标签:
一切从示例程序开始:
示例程序
Hadoop2.7 提供的示例程序WordCount.java
package org.apache.hadoop.examples; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { //继承泛型类Mapper public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ //定义hadoop数据类型IntWritable实例one,并且赋值为1 private final static IntWritable one = new IntWritable(1); //定义hadoop数据类型Text实例word private Text word = new Text(); //实现map函数 public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { //Java的字符串分解类,默认分隔符“空格”、“制表符(‘\t’)”、“换行符(‘\n’)”、“回车符(‘\r’)” StringTokenizer itr = new StringTokenizer(value.toString()); //循环条件表示返回是否还有分隔符。 while (itr.hasMoreTokens()) { /* nextToken():返回从当前位置到下一个分隔符的字符串 word.set()Java数据类型与hadoop数据类型转换 */ word.set(itr.nextToken()); //hadoop全局类context输出函数write; context.write(word, one); } } } //继承泛型类Reducer public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { //实例化IntWritable private IntWritable result = new IntWritable(); //实现reduce public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; //循环values,并记录单词个数 for (IntWritable val : values) { sum += val.get(); } //Java数据类型sum,转换为hadoop数据类型result result.set(sum); //输出结果到hdfs context.write(key, result); } } public static void main(String[] args) throws Exception { //实例化Configuration Configuration conf = new Configuration(); /* GenericOptionsParser是hadoop框架中解析命令行参数的基本类。 getRemainingArgs();返回数组【一组路径】 */ /* 函数实现 public String[] getRemainingArgs() { return (commandLine == null) ? new String[]{} : commandLine.getArgs(); }*/ String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); //如果只有一个路径,则输出需要有输入路径和输出路径 if (otherArgs.length < 2) { System.err.println("Usage: wordcount <in> [<in>...] <out>"); System.exit(2); } //实例化job Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); /* 指定CombinerClass类 这里很多人对CombinerClass不理解 */ job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); //rduce输出Key的类型,是Text job.setOutputKeyClass(Text.class); // rduce输出Value的类型 job.setOutputValueClass(IntWritable.class); //添加输入路径 for (int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } //添加输出路径 FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); //提交job System.exit(job.waitForCompletion(true) ? 0 : 1); } }
1.Mapper
将输入的键值对映射到一组中间的键值对。
映射将独立的任务的输入记录转换成中间的记录。装好的中间记录不需要和输入记录保持同一种类型。一个给定的输入对可以映射成0个或者多个输出对。
Hadoop Map-Reduce框架为每个job产生的输入格式(InputFormat)的InputSplit产生一个映射task。Mapper实现类通过JobConfigurable#configure(JobConf)获取job的JobConf,并初始化自己。类似的,它们使用Closeable#close()方法消耗初始化。
然后,框架为该任务的InputSplit中的每个键值对调用map(Object, Object, OutputCollector, Reporter)方法。
所有关联到给定输出的中间值随后由框架分组,并传到Reducer来确定最终的输出。用户可通过指定一个比较器Compator来控制分组,Compator的指定通过JobConf#setOutputKeyComparatorClass(Class)完成。
分组的Mapper输出每个Reducer一个分区。用户可以通过实现自定义的分区来控制哪些键(和记录)到哪个Reducer。
用户可以选择指定一个Combiner,通过JobConf#setCombinerClass(Class),来执行本地中间输出的聚合,它可以帮助减少数据从Mapper到Reducer数据转换的数量。
中间、分组的输出保存在SequeceFile文件中,应用可以指定中间输出是否和怎么样压缩,压缩算法可以通过JobConf来设置CompressionCodec。
若job没有reducer,Mapper的输出直接写到FileSystem,而不会根据键分组。
示例:
public class MyMapper<K extends WritableComparable, V extends Writable>
extends MapReduceBase implements Mapper<K, V, K, V> {
static enum MyCounters { NUM_RECORDS }
private String mapTaskId;
private String inputFile;
private int noRecords = 0;
public void configure(JobConf job) {
mapTaskId = job.get(JobContext.TASK_ATTEMPT_ID);
inputFile = job.get(JobContext.MAP_INPUT_FILE);
}
public void map(K key, V val,
OutputCollector<K, V> output, Reporter reporter)
throws IOException {
// Process the <key, value> pair (assume this takes a while)
// ...
// ...
// Let the framework know that we are alive, and kicking!
// reporter.progress();
// Process some more
// ...
// ...
