标签:
当一切正常时,没有必要特别留意什么是事务日志,它是如何工作的。你只要确保每个数据库都有正确的备份。当出现问题时,事务日志的理解对于采取修正操作是重要的,尤其在需要紧急恢复数据库到指定点时。这系列文章会告诉你每个DBA应该知道的具体细节。
这个标题有点用词不当,因为运行在大容量日志恢复模式里的数据库,我们通常是长期不管理日志。但是,DBA会考虑在大容量加载时,短期切换到大容量恢复模式。当数据库在大容量模式里运行时,一些其他例如索引重建的操作会最小化日志(minimally logged),因此在日志里会使用很小的空间。对非常大的表,当重建聚集索引时,或当大容量加载百万行的数据时,在大容量日志恢复模式里运行会减少日志空间的使用,与完整恢复模式比,可以有非常大的区别。
但是,我们应该只在完全理解它对数据库备份和恢复的影响后才使用大容量日志恢复模式。例如,在包含最小化日志操作的日志记录的日志备份,是不能恢复数据库到特定时间点的。另外,如果运行的是最小化日志模式,有尾日志会备份失败的特殊情形,当数据库运行在大容量日志模式里,在事务日志里活动部分存在的记录和数据文件会因灾难而不可用(例如磁盘故障)。
如果你不幸碰到这样的灾难,这些限制会导致数据丢失。检查下对于问题数据库服务级别协议(Service Level Agreement(SLA)),对于数据丢失的可接受级别;如果是零容忍,那是不能使用大容量日志模式,即使用于很短时间,是可接受的。相反,肯定的,如果这样的数据库需要常规的索引维护或大容量加载,那数据库所有者必须理解在完整恢复模式里,进行这些操作对数据库日志空间分配的影响。
对大多数数据库已经提过这个,切换到大容量日志恢复模式能让SQL Server对特定操作最小化日志,在与日志飞速增长的斗争中是非常有用的武器。在大多数情况下,SLA会允许足够余地让使用可接受,使用精密的计划和流程,风险会最小化。
这篇文章会谈到:
当数据库运行在完整恢复模式里,所有的操作都会完整日志。这表示每个日志记录存储着回滚(撤销),前滚(重做)操作描述的足够信息。在给出的完整日志的日志文件里的所有日志记录,我们有在时间轴上对数据库做出修改的完整描述。这就是说,在恢复操作期间,SQL Server可以通过每个日志记录前滚,可以把数据库恢复到日志文件里存在的任何时间点的状态。
当数据库运行在大容量日志(或简单)恢复模式里,SQL Server会最小化特定日志操作。在一些明显最小化日志操作(BULK INSERT,bcp或索引重建)都是,其他不是。例如,在SQL Server 2008和后续版本,INSERT……SELECT在某些情况下会是最小化日志操作。(点击了解更多:https://msdn.microsoft.com/zh-cn/library/ms191244%28v=sql.100%29.aspx)
这里你会找到SQL Server会最小化日志的操作的所有清单:https://msdn.microsoft.com/zh-cn/library/ms191244.aspx 一些更通用的如下:
“可以是”最小化日志和“会是”最小化日志是不一样的,SQL Server理论上可以最小化日志,实际还是会完整日志大容量记载操作。取决于索引所在的位置和查询优化器选择的计划。主要是可恢复性需要,SQL Server只最小化日志大容量数据加载的,那是分配新区。例如,如果我们进行大容量加载到已有一些数据的聚集索引,加载会包含增加页,分页,分配新页的混合操作,因此SQL Server不能最小化日志。同理,对SQL Server是可以最小化插入表,但插入非聚集索引是完整日志。来看数据加载性能指导白皮书来进一步了解(https://msdn.microsoft.com/en-us/library/dd425070.aspx)。
在线帮助描述最小化日志为“只记录事务需要恢复的信息,不支持时间点恢复”。同理,Kalen Delaney,在她的书里,《SQL Server 2008内核剖析与故障排除》(第4章,第199页),定义最小化日志操作为“日志只记录事务回滚的足够信息,不不支持时间点恢复”。
为了理解什么是用来“最小化日志”操作的区别,取决于数据库是否使用完整或大容量日志恢复模式。我们来验证下!
在这篇文章里所有例子都假定数据和日志文件位于“D:\SQLData”,所有备份位于“D:\SQLBackups”,不是同个地方的。当运行例子时,直接修改这些位置作为你系统的正确位置(在真实系统中,请记住我们不会存储所有东西在同个硬盘!)
