标签:
简介: 本文基于Linux?系统对进程创建与加载进行分析,文中实现了Linux库函数fork、exec,剖析内核态执行过程,并进一步展示进程创建过程中进程控制块字段变化信息及ELF文件加载过程。
一、初识Linux进程
进程这个概念是针对系统而不是针对用户的,对用户来说,他面对的概念是程序。当用户敲入命令执行一个程序的时候,对系统而言,它将启动一个进程。但和程序不同的是,在这个进程中,系统可能需要再启动一个或多个进程来完成独立的多个任务。简单介绍下进程的结构。
1.1 Linux下的进程查看
我们可以使用$ps命令来查询正在运行的进程,比如$ps -eo pid,comm,cmd,下图为执行结果:
(-e表示列出全部进程,-o pid,comm,cmd表示我们需要PID,COMMAND,CMD信息)

每一行代表了一个进程。每一行又分为三列。第一列PID(process IDentity)是一个整数,每一个进程都有一个唯一的PID来代表自己的身份,进程也可以根据PID来识别其他的进程。第二列COMMAND是这个进程的简称。第三列CMD是进程所对应的程序以及运行时所带的参数。
(第三列有一些由中括号[]括起来的。它们是kernel的一部分功能,显示为进程的样子主要是为了方便操作系统管理。)
我们看第一行,PID为1,名字为init。这个进程是执行/bin/init这一文件(程序)生成的。当Linux启动的时候,init是系统创建的第一个进程,这一进程会一直存在,直到我们关闭计算机。
1.2 Linux下进程的结构
Linux下一个进程在内存里有三部分的数据,就是"代码段"、"堆栈段"和"数据段"。其实学过汇编语言的人一定知道,一般的CPU都有上述三种段寄存器,以方便操作系统的运行。这三个部分也是构成一个完整的执行序列的必要的部分。
"代码段",顾名思义,就是存放了程序代码的数据,假如机器中有数个进程运行相同的一个程序,那么它们就可以使用相同的代码段。"堆栈段"存放的就是子程序的返回地址、子程序的参数以及程序的局部变量。而数据段则存放程序的全局变量,常数以及动态数据分配的数据空间(比如用malloc之类的函数取得的空间)。系统如果同时运行数个相同的程序,它们之间就不能使用同一个堆栈段和数据段。
1.3 Linux进程描述符
在Linux中每一个进程都由task_struct 数据结构来定义.task_struct就是我们通常所说的PCB.它是对进程控制的唯一手段也是最有效的手段. 当我们调用fork() 时,系统会为我们产生一个task_struct结构。然后从父进程,那里继承一些数据, 并把新的进程插入到进程树中,以待进行进程管理。
以下是进程描述符的源码:

