标签:
1、概述
Logistic regression(逻辑回归)是当前业界比较常用的机器学习方法,用于估计某种事物的可能性。
在经典之作《数学之美》中也看到了它用于广告预测,也就是根据某广告被用 户点击的可能性,把最可能被用户点击的广告摆在用户能看到的地方,然后叫他“你点我啊!”用户点了,你就有钱收了。这就是为什么我们的电脑现在广告泛滥的 原因。还有类似的某用户购买某商品的可能性,某病人患有某种疾病的可能性啊等等。这个世界是随机的(当然了,人为的确定性系统除外,但也有可能有噪声或产生错误的结果,只是这个错误发生的可能性太小了,小到千万年不遇,小到忽略不计而已),所以万物的发生都可以用可能性或者几率(Odds)来表达。“几率”指的是某事物发生的可能性与不发生的可能性的比值。
Logistic regression可以用来回归,也可以用来分类,主要是二分类。
2、基本理论
2.1Logistic regression和Sigmoid函数
回归:假设现在有一些数据点,我们用一条直线对这些点进行拟合(该条称为最佳拟合直线),这个拟合过程就称作回归。利用Logistic回归进行分类的思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。这里的“回归”一词源于最佳拟合,表示找到最佳拟合参数,使用的是最优化算法。
Sigmoid函数具体的计算公式如下:
![]()
z=w0x0+w1x1+w2x2+...+wnxn, z=wTx 其中w是我们要找的最佳参数(系数),x是分类器的输入数据特征。
当x为0时,Sigmoid函数值为0.5,随着x的增大,对应的Sigmoid值将逼近于1;而随着x的减小,Sigmoid值将逼近于0。如果横坐标刻度足够大(如下图所示),Sigmoid函数看起来很像一个阶跃函数。
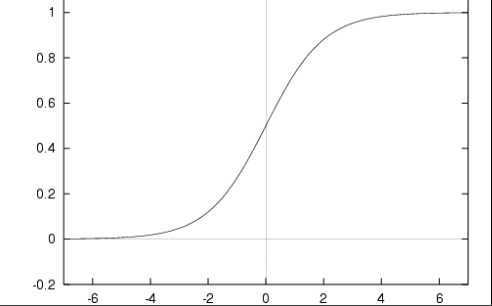
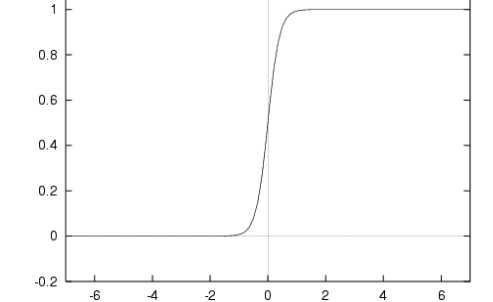
为了实现Logistic回归分类器,我们可以在每个特征上都乘以一个回归系数,然后把所有结果值相加,将这个总和代入Sigmoid函数中,进而得到一个范围在0-1之间的数值。任何大于0.5的数据被分入1类,小于0.5即被归入0类。所以,Logistic回归也可以被看作是一种概率估计。
2.2最优化理论
由上述问题得到,我们现在的问题变成了:最佳回归系数时多少?