// Increment the no. of <key, value> pairs processed
++noRecords;
// Increment counters
reporter.incrCounter(NUM_RECORDS, 1);
// Every 100 records update application-level status
if ((noRecords%100) == 0) {
reporter.setStatus(mapTaskId + " processed " + noRecords +
" from input-file: " + inputFile);
}
// Output the result
output.collect(key, val);
}
}
上述应用自定义一个MapRunnable来对map处理过程进行更多的控制:如多线程Mapper等等。
或者示例:
public class TokenCounterMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
应用可以重新(org.apache.hadoop.mapreduce.Mapper.Context)的run方法来来对映射处理进行更精确的控制,例如多线程的Mapper等等。
Mapper的方法:
void map(K1 key, V1 value, OutputCollector<K2, V2> output, Reporter reporter)
throws IOException;
该方法将一个单独的键值对输入映射成一个中间键值对。
输出键值对不需要和输入键值对的类型保持一致,一个给定的数据键值对可以映射到0个或者多个输出键值对。输出键值对可以通过OutputCollector#collect(Object,Object)获得的。
应用可以使用Reporter提供处理报告或者仅仅是标示它们的存活。在一个应用需要相当多的时间来处理单独的键值对的场景中,Report就非常重要了,因为框架可能认为task已经超期,并杀死那个task。避免这种情况的办法是设置mapreduce.task.timeout到一个足够大的值(或者设置为0表示永远不会超时)。
mapper的层次结构:
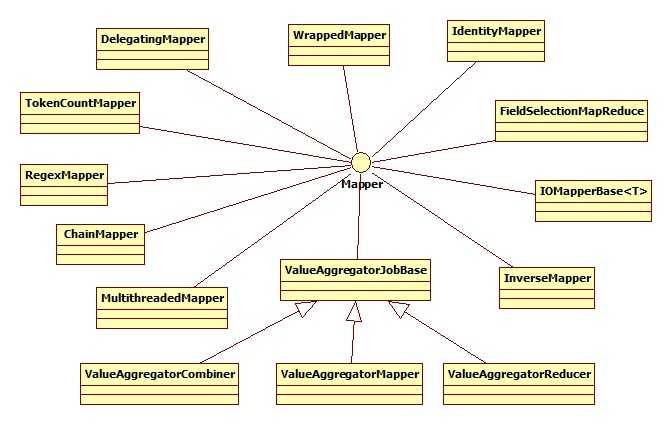
2.Reducer
将一组共享一个键的中间值减少到一小组值。
用户通过JobConf#setNumReducerTask(int)方法来设置job的Reducer的数目。Reducer的实现类通过JobConfigurable#configure(JobConf)方法来获取job,并初始化它们。类似的,可通过Closeable#close()方法来消耗初始化。
Reducer有是3个主要阶段:
第一阶段:洗牌,Reducer的输入是Mapper的分组输出。在这个阶段,每个Reducer通过http获取所有Mapper的相关分区的输出。
第二阶段:排序,在这个阶段,框架根据键(因不同的Mapper可能产生相同的Key)将Reducer进行分组。洗牌和排序阶段是同步发生的,例如:当取出输出时,将合并它们。
二次排序,若分组中间值等价的键规则和reduce之前键分组的规则不同时,那么其中之一可以通过JobConf#setOutputValueGroupingComparator(Class)来指定一个Comparator。
JobConf#setOutputKeyComparatorClass(Class)可以用来控制中间键分组,可以用在模拟二次排序的值连接中。
示例:若你想找出重复的web网页,并将他们全部标记为“最佳”网址的示例。你可以这样创建job:
Map输入的键:url
Map输入的值:document
Map输出的键:document checksum,url pagerank
Map输出的值:url
分区:通过checksum
输出键比较器:通过checksum,然后是pagerank降序。
输出值分组比较器:通过checksum
Reduce
在此阶段,为在分组书中的每个<key,value数组>对调用reduce(Object, Iterator, OutputCollector, Reporter)方法。
reduce task的输出通常写到写到文件系统中,方法是:OutputCollector#collect(Object, Object)。
Reducer的输出结果没有重新排序。
示例:
public class MyReducer<K extends WritableComparable, V extends Writable> extends MapReduceBase implements Reducer<K, V, K, V> { static enum MyCounters { NUM_RECORDS } private String reduceTaskId; private int noKeys = 0; public void configure(JobConf job) { reduceTaskId = job.get(JobContext.TASK_ATTEMPT_ID); } public void reduce(K key, Iterator<V> values, OutputCollector<K, V> output, Reporter reporter) throws IOException { // Process int noValues = 0; while (values.hasNext()) { V value = values.next(); // Increment the no. of values for this key ++noValues; // Process the <key, value> pair (assume this takes a while) // ... // ... // Let the framework know that we are alive, and kicking! if ((noValues%10) == 0) { reporter.progress(); } // Process some more // ... // ... // Output the <key, value> output.collect(key, value); } // Increment the no. of <key, list of values> pairs processed ++noKeys; // Increment counters reporter.incrCounter(NUM_RECORDS, 1); // Every 100 keys update application-level status if ((noKeys%100) == 0) { reporter.setStatus(reduceTaskId + " processed " + noKeys); } } }
下图来源:http://x-rip.iteye.com/blog/1541914
3. Job
3.1 上述示例程序最关键的一句:job.waitForCompletion(true)
/** * Submit the job to the cluster and wait for it to finish. * @param verbose print the progress to the user * @return true if the job succeeded * @throws IOException thrown if the communication with the * <code>JobTracker</code> is lost */ public boolean waitForCompletion(boolean verbose ) throws IOException, InterruptedException, ClassNotFoundException { if (state == JobState.DEFINE) { submit(); } if (verbose) { monitorAndPrintJob(); } else { // get the completion poll interval from the client. int completionPollIntervalMillis = Job.getCompletionPollInterval(cluster.getConf()); while (!isComplete()) { try { Thread.sleep(completionPollIntervalMillis); } catch (InterruptedException ie) { } } } return isSuccessful(); }
3.2 提交的过程
/** * Submit the job to the cluster and return immediately. * @throws IOException */ public void submit() throws IOException, InterruptedException, ClassNotFoundException { ensureState(JobState.DEFINE); setUseNewAPI(); connect(); final JobSubmitter submitter = getJobSubmitter(cluster.getFileSystem(), cluster.getClient()); status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() { public JobStatus run() throws IOException, InterruptedException, ClassNotFoundException { return submitter.submitJobInternal(Job.this, cluster); } }); state = JobState.RUNNING; LOG.info("The url to track the job: " + getTrackingURL()); }
