python的版本比较
cpython:官网版本,使用c实现,使用最为广泛,linux自带,
Jython :python 的java实现,与java语言的互操作高于其他python实现
Ironpython:python的C#实现,将python代码编译成C#的字节码,然后运行。
pypy:python的python实现,比cpython速度要快。
########################################################
安装
win下安装。直接下载安装包直接安装即可,如需在cmd下直接执行python命令,需要配置环境变量。
配置方式为:以win7为例
计算机--右键--属性--高级系统设置--环境变量--在系统变量中,找到Path
双击 并将python的安装路径进行添加,注意分隔符为分号,确定保存后,再次打开cmd即可
l########################################################
linux下安装
如果系统自带版本较低(如centos6系列自带python版本为2.6.X),下载源码包进行编译安装,过程如下:
以centos6.4为例
打开http://www.python.org 为python 官网,下载源码包,目前最新版本为2.7.10
https://www.python.org/ftp/python/2.7.10/Python-2.7.10.tgz
yum install gcc #安装以来报 tar xf Python-2.7.10.tgz #解压源码包 cd Python-2.7.10 ./configure --prefix=/usr/local/python27makemake install mv /usr/bin/python /usr/bin/python2.6 ln -s /usr/local/bin/python2.7 /usr/bin/python
由于centos6.3需要python2.6的支持,使用python2.7会出问题
所以需要修改yum配置文件中的python指向
vi /usr/bin/yum
将头部 #!/usr/bin/python 修改为 #!/usr/bin/python2.6
########################################################
第一句python
vim hello.py
#文件结尾建议以.py结尾,原因一是可以便于文件的识别,二是被其他python文件调用时,非.py结尾的文件无法生成pyc文件(.pyc文件为python脚本的字节码文件)
#!/usr/bin/env python #linux系统下脚本文件的shebang设置,以 ./script 方式执行时, #可以为脚本指定默认的解释器 # -*- coding:utf-8 -*- #由于python脚本默认是ASCII编码,文在显示时会做一个ASCII到 #系统默认编码的转换,这时就会出错:SyntaxError: Non-ASCII character。 #需要在代码文件的第一行或第二行添加编码指示 print ”hello world“
完成后保存退出
执行脚本
python hello.py
注意:
1.# -*- coding:utf-8 -*- 的另外一种写法,即 # coding:utf-8 ,这里需要注意的是,后一种写法有时可能会不生效(没遇到过,但是有这种可能),所以推荐的写法还是第一种。
2.文件编码问题:计算机最开始的时候只有英文,而一个字节就使可以表示完所有的英文和许多的控制符号(基础ascii可以表示128个字符,为国际标准,扩展ascii扩展到255个,但不再是国际标准,ASCII的最大缺点是只能显示26个基本拉丁字母、阿拉伯数目字和英式标点符号,因此只能用于显示现代美国英语);后来计算机世界很快有其他语言的加入,但是ascii已经无法满足需求了,这时(这个时间段同时还有其他的文件编码,不一一列举),因为涉及到的字符越来越多,如中文,这个时期也有很多其他的文件编码(如果每个地区一套文件编码,本地使用没有问题,但是到了网络环境里,就会出现问题),后来大家觉得这样一套套的字符集太多了,就搞出了一个万国码,也就是Unicode,并成为业界的一个标准,unicode最少使用两个字节来编码一个字符,在使用的时候,如果要表示ascii字符的时候就会出现资源的浪费,因为ascii字符只要1个字节就可以 表示,然后,utf-8就被研究出来了,utf-8是一种可变长的的字符编码,可以用来表示unicode标准中的任何字符,且编码中的第一个字节仍与ascii兼容,utf-8使用一到四个字节来表示一个字符。
————————————————————————————
注释:
单行注释:以#开头
#单行注释
多行注释:三引号(可以为单引号或者双引号)
例:
”“”
多行注释
“”“
但是 #!/usr/bin/env python 和 # -*- coding:utf-8 -*- 因为有起特殊作用 不算注释
————————————————————————————
引号的区别
单引号和双引号都可以用来表示字符串,但是他们必须成对出现,
有一个特殊情况
"Let‘s go"
’Let\‘s go‘ #字符串中的\ 表示转义
这两种情况等价,
########################################################
关于python脚本的执行方式
python文件分三类
内置模块
