标签:
使用线程池与不使用线程池的差别
先来看一下使用线程池与不适应线程池的差别,第一段代码是使用线程池的:
public static void main(String[] args) { long startTime = System.currentTimeMillis(); final List<Integer> l = new LinkedList<Integer>(); ThreadPoolExecutor tp = new ThreadPoolExecutor(100, 100, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<Runnable>(20000)); final Random random = new Random(); for (int i = 0; i < 20000; i++) { tp.execute(new Runnable() { public void run() { l.add(random.nextInt()); } }); } tp.shutdown(); try { tp.awaitTermination(1, TimeUnit.DAYS); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(System.currentTimeMillis() - startTime); System.out.println(l.size()); }
接着是不使用线程池的:
public static void main(String[] args) { long startTime = System.currentTimeMillis(); final List<Integer> l = new LinkedList<Integer>(); final Random random = new Random(); for (int i = 0; i < 20000; i++) { Thread thread = new Thread() { public void run() { l.add(random.nextInt()); } }; thread.start(); try { thread.join(); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println(System.currentTimeMillis() - startTime); System.out.println(l.size()); }
运行一下,我这里第一段代码使用了线程池的时间是194ms,第二段代码不使用线程池的时间是2043ms。这里默认的线程池中的线程数是100,如果把这个数量减小,虽然系统的处理数据能力变弱了,但是速度却更快了。当然这个例子很简单,但也足够说明问题了。
线程池的作用
线程池的作用就2个:
1、减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务
2、可以根据系统的承受能力,调整线程池中工作线程的数据,防止因为消耗过多的内存导致服务器崩溃
使用线程池,要根据系统的环境情况,手动或自动设置线程数目。少了系统运行效率不高,多了系统拥挤、占用内存多。用线程池控制数量,其他线程排队等候。一个任务执行完毕,再从队列中取最前面的任务开始执行。若任务中没有等待任务,线程池这一资源处于等待。当一个新任务需要运行,如果线程池中有等待的工作线程,就可以开始运行了,否则进入等待队列。
线程池类结构
画了一张图表示线程池的类结构图:
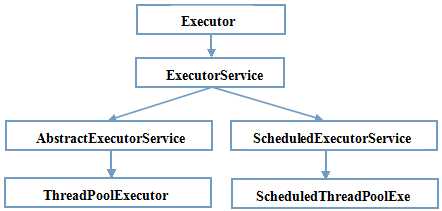
这张图基本简单代表了线程池类的结构:
1、最顶级的接口是Executor,不过Executor严格意义上来说并不是一个线程池而只是提供了一种任务如何运行的机制而已
2、ExecutorService才可以认为是真正的线程池接口,接口提供了管理线程池的方法
3、下面两个分支,AbstractExecutorService分支就是普通的线程池分支,ScheduledExecutorService是用来创建定时任务的
ThreadPoolExecutor
这篇文章重点讲的就是线程池ThreadPoolExecutor,开头也演示过ThreadPoolExecutor的使用了,下面来看一下ThreadPoolExecutor完整构造方法的签名并一一了解一下每个参数的作用用以理解ThreadPoolExecutor:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)
逐一看一下每个参数的意思,来自JDK API:
1、corePoolSize
池中所保持的线程数,包括空闲线程
2、maximumPoolSize
池中允许的最大线程数
3、keepAliveTime
当线程数大于corePoolSize时,终止前多余的空闲线程等待新任务的最长时间
4、unit
keepAliveTime时间单位
5、workQueue
存储还没来得及执行的任务
6、threadFactory
执行程序创建新线程时使用的工厂
7、handler
由于超出线程范围和队列容量而使执行被阻塞时所使用的处理程序
上面的内容,看起来corePoolSize和maximumPoolSize不太好理解,所以要特别以四条规则解释一下这两个参数:
1、池中线程数小于corePoolSize,新任务都不排队而是直接添加新线程
2、池中线程数大于等于corePoolSize,workQueue未满,首选将新任务假如workQueue而不是添加新线程
3、池中线程数大于等于corePoolSize,workQueue已满,但是线程数小于maximumPoolSize,添加新的线程来处理被添加的任务
4、池中线程数大于大于corePoolSize,workQueue已满,并且线程数大于等于maximumPoolSize,新任务被拒绝,使用handler处理被拒绝的任务
