标签:
前言
我们之前在测试web service的时候尝试过多种方法:比如使用SoapUI;使用本地代理类编程等。前者不太方便做自动化,后者是从SOAP协议层面进行测试,数据组织不太方便,测试程序相对复杂,并且扩展性不好。
SOAP协议大多使用HTTP绑定,我们发现使用HTTP直接向web service server发送数据包可以做到接口无关,不同的接口对于HTTP请求来说只是包的内容和目标url不同。这样可以将修改测试程序的工作转变为构造数据的工作,一方面在数据量较小的情况下可以减小测试准备和执行时间,另一方面方便测试集成到持续集成环境中。
SOAP层面的Web Service自动化测试
背景介绍
Web Service 是一种新的web应用程序分支,他们是自包含、自描述、模块化的应用,可以发布、定位、通过web调用。Web Service通过WSDL(Web Services Description Language)文件发布。
SOAP是简单对象访问协议,定义了一种跨平台的分布式系统通信协议。SOAP需要绑定到更低层次的传输协议(比如HTTP、RMI、JMS)等。最常用的是HTTP绑定。大多数的Web Service实现是借助SOAP协议,因而通常的Web Service测试方法都是在SOAP协议层面进行测试。在SOAP层面上,每一个请求的数据包格式都是固定的,不同的接口使用不同格式的数据包,因而测试的时候需要针对不同的接口有不同的数据准备和测试执行的方法。
现有的SOAP层面的Web Service自动化测试方法通常是使用工具生成本地代理类,通过编程调用本地代理类实现自动化。这种测试方法数据构造简单,但是测试程序稍复杂,扩展性不强。
数据组织
SOAP层面的自动化测试的数据组织就是准备本地类的参数和返回值。
1. 输入数据
为了更清楚的了解输入数据,这里给出了SoapUI的两张图:
 ?
?
图1 接口一输入
 ?
?
图2 接口二输入
这两幅图显示了SOAP层面的输入数据。AuthHeader是SOAP包的header,是所有接口共有的数据结构;getAccountInfoRequest和getChangedIdRequest是SOAP包的body,各自有不同的字段,type和startTime是真正需要针对每个接口准备的数据。
2. 期望输出
同样这里给出了两张SOAP的图:
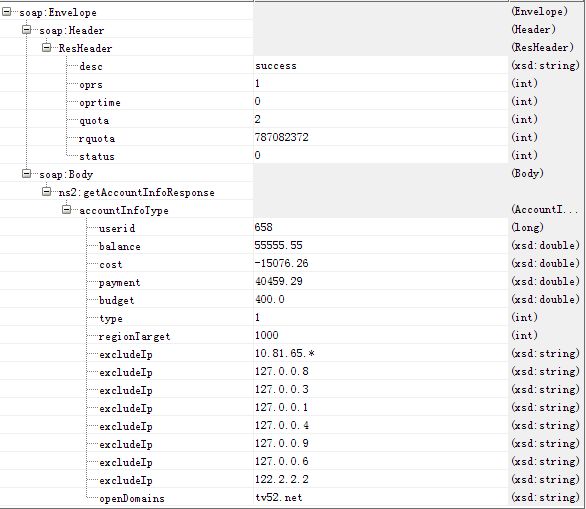 ?
?
图3 接口一输出
 ?
?
图4 接口二输出
输出中的ResHeader也是SOAP包的header,是所有接口的公共输出。getAccountInfoResponse和getChangedIdResponse是SOAP包的body,各自的字段是真正要准备的预期结果数据。
3.分析
从上面给出的例子可以看出,基于SOAP层面的数据组织,需要准备的数据就是本地类的输入和输出字段值,因而数据构造无需考虑SOAP包的格式,比较直观和简单。但是不同接口的字段个数不同,字段名称和类型也不同,所以数据的读取比较麻烦,要针对不同的接口有不同的数据读取程序。
测试程序
测试程序包含本地代理类和调用代理类的程序。本地类的生成通常借助于工具(比如java的Axis2)。调用本地代理类的程序对于每个接口都不同,因为每个接口需要调用不同的函数,在接口比较多的情况下比较麻烦,并且接口有变动都需要修改本地类和测试程序。
结果对比
这里的结果就是本地函数的返回值。在输入和期望输出都读入内存的情况下,结果对比很简单,就是逐个字段比较期望输出和实际输出。
HTTP层面的Web Service自动化测试
HTTP层面的Web Service测试步骤比较简单:准备数据,使用HTTP发送请求数据包,使用HTTP方式接受响应,解析响应并验证结果。
数据组织
HTTP层面的数据是完整的SOAP包(由于大多数SOAP协议基于XML,所以实际上是一个XML包)。
1.输入数据
比如之前的两个接口,对应的输入XML包分别是:
 ?