我们使用在SQL Server 2008里会最小化日志的SELECT...INTO语句插入ScmeTable表200条记录,每条记录2000字节。因为在SQL Server里页大小是8kb,我们会得到4行一页,总共50个数据页(加上一些分配页)。代码6.1创建一个测试数据库,完整恢复,请保证它运行在完整恢复模式,然后运行SELECT...INTO语句。
1 USE master 2 GO 3 IF DB_ID(‘FullRecovery‘) IS NOT NULL 4 DROP DATABASE FullRecovery; 5 GO 6 7 -- Clear backup history 8 EXEC msdb.dbo.sp_delete_database_backuphistory 9 @database_name = N‘FullRecovery‘ 10 GO 11 12 CREATE DATABASE FullRecovery ON 13 (NAME = FullRecovery_dat, 14 FILENAME = ‘D:\SQLData\FullRecovery.mdf‘ 15 ) LOG ON 16 ( 17 NAME = FullRecovery_log, 18 FILENAME = ‘D:\SQLData\FullRecovery.ldf‘ 19 ); 20 21 ALTER DATABASE FullRecovery SET RECOVERY FULL 22 GO 23 24 BACKUP DATABASE FullRecovery TO DISK = ‘D:\SQLBackups\FullRecovery.bak‘ 25 WITH INIT 26 GO 27 28 USE FullRecovery 29 GO 30 IF OBJECT_ID(‘dbo.SomeTable‘, ‘U‘) IS NOT NULL 31 DROP TABLE dbo.SomeTable 32 GO 33 34 SELECT TOP ( 200 ) 35 REPLICATE(‘a‘, 2000) AS SomeCol 36 INTO SomeTable 37 FROM sys.columns AS c;
(代码6.1:在完整恢复模式数据库上进行SELECT...INTO操作)
现在,在这个点,我们来看看日志内部,来理解由于SELECT...INTO语句的完整日志,SQL Server在日志里记录了什么。有一些第三方日志读取工具可以达到这个目的,但很少有工具对SQL Server 2005以上版本支持。但是,我们可以使用2个未公开和不支持的功能来查这个日志文件内容(fn_dblog)和日志备份(fn_dump_dblog),如代码6.2所示。
1 SELECT Operation , 2 Context , 3 AllocUnitName , 4 -- Description , 5 [Log Record Length] , 6 [Log Record] 7 FROM fn_dblog(NULL, NULL)
(代码6.2:使用fn_dblog查看日志内容)
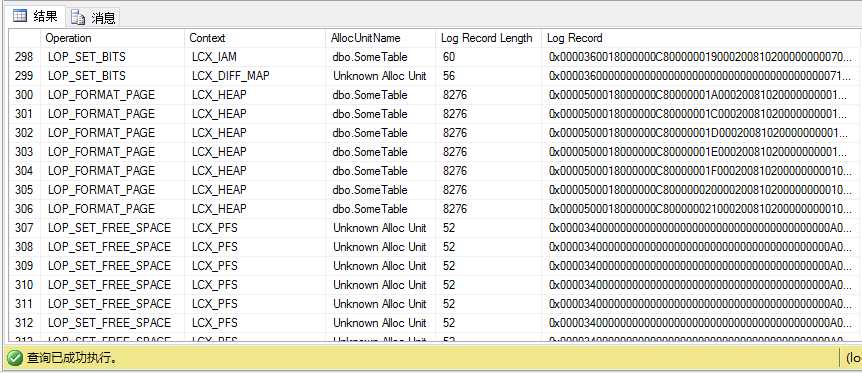
(插图6.1:在完整恢复模式数据库上SELECT...INTO后fn_dblog的输出)
插图6.1展示了8页集合的输出的一小部分(分配单元位置是dbo.SomeTable表)。注意每条记录的Context是LCX_HEAP,因此这些是数据页。我们也看到一些分配页,这里是DCM(Differential Changed Map)页,跟踪自上次数据库备份后修改过的分区,还有一些PFS(Page Free Space)页,在页上跟踪页分配和可用空闲空间。
描述对SomeTable做出改变的日志记录都是LOP_FORMAT_PAGE类型;它们都是8个一起出现,每个是8276字节长。8个一起出现的事实实际上表示SQL Server处理插入是一次一个分区,在每一页写一条日志记录。每条是8276字节表示每条包含整个数据页的镜像,包扩日志头。换句话说,在大容量日志恢复模式里,对于INSERT...INTO命令和其他,SQL Server会最小化日志,当运行在完整模式里,SQL Server不会记录每个单独的行,而是记录每个页镜像,实际上是填充的。
仔细看Log Record列显示很多字节包含0x61的十六进制值,如插图6.2所示。换做十进制是97,ASCII值是‘a’,因此这些是日志文件里的实际数据行。

