标签:
进程切换前需要做准备工作,其中对于内核进程和用户进程在切换地址空间中的处理方式是不同的,主要因为内核进程只使用内核地址空间,而linux的内核地址空间是固定的,但用户进程就不一样了,而内核会借用用户的地址空间,mm_struct中的页表信息在tlb中是有缓存的,这一块儿的刷新问题必须保持一致性,推荐两篇文章,写得很好,对这个问题说得很清楚。
《Linux TLB 刷新的懒惰模式》
http://blog.csdn.net/Henzox/article/details/41963271
这篇文章主要讲述了在SMP处理器上,每个cpu有自己的tlb,在一个cpu借用某个用户进程的内存空间的时候,这个用户进程可能在另一个cpu上被调度执行,有可能引起这个进程内存空间的变化,tlb数据会失效,为了保持一致性,会向引用这个内存空间的cpu发送IPI消息通知其刷新对应的tlb条目。Task_struct中记录cpu对其mm_struct引用的信息存储在cpu_vm_mask中,最多支持32颗cpu信息记录,TLBSTATE_LAZY模式下,cpu处理IPI消息时,将该cpu对应位的掩码清除,不刷新tlb,下次IPI消息就不回发送到自己这里了。
《尝试总结memory barrier (经典)》
http://blog.csdn.net/zhangxinrun/article/details/5843632
这篇文章主要讲现代cpu在乱序执行以及编译优化,和JIT等技术使得cpu在真正执行指令的时候可能并不如同你写代码的时候的串行执行,加入内存壁障的作用就是防止gcc编译器对代码的优化,总的实现功能主要是保证内存壁障之前的写操作做完,内存壁障之后的读代码都从内存中重新读取数据。
内存壁障在x86上的实现方式是lock总线,这会使得所有cpu对lock涉及到的指令操作的数据的cache都失效,而lock会导致当前cpu将其cache写入内存,通过(BUS-Watching)技术,其他cpu会使有对应数据的cache失效,即下一次访问的时候必须从内存取。通过MESI协议,保持缓存一致性。
寄存器信息的切换源码
1 #define switch_to(prev,next,last) do { 2 asm volatile( 3 "pushl %%esi\n\t" 4 "pushl %%edi\n\t" 5 "pushl %%ebp\n\t" 6 "movl %%esp,%0\n\t" /* save ESP */ 7 "movl %3,%%esp\n\t" /* restore ESP */ 8 "movl $1f,%1\n\t" /* save EIP */ 9 "pushl %4\n\t" /* restore EIP */ 10 "jmp __switch_to\n" 11 "1:\t" 12 "popl %%ebp\n\t" 13 "popl %%edi\n\t" 14 "popl %%esi\n\t" 15 :"=m" (prev->thread.esp), "=m" (prev->thread.eip), 16 "=b" (last) 17 :"m" (next->thread.esp), "m" (next->thread.eip), 18 "a" (prev), "d" (next), 19 "b" (prev)); 20 } while (0)
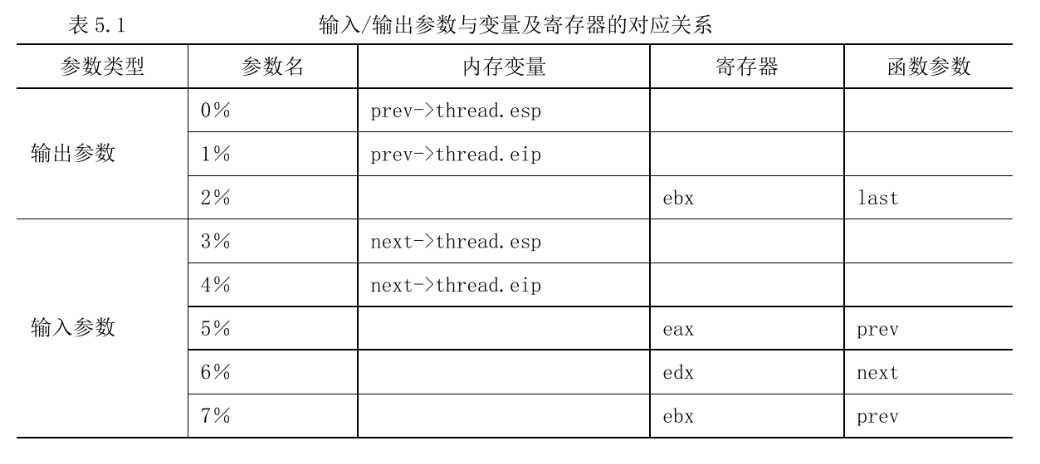
将esi,edi,ebp,esp存入task_struct中,并将1:开始处作为eip保存,下次找个进程被调度的时候,ret返回后就从这里开始执行。
加载新进程的esp,对eip压栈,这个eip实际上对应的就是上次自己被调度离开的时候存储的1:的位置,所以等最后ret返回的时候就从这里开始执行,恢复ebp,edi,esi,完全恢复进程。
__switch_to有FASTCALL标记,则这个函数的参数会在eax和edx中取,即对应prev和next。
__switch_to保存prev的fpu,fs,gs段,清空可能的io权限位图bitmap,将next进程的内核栈指针,fs,gs,可能的debug寄存器信息,并设置其io权限位图bitmap。
接下来就是内存管理了,还是挺快的。
标签:
原文地址:http://www.cnblogs.com/hmxb/p/4919228.html