连接过程:
private synchronized void connect() throws IOException, InterruptedException, ClassNotFoundException { if (cluster == null) { cluster = ugi.doAs(new PrivilegedExceptionAction<Cluster>() { public Cluster run() throws IOException, InterruptedException, ClassNotFoundException { return new Cluster(getConfiguration()); } }); } }
其中,
ugi定义在JobContextImpl.java中:
/**
* The UserGroupInformation object that has a reference to the current user
*/
protected UserGroupInformation ugi;
Cluster类提供了一个访问map/reduce集群的接口:
public static enum JobTrackerStatus {INITIALIZING, RUNNING}; private ClientProtocolProvider clientProtocolProvider; private ClientProtocol client; private UserGroupInformation ugi; private Configuration conf; private FileSystem fs = null; private Path sysDir = null; private Path stagingAreaDir = null; private Path jobHistoryDir = null;
4. JobSubmitter
/** * Internal method for submitting jobs to the system. * * <p>The job submission process involves: * <ol> * <li> * Checking the input and output specifications of the job. * </li> * <li> * Computing the {@link InputSplit}s for the job. * </li> * <li> * Setup the requisite accounting information for the * {@link DistributedCache} of the job, if necessary. * </li> * <li> * Copying the job‘s jar and configuration to the map-reduce system * directory on the distributed file-system. * </li> * <li> * Submitting the job to the <code>JobTracker</code> and optionally * monitoring it‘s status. * </li> * </ol></p> * @param job the configuration to submit * @param cluster the handle to the Cluster * @throws ClassNotFoundException * @throws InterruptedException * @throws IOException */ JobStatus submitJobInternal(Job job, Cluster cluster) throws ClassNotFoundException, InterruptedException, IOException { //validate the jobs output specs checkSpecs(job); Configuration conf = job.getConfiguration(); addMRFrameworkToDistributedCache(conf); Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); //configure the command line options correctly on the submitting dfs InetAddress ip = InetAddress.getLocalHost(); if (ip != null) { submitHostAddress = ip.getHostAddress(); submitHostName = ip.getHostName(); conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName); conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress); } JobID jobId = submitClient.getNewJobID(); job.setJobID(jobId); Path submitJobDir = new Path(jobStagingArea, jobId.toString()); JobStatus status = null; try { conf.set(MRJobConfig.USER_NAME, UserGroupInformation.getCurrentUser().getShortUserName()); conf.set("hadoop.http.filter.initializers", "org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer"); conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString()); LOG.debug("Configuring job " + jobId + " with " + submitJobDir + " as the submit dir"); // get delegation token for the dir TokenCache.obtainTokensForNamenodes(job.getCredentials(), new Path[] { submitJobDir }, conf); populateTokenCache(conf, job.getCredentials()); // generate a secret to authenticate shuffle transfers if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) { KeyGenerator keyGen; try { int keyLen = CryptoUtils.isShuffleEncrypted(conf) ? conf.getInt(MRJobConfig.MR_ENCRYPTED_INTERMEDIATE_DATA_KEY_SIZE_BITS, MRJobConfig.DEFAULT_MR_ENCRYPTED_INTERMEDIATE_DATA_KEY_SIZE_BITS) : SHUFFLE_KEY_LENGTH; keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM); keyGen.init(keyLen); } catch (NoSuchAlgorithmException e) { throw new IOException("Error generating shuffle secret key", e); } SecretKey shuffleKey = keyGen.generateKey(); TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(), job.getCredentials()); } copyAndConfigureFiles(job, submitJobDir); Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir); // Create the splits for the job LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir)); int maps = writeSplits(job, submitJobDir); conf.setInt(MRJobConfig.NUM_MAPS, maps); LOG.info("number of splits:" + maps); // write "queue admins of the queue to which job is being submitted" // to job file. String queue = conf.get(MRJobConfig.QUEUE_NAME, JobConf.DEFAULT_QUEUE_NAME); AccessControlList acl = submitClient.getQueueAdmins(queue); conf.set(toFullPropertyName(queue, QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString()); // removing jobtoken referrals before copying the jobconf to HDFS // as the tasks don‘t need this setting, actually they may break // because of it if present as the referral will point to a // different job. TokenCache.cleanUpTokenReferral(conf); if (conf.getBoolean( MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED, MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) { // Add HDFS tracking ids ArrayList<String> trackingIds = new ArrayList<String>(); for (Token<? extends TokenIdentifier> t : job.getCredentials().getAllTokens()) { trackingIds.add(t.decodeIdentifier().getTrackingId()); } conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS, trackingIds.toArray(new String[trackingIds.size()])); } // Set reservation info if it exists ReservationId reservationId = job.getReservationId(); if (reservationId != null) { conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString()); } // Write job file to submit dir writeConf(conf, submitJobFile); // // Now, actually submit the job (using the submit name) // printTokens(jobId, job.getCredentials()); status = submitClient.submitJob( jobId, submitJobDir.toString(), job.getCredentials()); if (status != null) { return status; } else { throw new IOException("Could not launch job"); } } finally { if (status == null) { LOG.info("Cleaning up the staging area " + submitJobDir); if (jtFs != null && submitJobDir != null) jtFs.delete(submitJobDir, true); } } }
上面所说,job的提交有如下过程:
1. 检查job的输入/输出规范
2. 计算job的InputSplit
3. 如需要,计算job的DistributedCache所需要的前置计算信息
4. 复制job的jar和配置文件到分布式文件系统的map-reduce系统目录
5. 提交job到JobTracker,还可以监视job的执行状态。
若当前JobClient (0.22 hadoop) 运行在YARN.则job提交任务运行在YARNRunner
Hadoop Yarn 框架原理及运作机制

在运行作业之前,Resource Manager和Node Manager都已经启动,所以在上图中,Resource Manager进程和Node Manager进程不需要启动
5. YARNRunner
@Override public JobStatus submitJob(JobID jobId, String jobSubmitDir, Credentials ts) throws IOException, InterruptedException { addHistoryToken(ts); // Construct necessary information to start the MR AM ApplicationSubmissionContext appContext = createApplicationSubmissionContext(conf, jobSubmitDir, ts); // Submit to ResourceManager try { ApplicationId applicationId = resMgrDelegate.submitApplication(appContext); ApplicationReport appMaster = resMgrDelegate .getApplicationReport(applicationId); String diagnostics = (appMaster == null ? "application report is null" : appMaster.getDiagnostics()); if (appMaster == null || appMaster.getYarnApplicationState() == YarnApplicationState.FAILED || appMaster.getYarnApplicationState() == YarnApplicationState.KILLED) { throw new IOException("Failed to run job : " + diagnostics); } return clientCache.getClient(jobId).getJobStatus(jobId); } catch (YarnException e) { throw new IOException(e); } }
调用YarnClient的submitApplication()方法,其实现如下:
6. YarnClientImpl
@Override public ApplicationId submitApplication(ApplicationSubmissionContext appContext) throws YarnException, IOException { ApplicationId applicationId = appContext.getApplicationId(); if (applicationId == null) { throw new ApplicationIdNotProvidedException( "ApplicationId is not provided in ApplicationSubmissionContext"); } SubmitApplicationRequest request = Records.newRecord(SubmitApplicationRequest.class); request.setApplicationSubmissionContext(appContext); // Automatically add the timeline DT into the CLC // Only when the security and the timeline service are both enabled if (isSecurityEnabled() && timelineServiceEnabled) { addTimelineDelegationToken(appContext.getAMContainerSpec()); } //TODO: YARN-1763:Handle RM failovers during the submitApplication call. rmClient.submitApplication(request); int pollCount = 0; long startTime = System.currentTimeMillis(); EnumSet<YarnApplicationState> waitingStates = EnumSet.of(YarnApplicationState.NEW, YarnApplicationState.NEW_SAVING, YarnApplicationState.SUBMITTED); EnumSet<YarnApplicationState> failToSubmitStates = EnumSet.of(YarnApplicationState.FAILED, YarnApplicationState.KILLED); while (true) { try { ApplicationReport appReport = getApplicationReport(applicationId); YarnApplicationState state = appReport.getYarnApplicationState(); if (!waitingStates.contains(state)) { if(failToSubmitStates.contains(state)) { throw new YarnException("Failed to submit " + applicationId + " to YARN : " + appReport.getDiagnostics()); } LOG.info("Submitted application " + applicationId); break; } long elapsedMillis = System.currentTimeMillis() - startTime; if (enforceAsyncAPITimeout() && elapsedMillis >= asyncApiPollTimeoutMillis) { throw new YarnException("Timed out while waiting for application " + applicationId + " to be submitted successfully"); } // Notify the client through the log every 10 poll, in case the client // is blocked here too long. if (++pollCount % 10 == 0) { LOG.info("Application submission is not finished, " + "submitted application " + applicationId + " is still in " + state); } try { Thread.sleep(submitPollIntervalMillis); } catch (InterruptedException ie) { LOG.error("Interrupted while waiting for application " + applicationId + " to be successfully submitted."); } } catch (ApplicationNotFoundException ex) { // FailOver or RM restart happens before RMStateStore saves // ApplicationState LOG.info("Re-submit application " + applicationId + "with the " + "same ApplicationSubmissionContext"); rmClient.submitApplication(request); } } return applicationId; }
7. ClientRMService
ClientRMService是resource manager的客户端接口。这个模块处理从客户端到resource mananger的rpc接口。
@Override public SubmitApplicationResponse submitApplication( SubmitApplicationRequest request) throws YarnException { ApplicationSubmissionContext submissionContext = request .getApplicationSubmissionContext(); ApplicationId applicationId = submissionContext.getApplicationId(); // ApplicationSubmissionContext needs to be validated for safety - only // those fields that are independent of the RM‘s configuration will be // checked here, those that are dependent on RM configuration are validated // in RMAppManager. String user = null; try { // Safety user = UserGroupInformation.getCurrentUser().getShortUserName(); } catch (IOException ie) { LOG.warn("Unable to get the current user.", ie); RMAuditLogger.logFailure(user, AuditConstants.SUBMIT_APP_REQUEST, ie.getMessage(), "ClientRMService", "Exception in submitting application", applicationId); throw RPCUtil.getRemoteException(ie); } // Check whether app has already been put into rmContext, // If it is, simply return the response if (rmContext.getRMApps().get(applicationId) != null) { LOG.info("This is an earlier submitted application: " + applicationId); return SubmitApplicationResponse.newInstance(); } if (submissionContext.getQueue() == null) { submissionContext.setQueue(YarnConfiguration.DEFAULT_QUEUE_NAME); } if (submissionContext.getApplicationName() == null) { submissionContext.setApplicationName( YarnConfiguration.DEFAULT_APPLICATION_NAME); } if (submissionContext.getApplicationType() == null) { submissionContext .setApplicationType(YarnConfiguration.DEFAULT_APPLICATION_TYPE); } else { if (submissionContext.getApplicationType().length() > YarnConfiguration.APPLICATION_TYPE_LENGTH) { submissionContext.setApplicationType(submissionContext .getApplicationType().substring(0, YarnConfiguration.APPLICATION_TYPE_LENGTH)); } } try { // call RMAppManager to submit application directly rmAppManager.submitApplication(submissionContext, System.currentTimeMillis(), user); LOG.info("Application with id " + applicationId.getId() + " submitted by user " + user); RMAuditLogger.logSuccess(user, AuditConstants.SUBMIT_APP_REQUEST, "ClientRMService", applicationId); } catch (YarnException e) { LOG.info("Exception in submitting application with id " + applicationId.getId(), e); RMAuditLogger.logFailure(user, AuditConstants.SUBMIT_APP_REQUEST, e.getMessage(), "ClientRMService", "Exception in submitting application", applicationId); throw e; } SubmitApplicationResponse response = recordFactory .newRecordInstance(SubmitApplicationResponse.class); return response; }
调用RMAppManager来直接提交application
@SuppressWarnings("unchecked")
protected void submitApplication(
ApplicationSubmissionContext submissionContext, long submitTime,
String user) throws YarnException {