ThreadPoolExecutor的使用很简单,前面的代码也写过例子了。通过execute(Runnable command)方法来发起一个任务的执行,通过shutDown()方法来对已经提交的任务做一个有效的关闭。尽管线程池很好,但我们要注意JDK API的一段话:
强烈建议程序员使用较为方便的Executors工厂方法Executors.newCachedThreadPool()(无界线程池,可以进行线程自动回收)、Executors.newFixedThreadPool(int)(固定大小线程池)和Executors.newSingleThreadExecutor()(单个后台线程),它们均为大多数使用场景预定义了设置。
所以,跳开对ThreadPoolExecutor的关注(还是那句话,有问题查询JDK API),重点关注一下JDK推荐的Executors。
Executors
个人认为,线程池的重点不是ThreadPoolExecutor怎么用或者是Executors怎么用,而是在合适的场景下使用合适的线程池,所谓"合适的线程池"的意思就是,ThreadPoolExecutor的构造方法传入不同的参数,构造出不同的线程池,以满足使用的需要。
下面来看一下Executors为用户提供的几种线程池:
1、newSingleThreadExecutos() 单线程线程池
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }
单线程线程池,那么线程池中运行的线程数肯定是1。workQueue选择了无界的LinkedBlockingQueue,那么不管来多少任务都排队,前面一个任务执行完毕,再执行队列中的线程。从这个角度讲,第二个参数maximumPoolSize是没有意义的,因为maximumPoolSize描述的是排队的任务多过workQueue的容量,线程池中最多只能容纳maximumPoolSize个任务,现在workQueue是无界的,也就是说排队的任务永远不会多过workQueue的容量,那maximum其实设置多少都无所谓了
2、newFixedThreadPool(int nThreads) 固定大小线程池
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
固定大小的线程池和单线程的线程池异曲同工,无非是让线程池中能运行的线程编程了手动指定的nThreads罢了。同样,由于是选择了LinkedBlockingQueue,因此其实第二个参数maximumPoolSize同样也是无意义的
3、newCachedThreadPool() 无界线程池
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
无界线程池,意思是不管多少任务提交进来,都直接运行。无界线程池采用了SynchronousQueue,采用这个线程池就没有workQueue容量一说了,只要添加进去的线程就会被拿去用。既然是无界线程池,那线程数肯定没上限,所以以maximumPoolSize为主了,设置为一个近似的无限大Integer.MAX_VALUE。 另外注意一下,单线程线程池和固定大小线程池线程都不会进行自动回收的,也即是说保证提交进来的任务最终都会被处理,但至于什么时候处理,就要看处理能力了。但是无界线程池是设置了回收时间的,由于corePoolSize为0,所以只要60秒没有被用到的线程都会被直接移除
谈谈workQueue
上面三种线程池都提到了一个概念,workQueue,也就是排队策略。排队策略描述的是,当前线程大于corePoolSize时,线程以什么样的方式排队等待被运行。
排队有三种策略:直接提交、有界队列、无界队列。
谈谈后两种,JDK使用了无界队列LinkedBlockingQueue作为WorkQueue而不是有界队列ArrayBlockingQueue,尽管后者可以对资源进行控制,但是个人认为,使用有界队列相比无界队列有三个缺点:
1、使用有界队列,corePoolSize、maximumPoolSize两个参数势必要根据实际场景不断调整以求达到一个最佳,这势必给开发带来极大的麻烦,必须经过大量的性能测试。所以干脆就使用无界队列,任务永远添加到队列中,不会溢出,自然maximumPoolSize也没什么用了,只需要根据系统处理能力调整corePoolSize就可以了
2、防止业务突刺。尤其是在Web应用中,某些时候突然大量请求的到来都是很正常的。这时候使用无界队列,不管早晚,至少保证所有任务都能被处理到。但是使用有界队列呢?那些超出maximumPoolSize的任务直接被丢掉了,处理地慢还可以忍受,但是任务直接就不处理了,这似乎有些糟糕
3、不仅仅是corePoolSize和maximumPoolSize需要相互调整,有界队列的队列大小和maximumPoolSize也需要相互折衷,这也是一块比较难以控制和调整的方面
当然,最后还是那句话,就像Comparable和Comparator的对比、synchronized和ReentrantLock,再到这里的无界队列和有界队列的对比,看似都有一个的优点稍微突出一些,但是这绝不是鼓励大家使用一个而不使用另一个,任何东西都需要根据实际情况来,当然在一开始的时候可以重点考虑那些看上去优点明显一点的
四种拒绝策略
所谓拒绝策略之前也提到过了,任务太多,超过maximumPoolSize了怎么把?当然是接不下了,接不下那只有拒绝了。拒绝的时候可以指定拒绝策略,也就是一段处理程序。
决绝策略的父接口是RejectedExecutionHandler,JDK本身在ThreadPoolExecutor里给用户提供了四种拒绝策略,看一下:
1、AbortPolicy
直接抛出一个RejectedExecutionException,这也是JDK默认的拒绝策略
2、CallerRunsPolicy
尝试直接运行被拒绝的任务,如果线程池已经被关闭了,任务就被丢弃了
3、DiscardOldestPolicy
移除最晚的那个没有被处理的任务,然后执行被拒绝的任务。同样,如果线程池已经被关闭了,任务就被丢弃了
4、DiscardPolicy
不能执行的任务将被删除
标签:
原文地址:http://www.cnblogs.com/xrq730/p/4856453.html