标签:
网址:http://www.cnblogs.com/wilber2013/p/4638967.html
Python中的函数也是一种对象,而且函数还是一等公民。函数能作为参数,也能作为返回值,这使得Python中的函数变得很灵活。想想前面两篇中介绍的通过内嵌函数实现的装饰器和闭包。
下面就介绍一下Python函数相关的一些内容。
可变长度参数
在编程的过程中,可能会遇到函数参数个数不固定的情况,这时就需要使用可变长度的函数参数。在Python函数定义中,使用*和**符号分别指定元组(非关键字)和字典(关键字)作为参数。
非关键字变长参数(元组)
当函数被调用的时候,所有的参数都将值赋给了在函数声明中对应的局部变量,剩下的非关键字参数按照顺序添加到一个元组中便于访问。
可变长元组参数必须在位置和默认参数之后,所以使用可变长元组参数的函数形式一般如下(中括号表示可选参数),可变长元组参数前有一个”*”符号:
deffuncName([fromal_args,] *tuple_grp_nonkw_args): pass
看一个例子:
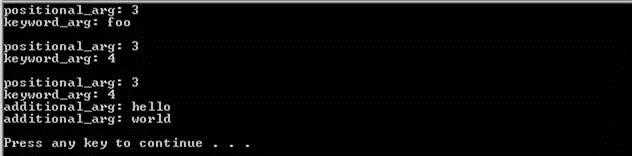
defargFunc(positional_arg,keyword_arg="foo", *tuple_grp_nonkw_args): print"positional_arg:",positional_arg print"keyword_arg:",keyword_arg forarg intuple_grp_nonkw_args: print"additional_arg:",arg argFunc(3) print argFunc(3,4) print argFunc(3,4,"hello","world")
代码的输出为:
关键字变长参数(字典)
除了上面的方式,Python还可以支持关键字变长参数,额外的关键字参数被放入了一个字典进行使用。
可变长字典参数必须是函数定义中的最后一个参数,所以使用可变长字典参数的函数形式一般如下(中括号表示可选参数),可变长字典参数前有一个”**”符号:
deffuncName([fromal_args,][*tuple_grp_nonkw_args,] **dict_grp_kw_args): pass
看一个例子:
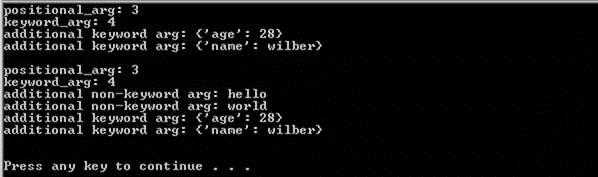
defargFunc(positional_arg,keyword_arg="foo", *tuple_grp_nonkw_args, **dict_grp_kw_args): print"positional_arg:",positional_arg print"keyword_arg:",keyword_arg forarg intuple_grp_nonkw_args: print"additional non-keyword arg:",arg forargKey indict_grp_kw_args.keys(): print"additional keyword arg: {‘%s‘: %s}" %(argKey,dict_grp_kw_args[argKey]) argFunc(3,4,name="wilber",age=28) print argFunc(3,4,"hello","world",name="wilber",age=28) print
代码输出为:
函数调用的完整形式为:
func( positional_args, keyword_args, *tuple_grp_nonkw_args, **dict_grp_kw_args )
在使用的过程中,所有参数都是可选的,但应当注意的是:上面四种参数的位置是不可调换的。
匿名函数(lambda)
Python允许使用lambda关键字创建匿名函数,通过lambda关键字,可以快速编写简单函数。
使用lambda关键字的形式为:
lambda[arg1[,arg2,...argN]]: expression
对于不经常被调用的简单函数,建议直接使用lambda表达式,方便简洁:
addNum = lambdax,y: x+y printaddNum print"3 + 4 = ",addNum(3,4)
几个内建函数
Python可以很好的支持面向对象编程,但是通过Python中以下几个内建函数和lambda表达式,也可以体验一下函数式编程。
filter()
filter函数的完整形式为filter(func, seq):调用一个布尔类型的函数func来遍历每一个seq中的元素,返回一个使func返回值为ture的元素的序列。
例如获取100以内的奇数:
printfilter(lambdan: (n%2) == 1,range(100))
当然对于上面的例子,也可以使用列表解析实现:
print[iforiinrange(100)ifi%2 == 1]
map()
map函数的完整形式为map(func, seq1 [, seq2...]):将函数func作用于给定序列的每一个元素,并用一个列表来提供返回值;如果func为None,作用同zip()。
是不是被上面的描述搞晕了,还是看例子吧:
# map的func为None printmap(None,[4,5,6]) printmap(None,[1,2,3],[4,5,6]) # map 针对一个序列 printmap(lambdax: x*2,[4,5,6]) # map 针对多个序列 printmap(lambdax,y: x + y,[1,2,3],[4,5,6])
代码输出为:

reduce()
reduce函数的完整形式为reduce(func, seq [, init]):func是一个二元函数;reduce对seq中的每一个元素进行迭代,每次迭代将上一次的迭代结果(第一次时使用init,如没有init,则使用seq的第一个元素)与下一个元素执行func函数。
看一个例子,通过reduce函数进行求和操作:
printreduce(lambdax,y: x + y,range(10))
printreduce(lambdax,y: x + y,range(10),100)
输出为:

根据上面的介绍,我们自己也可以实现一个reduce函数:
def xreduce(bin_func,seq,init=None): Iseq = list(seq) if init is None: res = Iseq.pop(0) else: res = init for obj inIseq: res = bin_func(res,obj) return res
标签:
原文地址:http://www.cnblogs.com/abapscript/p/4889772.html