1 struct task_struct { 2 volatile long state; 3 unsigned long flags; 4 int sigpending; 5 mm_segment_taddr_limit; 6 volatile long need_resched; 7 int lock_depth; 8 long nice; 9 unsigned long policy; 10 struct mm_struct *mm; 11 int processor; 12 unsigned long cpus_runnable, cpus_allowed; 13 struct list_head run_list; 14 unsigned longsleep_time; 15 struct task_struct *next_task, *prev_task; 16 struct mm_struct *active_mm; 17 struct list_headlocal_pages; 18 unsigned int allocation_order, nr_local_pages; 19 struct linux_binfmt *binfmt; 20 int exit_code, exit_signal; 21 int pdeath_signal; 22 unsigned long personality; 23 int did_exec:1; 24 pid_t pid; 25 pid_t pgrp; 26 pid_t tty_old_pgrp; 27 pid_t session; 28 pid_t tgid; 29 int leader; 30 struct task_struct*p_opptr,*p_pptr,*p_cptr,*p_ysptr,*p_osptr; 31 struct list_head thread_group; 32 struct task_struct *pid hash_next; 33 struct task_struct **pid hash_pprev; 34 wait_queue_head_t wait_chldexit; 35 struct completion *vfork_done; 36 unsigned long rt_priority; 37 unsigned long it_real_value, it_prof_value, it_virt_value; 38 unsigned long it_real_incr, it_prof_incr, it_virt_value; 39 struct timer_listreal_timer; 40 struct tmstimes; 41 unsigned long start_time; 42 long per_cpu_utime[NR_CPUS],per_cpu_stime[NR_CPUS]; 43 uid_t uid,euid,suid,fsuid; 44 gid_t gid,egid,sgid,fsgid; 45 int ngroups; 46 gid_t groups[NGROUPS]; 47 kernel_cap_tcap_effective, cap_inheritable, cap_permitted; 48 int keep_capabilities:1; 49 struct user_struct *user; 50 struct rlimit rlim[RLIM_NLIMITS]; 51 unsigned shortused_math; 52 charcomm[16]; 53 int link_count, total_link_count; 54 struct tty_struct*tty; 55 unsigned int locks; 56 struct sem_undo*semundo; 57 struct sem_queue *semsleeping; 58 struct thread_struct thread; 59 struct fs_struct *fs; 60 struct files_struct *files; 61 spinlock_t sigmask_lock; 62 struct signal_struct *sig; 63 sigset_t blocked; 64 struct sigpendingpending; 65 unsigned long sas_ss_sp; 66 size_t sas_ss_size; 67 int (*notifier)(void *priv); 68 void *notifier_data; 69 sigset_t *notifier_mask; 70 u32 parent_exec_id; 71 u32 self_exec_id; 72 spinlock_t alloc_lock; 73 void *journal_info; 74 };
主要结构分析:
volatile long state; 说明了该进程是否可以执行,还是可中断等信息
unsigned long flags; Flage 是进程号,在调用fork()时给出
int sigpending; 进程上是否有待处理的信号
mm_segment_taddr_limit; 进程地址空间,区分内核进程与普通进程在内存存放的位置不同(0-0xBFFFFFFF foruser-thead 0-0xFFFFFFFF forkernel-thread)
volatile long need_resched;调度标志,表示该进程是否需要重新调度,若非0,则当从内核态返回到用户态,会发生调度
struct mm_struct *mm; 进程内存管理信息
pid_tpid; 进程标识符,用来代表一个进程
pid_tpgrp; 进程组标识,表示进程所属的进程组
task_struct的数据成员mm指向关于存储管理的struct mm_struct结构。它包含着进程内存管理的很多重要数据,如进程代码段、数据段、未未初始化数据段、调用参数区和进程。
二、 如何创建一个进程
2.1 Linux下的进程控制
在传统的Linux环境下,有两个基本的操作用于创建和修改进程:函数fork()用来创建一个新的进程,该进程几乎是当前进程的一个完全拷贝;函数族exec( )用来启动另外的进程以取代当前运行的进程。
关于fork()与execl(),去年写过一篇文章对部分源码进行过分析:system()和execv()函数使用详解
2.2 fork()
一个进程在运行中,如果使用了fork,就产生了另一个进程。下面就看看如何具体使用fork,这段程序演示了使用fork的基本框架:
#include <stdio.h> void main() { int i; if ( fork() == 0 ) { /* 子进程程序 */ for ( i = 1; i <1000; i ++ ) printf("This is child process\n"); } else { /* 父进程程序*/ for ( i = 1; i <1000; i ++ ) printf("This is origin process\n"); } }
运行结果如下:

从上图可以看出父进程和子进程并发运行,内核能够以任意方式交替运行它们,这里是父进程先运行,然后是子进程。但是在另外一个系统上运行时不一定是这个顺序。
使用fork函数创建的子进程从父进程的继承了全部进程的地址空间,包括:进程上下文、进程堆栈、内存信息、打开的文件描述符、信号控制设置、进程优先级、进程组号、当前工作目录、根目录、资源限制、控制终端等。
fork创建子进程,首先调用int80中断,然后将系统调用号保存在eax寄存器中,进入内核态后调用do_fork(),实际上是创建了一份父进程的拷贝,他们的内存空间里包含了完全相同的内容,包括当前打开的资源,数据,当然也包含了程序运行到的位置,也就是说fork后子进程也是从fork函数的位置开始往下执行的,而不是从头开始。而为了判别当前正在运行的是哪个进程,fork函数返回了一个pid,在父进程里标识了子进程的id,在子进程里其值为0,在我们的程序里就根据这个值来分开父进程的代码和子进程的代码。