(插图6.2:仔细看日志记录)
因此在完整恢复模式里,SQL Server只要通过读取日志文件就知道那些分区改变和具体如何影响页内容。现在我们对此比较下,在运行在大容量日志恢复模式里的数据上进行同样的SELECT...INTO操作,看看日志记录结果。
1 USE master 2 GO 3 IF DB_ID(‘BulkLoggedRecovery‘) IS NOT NULL 4 DROP DATABASE BulkLoggedRecovery; 5 GO 6 7 EXEC msdb.dbo.sp_delete_database_backuphistory @database_name = N‘BulkLoggedRecovery‘ 8 GO 9 10 CREATE DATABASE BulkLoggedRecovery ON 11 (NAME = BulkLoggedRecovery_dat, 12 FILENAME = ‘D:\SQLData\BulkLoggedRecovery.mdf‘ 13 ) LOG ON 14 ( 15 NAME = BulkLoggedRecovery_log, 16 FILENAME = ‘D:\SQLData\BulkLoggedRecovery.ldf‘ 17 ); 18 GO 19 20 ALTER DATABASE BulkLoggedRecovery SET RECOVERY BULK_LOGGED 21 GO 22 23 BACKUP DATABASE BulkLoggedRecovery TO DISK = 24 ‘D:\SQLBackups\BulkLoggedRecovery.bak‘ 25 WITH INIT 26 GO 27 28 USE BulkLoggedRecovery 29 GO 30 IF OBJECT_ID(‘dbo.SomeTable‘, ‘U‘) IS NOT NULL 31 DROP TABLE dbo.SomeTable 32 GO 33 34 SELECT TOP ( 200 ) 35 REPLICATE(‘a‘, 2000) AS SomeCol 36 INTO SomeTable 37 FROM sys.columns AS c;
(代码6.3:在大容量日志恢复模式上进行SELECT...INTO操作)
在BulkLoggedRecovery数据库里再次运行代码6.2的函数,这次我们获得的是完全不同的记录集。根本没有LOP_FORMAT_PAGE日志记录。
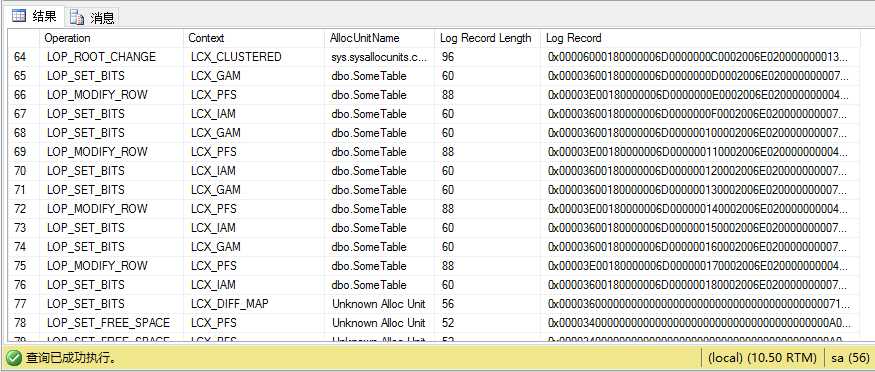
(插图6.3:在大容量日志模式数据库上SELECT...INTO后fn_dblog的输出)
这次,对SomeTable做出修改的日志记录出现GAM(Global Allocation Maps)和IAM(Index Allocation Maps)的上下文里,跟踪分区分配,加上一些PFS页。话句话说,SQL Server是记录区分配(还有任何对元数据的修改,例如系统表,这在插图6.3里并没有显示),但数据页本身并不在。在日志里没有什么数据在分配页上的引用。这里对于FullRecovery数据库,我们在对日志记录里没有看到0x61的式样,大多数日志记录是近100 byte大小。
因此,现在我们对于SQL Server最小化日志操作有了非常清晰的认识:这个操作是SQL Server记录相关区的分配,不是这些区的实际内容分配(例如数据页)。
这个影响是双重的。首先,它意味着SQL Server会写入更少的信息到事务日志,这与完整恢复模式里的等同操作的日志会明显增长的更慢。这也意味着大容量加载操作会更快(在最小化日志和大容量日志恢复的优势里会具体谈到)。
其次,但是,对于最小化日志操作所属的事务只有撤销(回滚)的足够信息,没有重做(前滚)的信息。为了回滚包含SELECT...INTO操作的事务,SQL Server需要重新分配受影响的页。因为页分配被记录了,如插图6.3所示,那是可以的。为了前滚事务是另一回事,日志记录不能用来重新分配页,当操作是最小化日志时,是不行的,SQL Server不能使用这些日志记录来重新分配页的内容。
对于删除表(DROP TABLE)和清空表(TRUNCATE TABLE)操作,作为大容量操作,SQL Server只记录区的重分配。但是,前者不是真正的最小化日志操作,因为它们的行为在所有恢复模式里一样。真正最小化日志操作的行为在完整恢复模式和在 大日志(简单)模式里是不一样的,在SQL Server日志方面。还有,对于真正最小化日志操作,当日志备份发生后,SQL Server捕获由最小化日志操作影响的所有数据页到备份文件(稍后我们会详细讨论这些),用于还原操作。这对DROP TABLE和TRUNCATE TABLE命令不会发生。