ApplicationId applicationId = submissionContext.getApplicationId();
RMAppImpl application =
createAndPopulateNewRMApp(submissionContext, submitTime, user);
ApplicationId appId = submissionContext.getApplicationId();
if (UserGroupInformation.isSecurityEnabled()) {
try {
this.rmContext.getDelegationTokenRenewer().addApplicationAsync(appId,
parseCredentials(submissionContext),
submissionContext.getCancelTokensWhenComplete(),
application.getUser());
} catch (Exception e) {
LOG.warn("Unable to parse credentials.", e);
// Sending APP_REJECTED is fine, since we assume that the
// RMApp is in NEW state and thus we haven‘t yet informed the
// scheduler about the existence of the application
assert application.getState() == RMAppState.NEW;
this.rmContext.getDispatcher().getEventHandler()
.handle(new RMAppRejectedEvent(applicationId, e.getMessage()));
throw RPCUtil.getRemoteException(e);
}
} else {
// Dispatcher is not yet started at this time, so these START events
// enqueued should be guaranteed to be first processed when dispatcher
// gets started.
this.rmContext.getDispatcher().getEventHandler()
.handle(new RMAppEvent(applicationId, RMAppEventType.START));
}
}
8.RMAppManager
@SuppressWarnings("unchecked")
protected void submitApplication(
ApplicationSubmissionContext submissionContext, long submitTime,
String user) throws YarnException {
ApplicationId applicationId = submissionContext.getApplicationId();
RMAppImpl application =
createAndPopulateNewRMApp(submissionContext, submitTime, user);
ApplicationId appId = submissionContext.getApplicationId();
if (UserGroupInformation.isSecurityEnabled()) {
try {
this.rmContext.getDelegationTokenRenewer().addApplicationAsync(appId,
parseCredentials(submissionContext),
submissionContext.getCancelTokensWhenComplete(),
application.getUser());
} catch (Exception e) {
LOG.warn("Unable to parse credentials.", e);
// Sending APP_REJECTED is fine, since we assume that the
// RMApp is in NEW state and thus we haven‘t yet informed the
// scheduler about the existence of the application
assert application.getState() == RMAppState.NEW;
this.rmContext.getDispatcher().getEventHandler()
.handle(new RMAppRejectedEvent(applicationId, e.getMessage()));
throw RPCUtil.getRemoteException(e);
}
} else {
// Dispatcher is not yet started at this time, so these START events
// enqueued should be guaranteed to be first processed when dispatcher
// gets started.
this.rmContext.getDispatcher().getEventHandler()
.handle(new RMAppEvent(applicationId, RMAppEventType.START));
}
}
9. 异步增加Application--DelegationTokenRenewer
/** * Asynchronously add application tokens for renewal. * @param applicationId added application * @param ts tokens * @param shouldCancelAtEnd true if tokens should be canceled when the app is * done else false. * @param user user */ public void addApplicationAsync(ApplicationId applicationId, Credentials ts, boolean shouldCancelAtEnd, String user) { processDelegationTokenRenewerEvent(new DelegationTokenRenewerAppSubmitEvent( applicationId, ts, shouldCancelAtEnd, user)); }
调用如下:
private void processDelegationTokenRenewerEvent( DelegationTokenRenewerEvent evt) { serviceStateLock.readLock().lock(); try { if (isServiceStarted) { renewerService.execute(new DelegationTokenRenewerRunnable(evt)); } else { pendingEventQueue.add(evt); } } finally { serviceStateLock.readLock().unlock(); } }
从上面可以看到,通过锁形式来让线程池来处理事件或者放入到事件队列中中。
新启一个线程:
@Override public void run() { if (evt instanceof DelegationTokenRenewerAppSubmitEvent) { DelegationTokenRenewerAppSubmitEvent appSubmitEvt = (DelegationTokenRenewerAppSubmitEvent) evt; handleDTRenewerAppSubmitEvent(appSubmitEvt); } else if (evt.getType().equals( DelegationTokenRenewerEventType.FINISH_APPLICATION)) { DelegationTokenRenewer.this.handleAppFinishEvent(evt); } }
@SuppressWarnings("unchecked")
private void handleDTRenewerAppSubmitEvent(
DelegationTokenRenewerAppSubmitEvent event) {
/*
* For applications submitted with delegation tokens we are not submitting
* the application to scheduler from RMAppManager. Instead we are doing
* it from here. The primary goal is to make token renewal as a part of
* application submission asynchronous so that client thread is not
* blocked during app submission.