一旦使用fork创建子进程,则进程地址空间中的任何有效地址都只能位于唯一的区域,这些区域不能相互覆盖。编写如下代码进行测试:
1 #include <stdio.h> 2 #include <sys/types.h> 3 #include <unistd.h> 4 5 struct con { 6 int a; 7 }; 8 9 int main() { 10 pid_t pid; 11 struct con s; 12 s.a = 2; 13 struct con* sp = &s; 14 pid = fork(); 15 if (pid > 0) { 16 printf("parent show %p, %p, a = %d\n", sp, &sp->a, sp->a); 17 sp->a = 1; 18 sleep(10); 19 printf("parent show %p, %p, a = %d\n", sp, &sp->a, sp->a); 20 printf("parent exit\n"); 21 } 22 else { 23 printf("child show %p, %p, a = %d\n", sp, &sp->a, sp->a); 24 sp->a = -1; 25 printf("child change a to %d\n", sp->a); 26 } 27 return 0; 28 }
获得结果如下:

从上面的分析可以看出进程copy过程中,fork就是基于写时复制,只读代码段是可以同享的,一般CPU都是以"页"为单位来分配内存空间的,每一个页都是实际物理内存的一个映像,象INTEL的CPU,其一页在通常情况下是 4086字节大小,而无论是数据段还是堆栈段都是由许多"页"构成的,fork函数复制这两个段,物理空间上两个进程的数据段和堆栈段都还是共享着的,当有一个进程写了某个数据时,这时两个进程之间的数据才有了区别,系统就将有区别的" 页"从物理上也分开。系统在空间上的开销就可以达到最小。
2.3 exec( )函数族
下面我们来看看一个进程如何来启动另一个程序的执行。在Linux中要使用exec函数族。系统调用execve()对当前进程进行替换,替换者为一个指定的程序,其参数包括文件名(filename)、参数列表(argv)以及环境变量(envp)。exec函数族当然不止一个,但它们大致相同,在 Linux中,它们分别是:execl,execlp,execle,execv,execve和execvp,下面以execve为例。
一个进程一旦调用exec类函数,它本身就"死亡"了,execve首先调用int80中断,然后将系统调用号保存在eax寄存器中,调用sys_exec,将可执行程序加载到当前进程中,系统把代码段替换成新的程序的代码,废弃原有的数据段和堆栈段,并为新程序分配新的数据段与堆栈段,唯一留下的,就是进程号,也就是说,对系统而言,还是同一个进程,不过已经是另一个程序了。(不过exec类函数中有的还允许继承环境变量之类的信息。)
那么如果我的程序想启动另一程序的执行但自己仍想继续运行的话,怎么办呢?那就是结合fork与exec的使用。下面一段代码显示如何启动运行其它程序:
1 #include <stdio.h> 2 #include <unistd.h> 3 int main(){ 4 if(!fork()) 5 execve("./test",NULL,NULL); 6 else 7 printf("origin process!\n"); 8 return 0; 9 }
输出结果如下:

