标签:
【LevelDB Log文件】
log文件在LevelDb中的主要作用是系统故障恢复时,能够保证不会丢失数据。因为在将记录写入内存的Memtable之前,会先写入Log文件,这样即使系统发生故障,Memtable中的数据没有来得及Dump到磁盘的SSTable文件,LevelDB也可以根据log文件恢复内存的Memtable数据结构内容,不会造成系统丢失数据,在这点上LevelDb和Bigtable是一致的。
LevelDb对于一个log文件,会把它切割成以32K为单位的物理Block,每次读取的单位以一个Block作为基本读取单位,下图展示的log文件由3个Block构成,所以从物理布局来讲,一个log文件就是由连续的32K大小Block构成的。
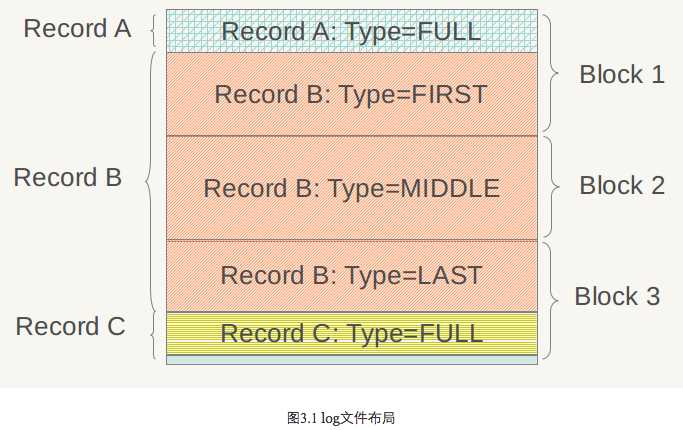
在应用的视野里是看不到这些Block的,应用看到的是一系列的Key:Value对,在LevelDb内部,会将一个Key:Value对看做一条记录的数据,另外在这个数据前增加一个记录头,用来记载一些管理信息,以方便内部处理,图3.2显示了一个记录在LevelDb内部是如何表示的。
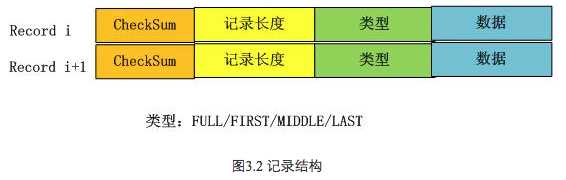
记录头包含三个字段,ChechSum是对“类型”和“数据”字段的校验码,为了避免处理不完整或者是被破坏的数据,当LevelDb读取记录数据时候会对数据进行校验,如果发现和存储的CheckSum相同,说明数据完整无破坏,可以继续后续流程。“记录长度”记载了数据的大小,“数据”则是上面讲的Key:Value数值对,“类型”字段则指出了每条记录的逻辑结构和log文件物理分块结构之间的关系,具体而言,主要有以下四种类型:FULL/FIRST/MIDDLE/LAST。
如果记录类型是FULL,代表了当前记录内容完整地存储在一个物理Block里,没有被不同的物理Block切割开;如果记录被相邻的物理Block切割开,则类型会是其他三种类型中的一种。我们以图3.1所示的例子来具体说明。
假设目前存在三条记录,Record A,Record B和Record C,其中Record A大小为10K,Record B 大小为80K,Record C大小为12K,那么其在log文件中的逻辑布局会如图3.1所示。Record A是图中蓝色区域所示,因为大小为10K<32K,能够放在一个物理Block中,所以其类型为FULL;Record B 大小为80K,而Block 1因为放入了Record A,所以还剩下22K,不足以放下Record B,所以在Block 1的剩余部分放入Record B的开头一部分,类型标识为FIRST,代表了是一个记录的起始部分;Record B还有58K没有存储,这些只能依次放在后续的物理Block里面,因为Block 2大小只有32K,仍然放不下Record B的剩余部分,所以Block 2全部用来放Record B,且标识类型为MIDDLE,意思是这是Record B中间一段数据;Record B剩下的部分可以完全放在Block 3中,类型标识为LAST,代表了这是Record B的末尾数据;图中黄色的Record C因为大小为12K,Block 3剩下的空间足以全部放下它,所以其类型标识为FULL。
从这个小例子可以看出逻辑记录和物理Block之间的关系,LevelDb一次物理读取为一个Block,然后根据类型情况拼接出逻辑记录,供后续流程处理。
参考:http://www.cnblogs.com/haippy/archive/2011/12/04/2276064.html
标签:
原文地址:http://www.cnblogs.com/tekkaman/p/4877032.html