第三方类库
自定义文件
python文件在执行过程
首先从磁盘读取文件,加载到内存,在进行 词法分析--语法分析--编译--执行。
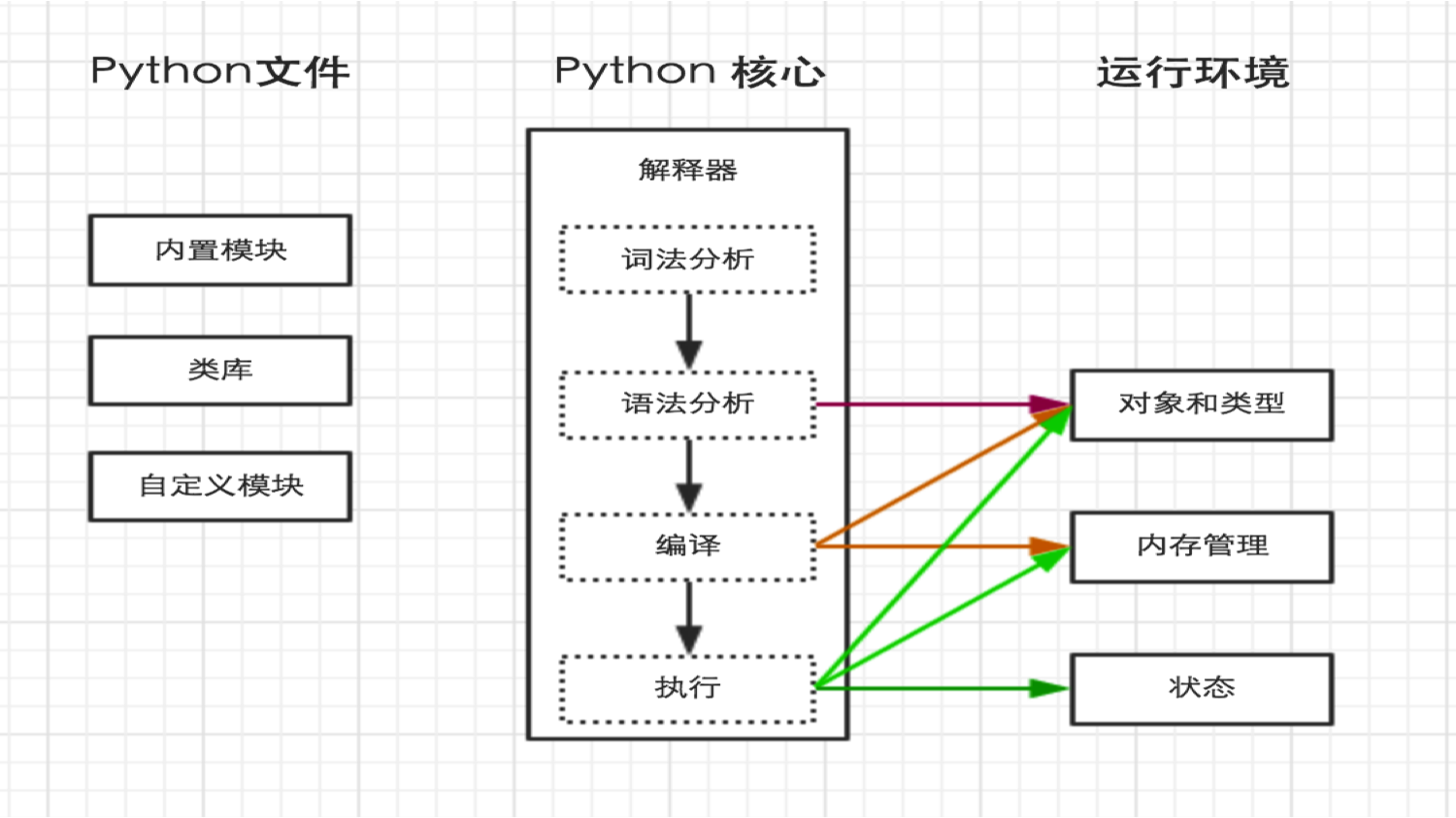
pyc文件的目的是为了加快程序的执行速度,类似与java 的class文件,
在python脚本执行期间,经过编译的结果只会存在于内存中,执行完成后,就会将结果保存到pyc文件,
这样下次就会再次进行编译,直接加载pyc文件到内存即可。
需要注意的是当hello.py 和hello.pyc文件同时存在时,python在执行前会首先判断hello.pyc文件是不是hello.py的直接编译结果,如果hello.py文件已经发生更改,那么python会再次编译hello.py文件并生成hello.pyc文件;如果hello.py未发生改变,则直接加载hello.pyc文件。
#############################################################
获取脚本参数
python提供了获取脚本参数的内置模块,sys.argv
使用方法如下
vi login.py import sys print sys.argv
执行
python login.py 123
[‘login.py‘, ‘123‘] #结果,返回一个list (稍后会对list详细说明),
##############################################################
变量
定义: 指向某个内存空间地址的指针(指针可能不准确,其实就是给某段内存空间起了一个名字)
使用规则:1.变量名称智能是字母数字下划线
2. 第一个字符不能为数字
3. 声明变量时,需要避开 关键字
4. 变量区分字母大小写
注意:在python中有对象缓冲池的机制(缓冲池的目的是为了加速程序执行),对于[-5,257]这样的小整数,系统已经初始化好,可直接拿来使用;而对于大整数,系统则提前申请了一块空间,等需要的时候在该空间创建大整数对象。这里只做简单介绍,详细的机器参考python源码(内存机制)
>>> a=3 >>> b=3 >>> id(a);id(b) 36032808 36032808 >>> c=900 >>> d=900 >>> id(c);id(d) 36315360 36315408
##############################################################
输入输出
raw_input() #获取用户输入;另外一种获取用户输入的方法为input(),两者的区别是,前者直接读取控制台的输入,可以是任意字符,而后者希望读取的是一个合法的python表达式,即输入字符串的时候需要加引号。input()本质上还是使用raw_input() 来实现的,只是调用晚raw_input() 之后在调用eval()函数。因此,除非对input() 有特别需要,否则推荐使用raw_input() 。
print #打印内容
###############################################################
流程控制与缩进
python使用缩进来进行代码的分组
分支语句if
第一种使用方式
if condition: pass
第二种使用方式(if .... else ....)
if condition: pass else: pass # pass 为占位符,表示什么都不做,执行到该pass语句时,不会执行任何操作 第三种使用方式( if ..elif ....else)
if condition: pass elif condition: pass else: pass
#######################################
循环控制(for while)
for element in SetOfObject:
print element
[else:
pass]
for循环用来遍历某一对象,还具有一个附带的可选的else语句块,
while condition:
pass
需要注意的是condition为真时,while会一直执行下去,直到condition为假
在使用循环语句的时候涉及到两个语句break 和continue
break :跳出循环
continue :结束当次循环
break示例: for i in range(5): if i==3 break print i 输出结果: 0 1 2
continue示例:
for i in range(5): if i==3 contine print i 输出结果: 0 1 2 4
range() 用于生成一个序列,以后会讲到。
########################################################
基本数据类型
数字(int long float complex)、字符串、列表、元组、布尔、字典
type(var) # 用于查看变量类型
---------------------------------------------------------------------------------------------------------
字符串:
字符串为不可变对象,连接方式有两种,一种是使用+ ,一种是使用join()
---------------------------------------------------------------------------------------------------------