原始进程和execve创建的新进程,并发运行,exec函数在当前进程的上下文中加载并运行一个新的程序,并且不返回创建进程的函数。
接下来,我们分析一下execve函数执行过程中,以及可执行程序的加载过程,在内核中execve()系统调用相应的入口是sys_execve(),函数首先通过 pt_regs参数检查赋值在执行该系统调用时,用户态下的CPU寄存器在核心态的栈中的保存情况。通过这个参数,sys_execve可以获得保存在用户空间的以下信息:可执行文件路径的指针(regs.ebx中)、命令行参数的指针(regs.ecx中)和环境变量的指针(regs.edx中)。
struct pt_regs { long ebx; long ecx; long edx; long esi; long edi; long ebp; long eax; int xds; int xes; long orig_eax; long eip; int xcs; long eflags; long esp; int xss; }
然后调用do_execve函数,首先查找被执行的文件,读取前128个字节,确实加载的可执行文件的类型,然后调用search_binary_handle()搜索和匹配合适的可执行文件装载处理过程,elf调用load_elf_binary();
struct linux_binprm{ char buf[BINPRM_BUF_SIZE]; //保存可执行文件的头128字节 struct page *page[MAX_ARG_PAGES]; struct mm_struct *mm; unsigned long p; //当前内存页最高地址 int sh_bang; struct file * file; //要执行的文件 int e_uid, e_gid; //要执行的进程的有效用户ID和有效组ID kernel_cap_t cap_inheritable, cap_permitted, cap_effective; void *security; int argc, envc; //命令行参数和环境变量数目 char * filename; //要执行的文件的名称 char * interp; //要执行的文件的真实名称,通常和filename相同 unsigned interp_flags; unsigned interp_data; unsigned long loader, exec; };
load_elf_binary()加载过程如下:
a.检查ELF可执行文件的有效性,比如魔数(开头四个字节,elf文件为0x7F),段“Segment”的数量;
b.寻找动态链接.interp段,设置动态连接器的路径;
c.根据elf可执行文件的程序头表的描述,对elf文件进行映射;
d.初始化elf进程环境,比如启动时候的edx寄存器地址是DT_FINI的地址;
e.将系统调用的返回地址修改为elf可执行文件的入口点,就是e_entry所存的地址。对于动态链接的elf可执行文件就是动态连接器。
加载完成后返回do_execve返回到exeve(),从内核态转化为用户态并返回e步所在更改的程序入口地址。即eip存储器直接跳转到elf程序的入口地址,新进程执行。
三、 进程虚拟地址空间与可执行程序格式
从操作系统来看,一进程最关键的特征是它拥有独立的虚拟地址空间,一般情况下,创建过程如下:
①创建一个独立的虚拟空间。
②读取可执行文件头,并且简历虚拟空间与可执行文件的映射关系。
③将CPU的指令寄存器设置成可执行文件的入口地址,启动运行。
在讨论地址空间,进程描述符以及ELF文件格式的之前,我们先介绍一点预备知识,由于第一节已经介绍了进程描述符的部分信息,在这里介绍下ELF文件格式:

在第二节使用execve时,我们使用了test可执行程序进行测试,代码如下:
#include <stdio.h> int main(int argc, char const *argv[]) { printf("%s\n","execve the new process!"); return 0; }
描述“Segment”的结构叫程序头,它描述了ELF文件该如何被操作系统映射到进程的虚拟空间:

上图共有5个Segment。从装载的角度看,我们只关心两个LOAD和DYNAMIC,其他Segment在装载过程中只具有辅助作用,映射过程中,根据读写执行权限映射到不同的虚拟内存区域
第四行LOAD表示代码段,具有可读可执行权限,被映射到虚拟地址0x08048000,长度为0x005c4字节的虚拟存储区域中。
第五行LOAD表示长度为0x100个字节的数据段,具有可读可写权限,被映射到开始于虚拟地址0x08049f08处,长度为0x0011c字节的虚拟存储区域中。
DYNAMIC字段表示的是动态链接器所需要的基本信息,具有可读可写权限,被映射到开始于虚拟地址0x08049f14处,长度为0x000e8字节的虚拟存储区域中。
在第二节中执行如下命令后,ELF文件正式开始加载工作,执行第二节中的加载过程:
execve("./test",NULL,NULL);
文件在加载过程中是以elf可执行文件的形式加载,加载过程初始化时,根据elf段头部表信息,初始化bss段、代码段和数据段的起始地址和终止地址。
然后调用mm_release释放掉当前进程所占用的内存(old_mm),并且将当前进程的内存空间替换成bprm->mm所指定的页面,而这块空间,便是新进程在初始化时暂时向内核借用的存储空间,当这段空间读取到目前进程的mm以后,事实上也就完成了旧进程到新进程的替换。这个时候bprm->mm这块内核空间也就完成了它的使命,于是被置为NULL予以回收。(bprm为中保存了读取128字节elf文件头)。
mm指向关于存储管理的struct mm_struct结构,其包含在task_struct中。