z=w0x0+w1x1+w2x2+...+wnxn, z=wTx
向量x是分类器的输入数据,向量w是我们要找的最佳参数(系数),从而使得分类器尽可能地精确,为了寻找最佳参数,需要用到最优化理论的一些知识。
下面首先介绍梯度上升的最优化方法,我们将学习到如何使用该方法求得数据集的最佳参数。接下来,展示如何绘制梯度上升法产生的决策边界图,该图能将梯度上升法的分类效果可视化地呈现出来。最后我们将学习随机梯度上升法,以及如何对其进行修改以获得更好的结果。
2.2.1梯度上升法
梯度上升法的基于的思想是:要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。则函数f(x,y)的梯度由下式表示:
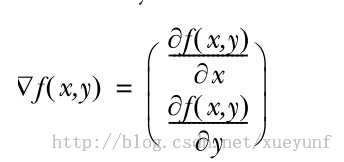
这个梯度意味着要沿x方向移动![]() ,沿y方向移动
,沿y方向移动![]() ,其中,函数f(x,y)必须要在待计算的点上有定义并且可微。具体的函数例子如下图所示:
,其中,函数f(x,y)必须要在待计算的点上有定义并且可微。具体的函数例子如下图所示:
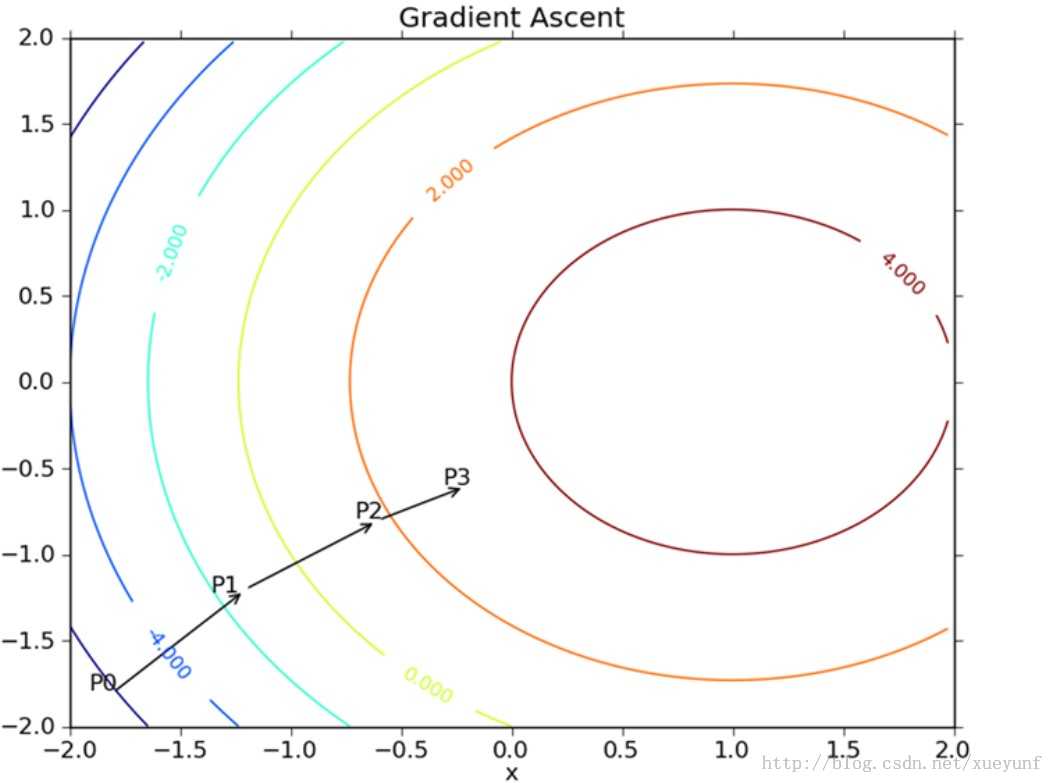
注释:梯度上升算法到达每个点后都会重新估计移动的方向。从P0开始,计算完该点的梯度,函数就根据梯度移动到下一点P1。在P1点,梯度再次被重新计算,并沿新的梯度方向移动到P2。如此循环迭代,直到满足停止条件。迭代过程中,梯度算子总是保证我们能选取到最佳的移动方向。
可以看到,梯度算子总是指向函数值增长最快的方向。这里所说的是移动方向,而未提到移动量的大小。该量值称为歩长,记作
逻辑回归(LogisticRegression)--python实现
标签:
原文地址:http://www.cnblogs.com/chamie/p/4874708.html