字符串的连接
使用+连接两个字符串时,会生成一个新的字符串,生成的字符串需要重新申请内存,当连续相加多个字符串时,速度就慢了下来
aString = "".join("a","b","c","d","e",........) 对于join()方法 则只会有一次内存申请,速度则快
---------------------------------------------------------------------------------------------------------
字符串的格式化
字符串格式化有两种方法
第一种 %
例:
var = ‘i am %s‘ % ‘hal,age %d‘
var = ‘i am %s,age %d‘ % (‘hal‘,12)
或者
var % (‘hal‘,12)
%s 字符串
%d 数字
第二种 .format()
var =‘I am {0},age {1}‘
name.fornamt("alex",12) #推荐使用该方法,效率相对较高
---------------------------------------------------------------------------------------------------------
字符串的操作
字符串索引从0开始
var=‘qwe‘
var[0]
var[0:2] 取从0开始小于2的字符
var[0:] 从0取到最后
var[-1] 最后一个字符
var[0:-1] 0到最后一个之前
var[::-1] 字符串反转
len(var) 获取字符串长度
字符串去除空格
var.strip() 去除两头空格
var.lstrip() 去除左边空格
var.rstrip() 去除右边空格
字符串分割
var="alex,tony,eric"
var.split(‘,‘) #不指定分隔符时,默认以空格为分隔符
---------------------------------------------------------------------------------------------------------
list
列表可修改
创建列表
name_list = ["aaa","bbb"]
或
name_list = list(["aaa","bbb"]) #本质上是上面调用该语句。即 list()
分片与字符串类似
追加
append()
list.append("aaa")
删除
del list[n]
len(list) 获取长度
join() ‘_‘.join(list) _为分隔符
包含 in
‘a‘ in list 返回一个布尔值
循环
for i in list:
print i
---------------------------------------------------------------------------------------------------------
tuple
("a","b")
元组不可修改,其他与列表类似
---------------------------------------------------------------------------------------------------------
dict 字典
键值对,字典是无序的
{key:value1,name:value2,age:value3,...}
for key,value in dict.items():
print key,value
dict.keys() 所有值
dict.values() 所有键
dict.items() 所有键值对,仅仅for循环使用
---------------------------------------------------------------------------------------------------------
set
无序不重复的元素集
---------------------------------------------------------------------------------------------------------
附
算数运算符

比较运算符

赋值运算符

逻辑运算符

成员运算

身份运算

位运算

运算符优先级

##################################
初识文本操作
f=file("path",mode) #或者 open("path",mode)
f.read()
f.close() 关闭文件
read() 讲文件完整读入内存
readlines() 将文件完整读入内存并以行为分隔 返回一个列表。
xreadlines() 一行一行读入 ,已废弃
for line in f: xreadlines的方法,一次一行
write() 写入文件
writeline() 一行一行写入
mode
r 只读方式打开文件
w 只写方式打开文件
a 追加方式打开文件
w+ 读写方式打开文件
个人博客地址
本文地址
http://www.timesnotes.com/?p=68
本文出自 “Will的笔记” 博客,请务必保留此出处http://timesnotes.blog.51cto.com/1079212/1706463
原文地址:http://timesnotes.blog.51cto.com/1079212/1706463