?
图5 接口一输入XML包
 ?
?
图6 接口二输入XML包
2.期望输出
期望输出同样是两个XML包,只是内容不同,这里就不再举例。
3.分析
通过上面的例子可以看出,HTTP层面的数据就是一个个XML包。对比SOAP层面的数据构造,只知道几个字段值并不能得到一个XML包,需要自己考虑这个XML包的格式。优点就是数据的读取很简单,只需要将整个XML文件的内容读入内存即可。并且很方便构造错误格式的输入。
测试程序
基于HTTP层面的测试程序很简单:以输入的SOAP包为body构造HTTP请求,发送给Web Service Server;接收响应,读取响应的HTTP包的body(就是一个SOAP包)。从这个过程可以看出,所有接口的测试程序都一样。因而新增加接口或者原有接口发生变化都不会影响测试程序。
结果对比
在HTTP层面上,输入和输出都是一个XML包。因而结果对比可以将输入和输出XML包读入到两个字符串中,进行字符串对比。
改进思路
根据上文的分析,HTTP层面的Web Service测试的优势是数据格式灵活,易于读取,测试程序扩展性强,可以适用于所有的接口。但是缺点也很明显:数据构造麻烦,还容易格式出错;结果对比比较机械,无法选择性的对比某些字段(有时候返回结果中包含有时间相关的量,这个量在每次测试的时候返回值都是不一样的,因而在结果对比的时候需要忽略这些字段)。针对这两个缺点我做了相应的改进:
改进数据构造
数据构造的难点在于无法从几个字段构造出符合格式的XML包。
首先我们分析输入数据。再来看之前给出的两个接口的输入:
 ?
?
图7 接口一输入分析
 ?
?
图8 接口二输入分析
可以看出这两个XML包有相同的部分,就是在图中用红色框起来的部分。这部分就是SOAP包的header。一个标准的SOAP包具有这样的格式:
 ?
?
图9 SOAP包格式分析
输入Header部分通常包含用户认证的信息,不同接口的Header格式都相同;Body保存的是真正的数据,各个接口不同。通常不同的接口使用的Header只有少量的几个(通常只是用一个或者少量几个用户做测试),因此我们可以把Header部分的构造提取出来。以dr-api为例,输入的Header主要有username、password和token三个字段(还有一个target字段是选填的),那么我们只需要准备几组username/password/token即可。
输入Body由于是接口相关的,没有统一的方法构造。但是我们可以结合SoapUI工具手动构造,这样比直接写XML包更方便。参考图1,是SoapUI界面的“Form”标签内容。在这个标签下输入Body里需要填写的字段值,然后选择“XML”标签,SoapUI会显示出对应的发送XML包。从中拷贝出Body的内容保存到XXX.input.xml里即可。
输出Header通常包含接口无关的信息,比如处理时间,操作数,错误代码等等(至少从百度推广API和google adwords API来看都是如此)。那么我们也可以将输出Header提取出来,在准备数据的时候只需要给出几个字段即可。由于不同接口的这几个字段的名称和类型都一样,所以很方便程序读取。
准备输出Body也可以借助于SoapUI。但是和输入Body的准备不同,后者只需要有wsdl文件即可构造,输出Body需要Web Service已经提供,使用SoapUI发送一次请求得到返回,这样才能得到输出Body。因而实际中输出Body的准备通常直接用手动的方式构造,不使用SoapUI。
改进结果对比
Web Service的测试中有相当一部分是测试错误代码(以百度推广API V2版本为例,现在一共有约300个错误代码)。这样的测试不需要关注返回包的Body,只需要关注返回包Header中的错误代码,那么我们不需要专门构造预期输出的XML包,只需要提供一个错误代码即可。类似的,如果我们只关注返回包Header里的信息,那么就省去了构造预期输出XML包的过程,结果对比也很简单。
如果测试关注于业务数据,也就是返回包的Body部分,除了字符串对比之外暂时还没有更好更通用的解决方法。
改进总结
改进的结果就是每个case的数据包含三个文件:input.xml、output.xml和一个配置文件properties。Input.xml包含了输入包的Body,output.xml包含了输出包的Body,配置文件则配置了输入输出的header,还有这个case对应的url等信息。
整体思路
总体思路如下:读取所有case的数据,生成用例列表(包含用例数据和调用的接口);对每一个用例,使用http发送数据包,按照XML的解析方法解析返回SOAP包,进行结果验证;使用ficus以用例列表为输入进行数据驱动测试。如下图所示:
 ?
