标签:style blog http java color 使用
在平时开发中,我们经常采用HashMap来作为本地缓存的一种实现方式,将一些如系统变量等数据量比较少的参数保存在HashMap中,并将其作 为单例类的一个属性。在系统运行中,使用到这些缓存数据,都可以直接从该单例中获取该属性集合。但是,最近发现,HashMap并不是线程安全的,如果你 的单例类没有做代码同步或对象锁的控制,就可能出现异常。
首先看下在多线程的访问下,非现场安全的HashMap的表现如何,在网上看了一些资料,自己也做了一下测试:
 public static final HashMap<String, String> firstHashMap=new HashMap<String, String>();
public static final HashMap<String, String> firstHashMap=new HashMap<String, String>();  public static void main(String[] args) throws InterruptedException { //线程一 Thread t1=new Thread(){ public void run() { for(int i=0;i<25;i++){ firstHashMap.put(String.valueOf(i), String.valueOf(i));
public static void main(String[] args) throws InterruptedException { //线程一 Thread t1=new Thread(){ public void run() { for(int i=0;i<25;i++){ firstHashMap.put(String.valueOf(i), String.valueOf(i)); } } }; //线程二 Thread t2=new Thread(){ public void run() { for(int j=25;j<50;j++){ firstHashMap.put(String.valueOf(j), String.valueOf(j)); } } }; t1.start(); t2.start(); //主线程休眠1秒钟,以便t1和t2两个线程将firstHashMap填装完毕。 Thread.currentThread().sleep(1000); 这是下边省略号里边的:System.err.println(String.valueOf(l)+":"+firstHashMap.get(String.valueOf(l)));
} } }; //线程二 Thread t2=new Thread(){ public void run() { for(int j=25;j<50;j++){ firstHashMap.put(String.valueOf(j), String.valueOf(j)); } } }; t1.start(); t2.start(); //主线程休眠1秒钟,以便t1和t2两个线程将firstHashMap填装完毕。 Thread.currentThread().sleep(1000); 这是下边省略号里边的:System.err.println(String.valueOf(l)+":"+firstHashMap.get(String.valueOf(l))); for(int l=0;l<50;l++){
//如果key和value不同,说明在两个线程put的过程中出现异常。
if(!String.valueOf(l).equals(firstHashMap.get(String.valueOf(l)))){
System.err.println(String.valueOf(l)+":"+firstHashMap.get(String.valueOf(l)));
}
}
}
}
上面的代码在多次执行后,发现表现很不稳定,有时没有异常文案打出,有时则有个异常出现:
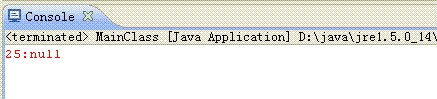
为什么会出现这种情况,主要看下HashMap的实现:
if (key == null) return putForNullKey(value); int hash = hash(key.hashCode()); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; }
}
我觉得问题主要出现在方法addEntry,继续看:
Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<K,V>(hash, key, value, e); if (size++ >= threshold) resize(2 * table.length); }
从代码中,可以看到,如果发现哈希表的大小超过阀值threshold,就会调用resize方法,扩大容量为原来的两倍,而扩大容量的做法是新建一个Entry[]:
Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; transfer(newTable); table = newTable; threshold = (int)(newCapacity * loadFactor); }
一般我们声明HashMap时,使用的都是默认的构造方法:HashMap<K,V>,看了代码你会发现,它还有其它的构造方法:HashMap(int initialCapacity, float loadFactor),其中参数initialCapacity为初始容量,loadFactor为加载因子,而之前我们看到的threshold = (int)(capacity * loadFactor);
如果在默认情况下,一个HashMap的容量为16,加载因子为0.75,那么阀值就是12,所以在往HashMap中put的值到达12时,它将自动扩
容两倍,如果两个线程同时遇到HashMap的大小达到12的倍数时,就很有可能会出现在将oldTable转移到newTable的过程中遇到问题,从
而导致最终的HashMap的值存储异常。
JDK1.0引入了第一个关联的集合类HashTable,它是线程安全的。HashTable的所有方法都是同步的。
JDK2.0引入了HashMap,它提供了一个不同步的基类和一个同步的包装器synchronizedMap。synchronizedMap被称为有条件的线程安全类。
JDK5.0util.concurrent包中引入对Map线程安全的实现ConcurrentHashMap,比起synchronizedMap,它提供了更高的灵活性。同时进行的读和写操作都可以并发地执行。
所以在开始的测试中,如果我们采用ConcurrentHashMap,它的表现就很稳定,所以以后如果使用Map实现本地缓存,为了提高并发时的稳定性,还是建议使用ConcurrentHashMap。
====================================================================
另外,还有一个我们经常使用的ArrayList也是非线程安全的,网上看到的有一个解释是这样:
一个 ArrayList 类,在添加一个元素的时候,它可能会有两步来完成:1. 在 Items[Size] 的位置存放此元素;2. 增大 Size 的值。
在单线程运行的情况下,如果 Size = 0,添加一个元素后,此元素在位置 0,而且 Size=1;
而如果是在多线程情况下,比如有两个线程,线程 A 先将元素存放在位置 0。但是此时 CPU 调度线程A暂停,线程 B
得到运行的机会。线程B也将元素放在位置0,(因为size还未增长),完了之后,两个线程都是size++,结果size变成2,而只有
items[0]有元素。
util.concurrent包也提供了一个线程安全的ArrayList替代者CopyOnWriteArrayList。
非线程安全的HashMap 和 线程安全的ConcurrentHashMap(转载),布布扣,bubuko.com
非线程安全的HashMap 和 线程安全的ConcurrentHashMap(转载)
标签:style blog http java color 使用
原文地址:http://www.cnblogs.com/love-you-girl/p/3850905.html