然后加载段地址到虚拟内存地址,映射如下:

然后另一部分段映射到数据区,关系如下:

到这里,对于elf文件的载入(包括之前对可执行文件运行环境准备工作)的分析基本上可以告一段落了。
四、进程创建中动态链接库的表现形式
动态链接的基本思想是把程序按照模块拆分,运行时才将它们链接在一起形成一个完整的程序,而不是像静态链接一样把所有的程序模块都链接成一个单独的可执行文件。多个动态链接库均以ELF文件存储,执行过程中以依赖树的关系存在,并以深度优先的方式加载动态链接库,最终将可执行程序返回给用户。
我们通过以下实例来测试动态链接库在虚拟地址及ELF文件的中表现形式:
/* Lib.h */ #ifndef LIB_H #define LIB_H void lab(int i) #endif
/* Lib.c */ #include <stdio.h> void lab(int i){ printf("Printing from lib.so %d\n", i); sleep(-1); }
/* dyn.c*/ #include "lib.h" int main(){ lab(1); return 0; }
使用gcc编译生成一个共享对象文件,然后链接dyn.c程序,生成可执行文件dyn:
gcc -fPIC -shared -o lib.so lib.c gcc -o dyn dyn.c ./lib.so
运行并查看进程的虚拟地址空间分布:

整个进程的虚拟地址空间中,多出了几个文件的映射。dyn与lib.so一样,都被系统映射到进程的虚拟地址空间,地址与长度均不相同。由第二节可知,在映射完可执行文件之后,操作系统会先启动一个动态链接器。
动态链接器的的位置由ELF文件中的“.interp”段决定,而段“.dynamic”为动态链接提供了:依赖哪些共享对象、动态链接符号表的位置,动态链接重定位表的位置、共享对象初始化代码的地址等。可通过readelf查看".dynamic" 段的内容:
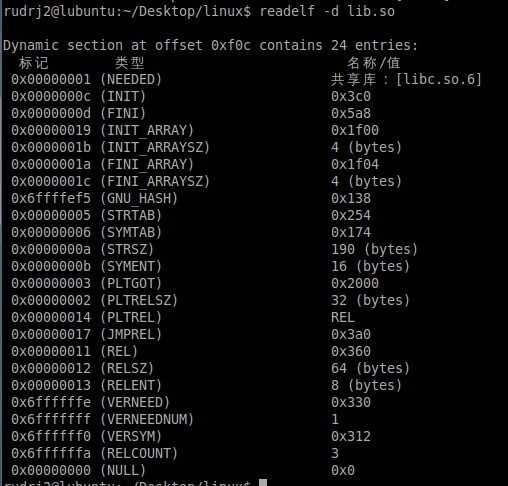 动态链接过程需要动态符号表来确定函数的定义和引用关系,还需要重定位表来修正导入符号的引用。初始化完成后堆栈中保存了动态连接器所需要的一些辅助信息数组(其中包括程序入口地址,程序表头地址,程序表头项数及大小)。动态链接库最后被映射到进程地址空间的共享库区域段。
动态链接过程需要动态符号表来确定函数的定义和引用关系,还需要重定位表来修正导入符号的引用。初始化完成后堆栈中保存了动态连接器所需要的一些辅助信息数组(其中包括程序入口地址,程序表头地址,程序表头项数及大小)。动态链接库最后被映射到进程地址空间的共享库区域段。
完成重定位和初始化后,所有准备工作结束,所需要的共享对象也都已经装载并且链接完成。最后将进程的控制权转交给dyn程序的入口并开始执行。
以上内容均为个人理解,由于能力有限,可能会有诸多错误,希望能够和大家一起讨论修正。
标签:
原文地址:http://my.oschina.net/2xixi/blog/515293