标签:
机器学习中很重要的一个内容就是分类(classification).即根据已有的数据构造出一个模型,通过该模型可以给每个数据标明其所属的种类。通常所见的种类的集合包括{yes,no},{good,bad}等等。需要指出分类的结果集合必须是离散的。
决策树是一种简单且广泛使用的分类器。决策树的每个叶子节点表示对应的类别。每个非叶子节点表示待分类的属性。如何构造决策树?这里看了ID3和C4.5,所以先写这个两个方法。后面如果又看到其他的决策树生成算法再整理归纳。
ID3和C4.5其实差不多。准确的讲,C4.5是在ID3的基础上做了一点儿改进,使得生成较小的决策树。在学习C4.5之前必须对ID3算法做了解,推荐一篇博文[1]http://www.cnblogs.com/lufangtao/archive/2013/05/30/3103588.html。看完了这篇博文讲的再来看C4.5就容易了。在这儿呢我只是单纯的从例子的角度出发,说明C4.5到底是如何运算的。感觉机器学习或者是数据挖掘这些算法都没有特别特别深奥的理论,很多方法借助例子更容易理解。
C4.5相较于ID3引进了信息增益率的概念。ID3是选择信息增益最大的属性做为根节点,但这会导致很容易选择取值较多的属性做为根节点。通俗点解释这个现象产生的原因,如果某个属性下面有多个取值,而每个取值的结构属性都不一样(解释一下结构属性就是下例中的PlayTeniss,yes or no),那每个取值的信息熵就为0,因此信息增益就等于信息熵,此时肯定是这个属性对应的信息增益最大,因而他会被选为根节点。C4.5则不同,C4.5引进了信息增益率的概念,并且以此作为划分依据。这样就会弱化属性取值个数在根节点的选择时的影响。
信息增益率的计算公式如下:
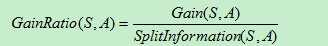
其中SplitInformation(S,A)称之为分裂因子,计算公式为
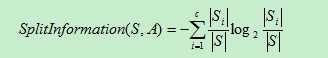
接着博客[1]中的例子看看C4.5是如何运算的。
先把例子粘过来
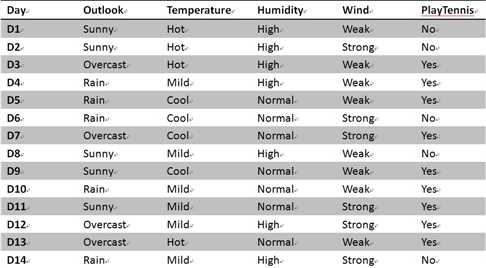
A=outlook,Gain(S,A) = 0.246.
该属性有3个取值{sunny,rain,overcast},样本中的个数分别是{5,5,4}。则SplitInformation(S,A) = -5/14*log2(5/14)-5/14*log2(5/14)-4/14*log2(4/14)=1.577
则GainRatio(S,A) = 0.246/1.577 = 0.156.
A=temperature,Gain(S,A)=0.029.
该属性有3个取值{hot,coo,mild},其中的样本个数分别为{4,4,6}.则SplitInformation(S,A) = -4/14*log2(5/14)-4/14*log2(5/14)-6/14*log2(4/14)=1.557
则GainRatio(S,A) = 0.029/1.557=0.0186.
同理可以计算出A=humidity和A=wind是对应的信息增益率分别为0.155,0.0487.
选取信息增益率最大的属性做为根节点,故应该选取A=OUTLOOK。接下来递归的调用该方法,得到最终的决策树。只不过在本例中ID3和C4.5得到的决策树都是一样的。
标签:
原文地址:http://www.cnblogs.com/bhqmmachinelearning/p/4872432.html