*/
try {
// Setup tokens for renewal
DelegationTokenRenewer.this.handleAppSubmitEvent(event);
rmContext.getDispatcher().getEventHandler()
.handle(new RMAppEvent(event.getApplicationId(), RMAppEventType.START));
} catch (Throwable t) {
LOG.warn(
"Unable to add the application to the delegation token renewer.",
t);
// Sending APP_REJECTED is fine, since we assume that the
// RMApp is in NEW state and thus we havne‘t yet informed the
// Scheduler about the existence of the application
rmContext.getDispatcher().getEventHandler().handle(
new RMAppRejectedEvent(event.getApplicationId(), t.getMessage()));
}
}
}
private void handleAppSubmitEvent(DelegationTokenRenewerAppSubmitEvent evt) throws IOException, InterruptedException { ApplicationId applicationId = evt.getApplicationId(); Credentials ts = evt.getCredentials(); boolean shouldCancelAtEnd = evt.shouldCancelAtEnd(); if (ts == null) { return; // nothing to add } if (LOG.isDebugEnabled()) { LOG.debug("Registering tokens for renewal for:" + " appId = " + applicationId); } Collection<Token<?>> tokens = ts.getAllTokens(); long now = System.currentTimeMillis(); // find tokens for renewal, but don‘t add timers until we know // all renewable tokens are valid // At RM restart it is safe to assume that all the previously added tokens // are valid appTokens.put(applicationId, Collections.synchronizedSet(new HashSet<DelegationTokenToRenew>())); Set<DelegationTokenToRenew> tokenList = new HashSet<DelegationTokenToRenew>(); boolean hasHdfsToken = false; for (Token<?> token : tokens) { if (token.isManaged()) { if (token.getKind().equals(new Text("HDFS_DELEGATION_TOKEN"))) { LOG.info(applicationId + " found existing hdfs token " + token); hasHdfsToken = true; } DelegationTokenToRenew dttr = allTokens.get(token); if (dttr == null) { dttr = new DelegationTokenToRenew(Arrays.asList(applicationId), token, getConfig(), now, shouldCancelAtEnd, evt.getUser()); try { renewToken(dttr); } catch (IOException ioe) { throw new IOException("Failed to renew token: " + dttr.token, ioe); } } tokenList.add(dttr); } } if (!tokenList.isEmpty()) { // Renewing token and adding it to timer calls are separated purposefully // If user provides incorrect token then it should not be added for // renewal. for (DelegationTokenToRenew dtr : tokenList) { DelegationTokenToRenew currentDtr = allTokens.putIfAbsent(dtr.token, dtr); if (currentDtr != null) { // another job beat us currentDtr.referringAppIds.add(applicationId); appTokens.get(applicationId).add(currentDtr); } else { appTokens.get(applicationId).add(dtr); setTimerForTokenRenewal(dtr); } } } if (!hasHdfsToken) { requestNewHdfsDelegationToken(Arrays.asList(applicationId), evt.getUser(), shouldCancelAtEnd); } }
RM:resourceManager
AM:applicationMaster
NM:nodeManager
简单的说,yarn涉及到3个通信协议:
ApplicationClientProtocol:client通过该协议与RM通信,以后会简称其为CR协议
ApplicationMasterProtocol:AM通过该协议与RM通信,以后会简称其为AR协议
ContainerManagementProtocol:AM通过该协议与NM通信,以后会简称其为AN协议
---------------------------------------------------------------------------------------------------------------------
通常而言,客户端向RM提交一个程序,流程是这样滴:
step1:创建一个CR协议的客户端
rmClient=(ApplicationClientProtocol)rpc.getProxy(ApplicationClientProtocol,rmAddress,conf)
step2:客户端通过CR协议#getNewApplication从RM获取唯一的应用程序ID,简化过的代码:
//GetNewApplicationRequest包含两项信息:ApplicationId 和 最大可申请的资源量
//Records.newRecord(...)是一个静态方法,通过序列化框架生成一些RPC过程需要的对象(yarn默认采用ProtocolBuffers(序列化框架,google ProtocolBuffers这些东东,麻烦大家google下呀,喵))
GetNewApplicationRequest request=Records.newRecord(GetNewApplicationRequest.class);
