标签:
秉着能偷懒就偷懒的精神,关于AC自动机本来不想看的,但是HanLp的源码中用户自定义词典的识别是用的AC自动机实现的。唉~没办法,还是看看吧
Aho Corasick自动机,简称AC自动机,要学会AC自动机,我们必须知道什么是Trie,也就是字典树。Trie树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。之前已经写过关于Tire与双数组Tire(Double Array Tire,以下简称DAT)的文章。
AC的优点其实包括了所有Tire树的优点,而且更加强大,考虑下面的问题
对一个长字符串S,给定一个模式串T,查看模式串T是否在S中出现过?
这个问题简单的算法就是便利S与T中的字符逐个比较,不一致则移到S的下一个字符。这种算法最坏情况下的时间复杂度是O(len(S) * len(T))
而广为人知的KMP算法就是省去了逐个比较的过程,而是直接按照next数组中的内容来进行查找,复杂度为O(len(S) + len(T))
而AC自动机较之于DAT的优点就是增加一个fail表,而省去在DAT多模式匹配时无所谓的回溯,(不过后来HanLp的作者做了实验,效率不如DAT呢。)
AC自动机的构造
知道了AC的强大,下面来看AC的构造,构造之前,先看一张AC的图,对字典{FG,HE,HERS,HIS,SHE}构造的Tire树就如下图所示:
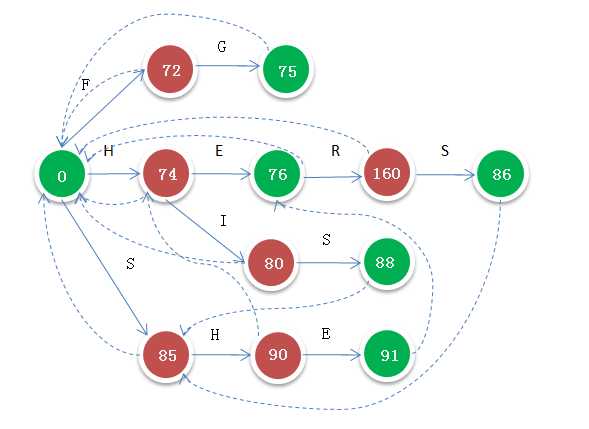
乍一看这个图很复杂,其实,只是在TIRE的基础上,对每个节点,加上了一个fail指针,如图中的虚线所示
AC建立是构建在TIRE基础上的,DAT的两要素为BASE与CHECK表,而AC的三要素为goto表,fail表与output表
goto: 即分支与儿子节点
fail :某状态匹配失败,回到fail所指状态继续匹配
output表: 状态对应的输出
把大象装冰箱分3步,所以AC构造过程也分3步:
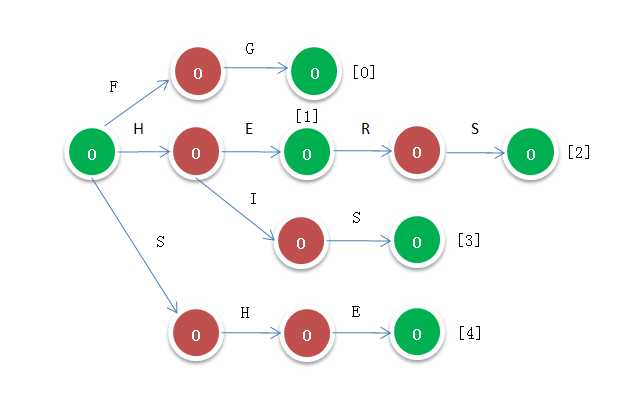
1. 对字典建立TIRE树结构,建立过程中 goto表也随之建好(即指向子节点的指针),output表初步建成,之后还要根据fail指针去扩充output,下图"[]"中的内容即为初步的output表,对应于字典中的下标
2. 步骤1生成的TIRE树,虽然有树形结构,但状态值都为0,下面用TIRE构造DAT,并且对状态State赋值。
注意,构造过程中,对是一个词的节点,即图中的绿色节点,在构造DAT时,会长生一个子节点,即标识一个词的结尾,类似与上一篇中提到的叶节点结构,到增加的子节点的转移字符取0即可,新增节点的state值即为父节点的base值
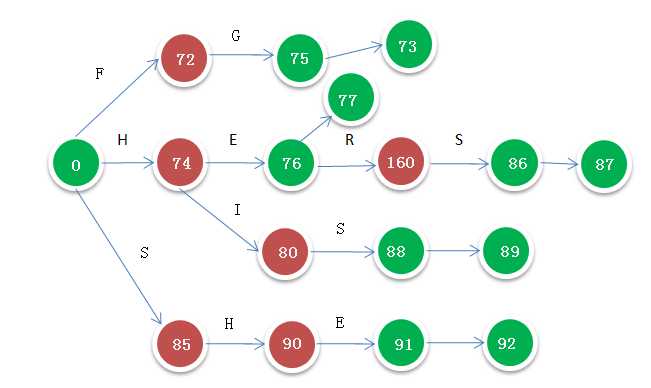
3. 遍历带有状态的TIRE,构造fail表与output表。
构造失败指针的原理: 对某个节点,其产生于字母C,沿着此节点的父节点的失败指针走,知道某个节点,他的分支状态中也有字母C,然后把当前节点的失败指针指向那个分支C指向的儿子节点,如果一直啊到root都没有这样的节点,则失败指针指向root即可。原理同KMP算法,不明白可以谷歌之。构造完后的图即如第一张图所示。
下图即构造完成后,各个表中的内容:

至此 AC自动机便构造完成了,接下来就看看怎么用它去分词了。
参考资料
Aho Corasick自动机结合DoubleArrayTrie极速多模式匹配
标签:
原文地址:http://www.cnblogs.com/ooon/p/4895307.html