标签:
Basic idea
1.一个文档(document)只有一个主题(topic)
2.主题指的是这个主题下文档中词语是如何出现的
3.在某一主题下文档中经常出现的词语,这个词语在这个主题中也是经常出现的。
4.在某一主题下文档中不经常出现的词语,这个词语在这个主题中也是不经常出现的。
5.由此,概率计算方法可以近似为:
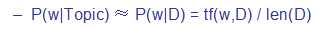
Ranking
当给定查询q时,怎么根据统计语言模型进行排序呢?有三种排序方法,分别是:1.Query-likelihood 2.Document-likelihood
3.Divergence (差异) of query and document models
查询q = (q1,q2,...,qk),MD表示在统计语言模型下的文档。
1.Query-likelihood
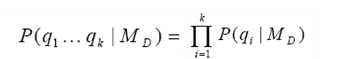
Example:
Q = “人民 创造” D1 = “在 漫长 的 历史 进程 中 中国 人民 辛勤 劳动 不懈 探索 勇于 创造 中国 人民 热爱 和平 ”
P(“人民”|MD1)=2/18, P(“创造”|MD1)=1/18
P(Q|MD1) = P(“人民”|MD1)*P(“创造”|MD1) = 2/18 * 1/18
2.Document-likelihood
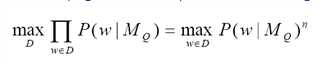
存在的问题:a.文档的长度相差很大,很难比较 b.由于文档中出现的词很多没有出现在查询中,将会出现零频问题 c.将会出现无意义的作弊网页
解决这些问题的方法:

3.Divergence (差异) of query and document models
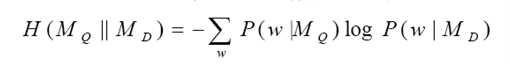
上式中w指的是同时出现在q和d中的词语,它的意义是用Q对D进行编码,所需要的位数
零频问题
解决方法:1.拉普拉斯平滑:把每个词的词频都加1。
2.Lindstone correction:把每个词都加一个很小的值ε。
3.Absolute Discounting:把词频不等于0的词减去一个很小的值ε,再把这些值平均分配到词频为1的词上去。
标签:
原文地址:http://www.cnblogs.com/leeshum/p/4889400.html