继续看代码(代码都是简化过的,亲们原谅):
GetNewApplicationResponse newApp =rmClient.getNewApplication(request);
ApplicationId appId = newApp.getApplicationId();
step3:客户端通过CR协议#submitApplication将AM提交到RM上,简化过的代码:
// 客户端将启动AM需要的所有信息打包到ApplicationSubmissionContext 中
ApplicationSubmissionContext context = Records.newRecord(ApplicationSubmissionContext.class);
。。。。//设置应用程序名称,优先级,队列名称云云
context.setApplicationName(appName);
//构造一个AM启动上下文对象
ContainerLaunchContext amContainer = Records.newRecord(ContainerLaunchContext .class)
。。。//设置AM相关的变量
amContainer.setLocalResource(localResponse);//设置AM启动所需要的本地资源
amContainer.setEnvironment(env);
context.setAMContainerSpec(amContainer);
context.setApplicationId(appId);
SubmitApplicationRequest request = Records.newRecord(SubmitApplicationRequest.class);
request.setApplicationSubmissionContext(request);
rmClien.submitApplication(request);//将应用程序提交到RM上
--------------------------------------------------------------------------------------------------------------------------------------------------
通常而言,AM向RM注册自己,申请资源,请求NM启动Container的流程是这样滴:
AM-RM流程:
step1:创建一个AR协议的客户端
ApplicationMasterProtocol rmClient = (ApplicationMasterProtocol)rpc.getProxy(ApplicationMasterProtocol.class,rmAddress,conf);
step2:AM向RM注册自己
//这里的 recordFactory.newRecordInstance(。。。)与上面的Records.newRecord(。。。)作用一样,都属于静态调用
RegisterApplicationMasterRequest request =recordFactory.newRecordInstance(RegisterApplicationMasterRequest.class);
request.setHost(host);
request.setRpcPort(port);
request.setTrackingUrl(appTrackingUrl)
RegisterApplicationMasterResponse response = rmClient.registerApplicationMaster(request);//完成注册
step3:AM向RM请求资源
一段简化的代码如下(感兴趣的朋友,还请亲自阅读源码):
synchronized(this){
askList =new ArrayList<ResourceRequest>(ask);
releaseList = new ArrayList<ContainerId>(release);
allocateRequest = BuilderUtils.newAllocateRequest(....);构造一个 allocateRequest 对象
}
//向RM申请资源,同时领取新分配的资源(CPU,内存等)
allocateResponse = rmClient.allocate(allocateRequest ) ;
//根据RM的应答信息设计接下来的逻辑(资源分配)
.....
step4:AM告诉RM应用程序执行完毕,并退出
//构造请求对象
FinishApplicationMasterRequest request = recordFactory.newRecordInstance(FinishApplicationMasterRequest.class );
request.setFinishApplicationStatus(appStatus);
..//设置诊断信息
..//设置trackingUrl
//通知RM自己退出
rmclient.finishApplicationMaster(request);
--------------------------------------------------------------------------------------------------------------------------------------------
AM-NM流程 :
step1:构造AN协议客户端,并启动Container
String cmIpPortStr = container.getNodeId().getHost()+":"+container.getNodeId().getPort();
InetSocketAddress cmAddress=NetUtils.createSocketAddr(cmIpPortStr);
anClient = (ContainerManagementProtocol)rpc.getProxy(ContainerManagementProtocol.class,cmAddress,conf)
ContainerLaunchContext ctx=Records.newRecord(ContainerLaunchContext.class);
。。。//设置ctx变量
StartContainerRequest request = Records.newRecord(StartContainerRequest.class);
request.setContainerLaunchContext(ctx);
request.setContainer(container);
anClient.startContainer(request);
Step2:为了实时掌握各个Container运行状态,AM可通过AN协议#getContainerStatus向NodeManager询问Container运行状态
Step3:一旦一个Container运行完成后,AM可通过AN协议#stopContainer释放Container
===============================================================================================
参考文献:
【1】http://www.aboutyun.com/thread-14277-1-1.html
【2】http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/
【3】http://www.bigdatas.cn/thread-59001-1-1.html
【4】http://bit1129.iteye.com/blog/2186238
【5】http://x-rip.iteye.com/blog/1541914
标签:
原文地址:http://www.cnblogs.com/davidwang456/p/4816336.html