标签:
最近做数据同步,需要从PostgreSql获取数据,发现一旦数据比较多,那么读取的速度非常慢,并且内存占用特别多&GC不掉。
为了方便讲解,下面写了事例代码,从b2c_order获取数据,这个数据表6G左右。
package com.synchro;
import java.sql.*;
/**
* Created by qiu.li on 2015/10/16.
*/
public class Test {
public static void main(String[] args) {
Connection conn = null;
try {
Class.forName("org.postgresql.Driver");
conn = DriverManager.getConnection("jdbc:postgresql://***.qunar.com:5432/database", "username", "password");
String sql = "select * from mirror.b2c_order";
PreparedStatement ps = conn.prepareStatement(sql);
ps.setMaxRows(1000);
ResultSet rs = ps.executeQuery();
int i = 0;
while (rs.next()) {
i++;
if (i % 100 == 0) {
System.out.println(i);
}
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
在Idea执行代码,发现卡死,并且占用大量的内存
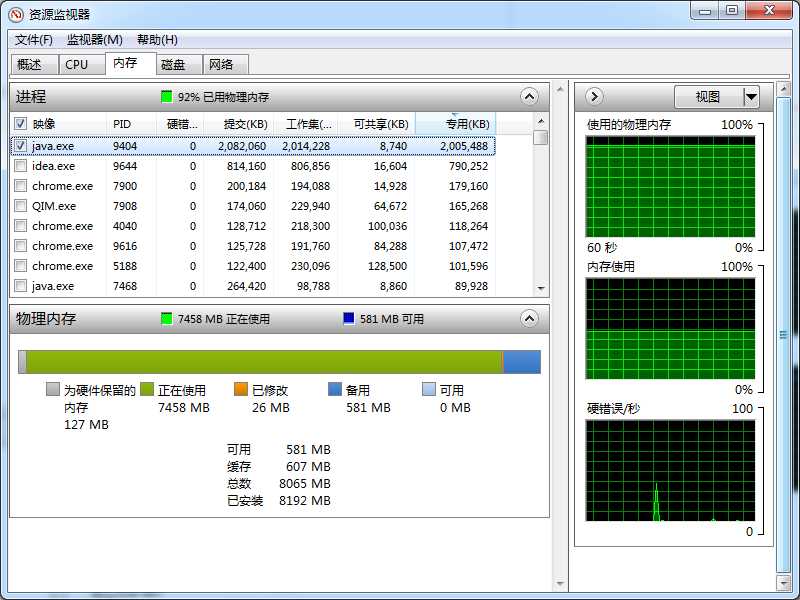
然后我决定开始逐步调试,跟踪代码:
第一步、我发现是在执行executeQuery方法的时候卡住的
第二步、是在执行AbstractJdbc2Statement.executeWithFlags方法卡住的
第三步、继续跟踪,并在网络上查看可能引起的原因是和设置fetchSize参数相关,所以我设置了fetchSize,奇葩的是没有生效
第四步、sendQuery,sendOneQuery方法,在这里发现了问题,好在代码不太多,我就都贴出来了:
boolean usePortal = (flags & 8) != 0 && !noResults && !noMeta && fetchSize > 0 && !describeOnly;
boolean oneShot = (flags & 1) != 0 && !usePortal;
int rows;
if(noResults) {
rows = 1;
} else if(!usePortal) {
rows = maxRows;
} else if(maxRows != 0 && fetchSize > maxRows) {
rows = maxRows;
} else {
rows = fetchSize;
}
可见是usePortal是true,那么fetchSize才会生效。
boolean usePortal = (flags & 8) != 0 && !noResults && !noMeta && fetchSize > 0 && !describeOnly;
那么咱们逐一看一下这些条件:
那么,试下的唯一的可能导致usePortal为true的原因就是 flags & 8这个值是true。。(我想说这种写法很别致,tmd,设置flags的时候肯定是flags=flag|8,后来发现新的驱动修改了这种写法)
继续往上翻,看看什么时候才会执行flags = flags | 8 这个代码了,因为只有这个代码被执行过,才会导致上面这个条件为true
if(this.fetchSize > 0 && !this.wantsScrollableResultSet() && !this.connection.getAutoCommit() && !this.wantsHoldableResultSet()) {
flags |= 8;
}
其中:wantsHoldableResultSet()代码直接返回的false,所以,不考虑这个。
那么,wantsScrollableResultSet()返回false,并且connection.getAutoCommit()返回false,才会导致fetchSize生效。wantsScrollableResultSet()这个方法的代码为:
protected boolean wantsScrollableResultSet() {
return resultsettype != 1003; //老代码,看到这里我真想死,1003是啥?好在偶然的机会看见了新的Postgresql驱动,使用ResultSet.TYPE_FORWARD_ONLY表示1003
}
至此,问题终于被定位:
1、如果connection不是自动提交事务的,那么,fetchSize将生效(非默认)
2、如果statement是TYPE_FORWARD_ONLY的,那么,fetchSize也将生效(默认)
结论
如果想fetchSize生效,必须保证connection是autocommit = false的,并且,statement为1003(forward_only)的:
conn.setAutoCommit(false);
final Statement statement = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY, ResultSet.FETCH_FORWARD);
另外,不带参数的conn.createStatement(),其默认就是TYPE_FORWARD_ONLY。所以,一般情况下,如果想fetchsize生效,只须设置autocommit为flase,也就是需要手工去管理事务。默认的源代码如下:
public Statement createStatement() throws SQLException { return this.createStatement(1003, 1007); //有兴趣的同学可以继续跟踪看看,1003就是resultsettype }
那么修改代码如下:
package com.synchro;
import java.sql.*;
/**
* Created by qiu.li on 2015/10/16.
*/
public class Test {
public static void main(String[] args) {
Connection conn = null;
try {
Class.forName("org.postgresql.Driver");
conn = DriverManager.getConnection("jdbc:postgresql://***.qunar.com:5432/datasource", "username", "password");
conn.setAutoCommit(false); //并不是所有数据库都适用,比如hive就不支持,orcle不需要
String sql = "select * from mirror.b2c_order";
PreparedStatement ps = conn.prepareStatement(sql);
ps.setFetchSize(1000); //每次获取1万条记录
//ps.setMaxRows(1000);
ResultSet rs = ps.executeQuery();
int i = 0;
while (rs.next()) {
i++;
if (i % 100 == 0) {
System.out.println(i);
}
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
这次再一次执行,发现根本不卡。
感悟:类似这种问题都的慢慢跟踪代码,更重要的是身边需要有同事可以相互讨论,形成氛围,因为这个过程十分乏味,自己很难坚持下来。
https://jdbc.postgresql.org/documentation/head/query.html
http://m.blog.csdn.net/blog/itjin45/42004447#
Jdbc如何从PostgreSql读取海量数据?PostgreSql源代码分析纪录
标签:
原文地址:http://www.cnblogs.com/liqiu/p/4886581.html