?
图10 测试整体思路
设计与实现
数据组织
数据组织的主要目的有两点:一是做到自描述,通过数据可以得到输入和期望输出,还有请求的url;二是减少冗余数据,比如将soap的header信息提取出来。为了达到这两个目的,我们使用了一个配置文件和一个数据文件夹。配置文件主要存放元数据和公用的数据,数据文件夹存放真正的分散的数据。配置文件的内容如下:
 ?
?
图11 全局配置文件
配置文件的内容主要分为五个部分。A、D、E部分保存的是case无关的元数据,B和C保存的是通用的header数据。
A部分的数据有:整个web service的url前缀(图中的“drapi.serviceUrl”),公用的soap header代号(图中的“drapi.headersGroup”),所有service的代号(图中的“drapi.servicesGroup”)。
B和C部分是两个公用的header。Normal和editor是他们的代号,在A中给出。Dr-api用到的header信息主要有username/password/token/target,都在这里给出。这些header会被每个case引用。
D和E部分是两个service。它们的代号在A中给出。每个service有三个字段:name表示service的名称;url表示service的url后缀。
数据文件夹里保存的是每个case的数据。数据文件夹可以再进行分层:每个子目录的名字就是上面提到的service的名字,那么该子目录下所有case访问的url都是这个service的url。每个case有XXX.input.xml、XXX.output.xml和XXX.properties三个文件表示,XXX表示case的名称(为了应用到ficus中,XXX最好不带空格,否则会被ficus分成数组)。
ficus数据驱动
数据驱动使用ficus的data_driven关键字。关于这个关键字可以参考FICUS_DataDriven。 这个关键字需要两个主要的输入:csv文件,执行单个case的关键字。Csv文件的每一行都表示一个case,data_driven会针对csv文件的每一行循环调用执行单个case的关键字。
我们需要对此编写两个关键字。第一个是读取配置文件和数据文件夹生成csv文件。这个关键字首先会读取公共的配置文件,得到service列表和输入header列表;然后创建一个csv文件,包含这几列:url,使用的Header名称,case名称,XXX.input.xml路径,XXX.output.xml路径和properties中的字段。读取数据文件夹的每个数据文件,根据XXX.input.xml/XXX.output.xml/XXX.properties的组合来添加case到csv文件中。
第二个关键字是用来执行单个case。输入就是csv文件的一行。首先根据使用的Header和XXX.input.xml拼装成输入的XML包,使用HTTP方式向Web Service Server发送请求,接收HTTP相应,解析出Header和Body,将Header中个字段和XXX.properties中的个字段做对比,将Body和XXX.output.xml做对比。
ficus调用java关键字
我们写关键字使用的是Java,这里简单提一下如何用ficus调用java关键字(感谢朱雷同学的帮助)。在最新版的ficus程序里,有一个Java目录,有一个ficus-java-stub.bat文件。将自己写的java关键字打成jar包,放到这个目录,然后启动这个文件就可以启动ficus的Java桩。在写case的时候,首先要添加library,为了使用Java桩,需要添加FicusProxy.JavaProxy | XXX | YYY | localhost | 2345。XXX和YYY都是java关键字所在的public类的类名,这些类的public方法名称都是ficus关键字。
它的原理是:FicusProxy.JavaProxy是一个python关键字,当ficus遇到一个关键字的时候,会通过JavaProxy来查询。JavaProxy会通过socket发送请求到Java桩。Java桩加载了java关键字所在的jar包,因而可以通过反射找到以关键字为名字的方法,从而实现调用。
提示一点,如果自定义的java关键字(都是java方法)所在的类比较多,那么最好把FicusProxy.py的BaseProxy的_receive函数的length默认值改大一点儿,这个值表示ficus和Java桩通信每次发送的数据长度。如果太小,发送的数据会被截断,包含关键字名称和参数那部分会被截断,就会出错。
总结
以上便是我们在HTTP层面进行Web Service测试的总结。这种方法由于需要手动构造输入和输出SOAP包的body,因而在数据量较小并且不关注输出包body的场景使用起来很方便。由于使用的数据驱动,也很方便应对接口的变动。
后续考虑迁移到eFicus中,实现case的管理和执行一体化。
web自动化测试之百度经验-HTTP层面的Web Service自动化测试
标签:
原文地址:http://my.oschina.net/u/224865/blog/516752