr(double *arr, int n) 60 { 61 srand((unsigned)time(NULL)); 62 for (int i = 0; i < n; i ++) 63 arr[i] = rand() / double(RAND_MAX+1); 64 } 65 66 /* print arr*/ 67 void PrintArr(double *arr,int n) 68 { 69 for (int i = 0;i < n; i++){ 70 //cout<<setw(15)<<arr[i]; 71 cout << arr[i] << " "; 72 if ((i+1)%5 == 0 || i == n-1){ 73 cout<<endl; 74 } 75 } 76 } 77 78 int main() 79 { 80 //double arr[10] = {0.78, 0.17, 0.39,0.26,0.72,0.94,0.21,0.12,0.23,0.68}; 81 double *arr = new double[10]; 82 InitialArr(arr, 10); 83 BucketSort(arr, 10); 84 PrintArr(arr, 10); 85 return 0; 86 }
普通链表作为桶:
1 #include <iostream> 2 3 using namespace std; 4 5 typedef struct BucketNode{ 6 double nValue; 7 BucketNode *pNext; 8 }Node; 9 10 void BucketSort_Link(double arrA[], int nLen) 11 { 12 Node *pBucket = new Node[10]; 13 14 //initial the bucket 15 for (int i = 0; i < 10; i ++) { 16 pBucket[i].nValue = 0.0; 17 pBucket[i].pNext = NULL; 18 } 19 20 for (int i = 0; i < nLen; i ++) { 21 double nTemp = arrA[i]; 22 Node *pNode = new Node(); 23 pNode->nValue = nTemp; 24 pNode->pNext = NULL; 25 26 int nKey = int(arrA[i]*10); 27 28 if (pBucket[nKey].pNext == NULL) { 29 pBucket[nKey].pNext = pNode; //每个桶的第一个位置不存数据 30 } 31 else { 32 Node *p = &pBucket[nKey]; //p-->q 33 Node *q = pBucket[nKey].pNext; 34 35 while (q && q->nValue <= nTemp) { 36 p = q; 37 q = q->pNext; 38 } 39 40 pNode->pNext = q; 41 p->pNext = pNode; 42 } 43 } 44 45 int k = 0; 46 for (int i = 0; i < 10; i ++) { 47 Node *pTemp = pBucket[i].pNext; 48 while (pTemp) { 49 arrA[k ++] = pTemp->nValue; 50 pTemp = pTemp->pNext; 51 } 52 } 53 } 54 55 int main() 56 { 57 double arr[10] = {0.78, 0.17, 0.39,0.26,0.72,0.94,0.21,0.12,0.23,0.68}; 58 BucketSort_Link(arr, 10); 59 for(int i = 0; i < 10; i ++) 60 cout << arr[i] << " "; 61 62 cout << endl; 63 cout << rand()/RAND_MAX; 64 return 0; 65 }
六:总结
1、本章介绍的几种算法都是线性时间的排序算法,通过学习,或许大家也注意到了,之所以能达到这样的复杂度要求,原因就是空间换时间:计数排序申请了O(n+k)的临时空间,基数排序申请了O(n+k)(如果采用计数排序),桶排序申请了O(k*n)。
2、时间复杂度上,计数排序为Θ(n+k)(当k=O(n), 为Θ(n),在实际中常用); 基数排序为Θ(d(n+k))(当采用的稳定排序的复杂度为Θ(n+k)时);桶排序为Θ(n)(严格推导见书本)。
3、其实,总的来说,三种排序算法在输入元素都做了一定的假设,基数排序归在计数排序中(因为我们平常应用中,都将计数排序作为基数排序的稳定排序来实现)。计数排序假设所有数据都属于一个小区间内的整数(0~k),而桶排序则假设输入是由一个随机过程产生,该过程将元素均匀、独立地分布在[0,1)区间上,即桶。
标签:
原文地址:http://www.cnblogs.com/bakari/p/4845016.html