在我们讨论使用大容量日志恢复潜在的问题前,我们先来说下,对于DBA,它的主要优势。
在简单或大容量日志恢复模式里,操作可以被最小化日志。但是,如果我们从完整切换到简单恢复模式,我们触发检查点(CHECKPOINT),它会截 断日志,我们马上中断了LSN链。没有可能进行日志备份直到数据库切换回完整(或大容量日志)恢复模式,完整数据库备份后,日志链重新开始,或者我们用差 异数据库备份“桥接LSN断片”。
从完整恢复模式切换回大容量日志模式,但是不会中断日志链。从完整恢复模式切换到大容量恢复模式不需要进行数据库备份,它是马上生效。同样,当切换 回完整恢复模式,也不需要进行数据库备份。但是,在切换到大容量日志模式前立即进行一次日志备份,切换回也进行一次日志备份是个很好的做法。(阅读下一部 分的大容量日志使用的最佳实践有进一步的讨论)。
虽然在切换到大容量日志模式时有很多问题要考虑,对此我们会马上讨论,在数据丢失风险方面是个更安全的选择,因为日志链还是完整的。一旦数据库运行在大容量日志模式,真正的优势是在通过最小化日志操作使用的日志空间会下降,也提高了这些操作的潜在性能。
我们来看索引重建的一个例子,它的操作可以是最小化日志。在完整恢复模式里,索引重建操作需要与表相等或更大的空间。对于更大的表,会引起巨大的日志增长,这是论坛来自很多苦恼用户的头条问题根源——“我重建了索引,日志增长迅速/我们用完磁盘空间!”
在大容量日志恢复模式里,只有对新索引的页分配会有日志,因此事务日志上的影响会比在完整恢复模式里大大减少。这同样也适用于通过bcp或者BULK INSERT的数据加载,或通过SELECT...INTO或INSERT INTO...SELECT复制数据到新表。
为了理解这会带来多大的区别,我们来看一个例子。首先,我们创建一个聚集索引表并插入数据(每行Filler列会增加1500字节用来保证我们的表会有很多页)。
1 USE FullRecovery
2 GO
3 IF OBJECT_ID(‘dbo.PrimaryTable_Large‘, ‘U‘) IS NOT NULL
4 DROP TABLE dbo.PrimaryTable_Large
5 GO
6 CREATE TABLE PrimaryTable_Large
7 (
8 ID INT IDENTITY
9 PRIMARY KEY ,
10 SomeColumn CHAR(4) NULL ,
11 Filler CHAR(1500) DEFAULT ‘‘
12 );
13 GO
14
15 INSERT INTO PrimaryTable_Large
16 ( SomeColumn
17 )
18 SELECT TOP 100000
19 ‘abcd ‘
20 FROM msdb.sys.columns a
21 CROSS JOIN msdb.sys.columns b
22 GO
23
24 SELECT *
25 FROM sys.dm_db_index_physical_stats(DB_ID(N‘FullRecovery‘),
26 OBJECT_ID(N‘PrimaryTable_Large‘),
27 NULL, NULL, ‘DETAILED‘);
(代码6.4:创建并加载PrimaryTable_Large表)
现在我们在我们的完整恢复模式数据库里重建聚集索引(根据sys.dm_db_index_physical_stats,包含20034个页),用sys.dm_tran_database_transactions这个DMV来看看索引重建需要多少日志空间。
1 --truncate the log
2 USE master
3 GO
4 BACKUP LOG FullRecovery
5 TO DISK = ‘D:\SQLBackups\FullRecovery_log.trn‘
6 WITH INIT
7 GO
8
9 -- rebuild index and interrogate log space use, within a transaction
10 USE FullRecovery
11 GO
12 BEGIN TRANSACTION
13
14 ALTER INDEX ALL ON dbo.PrimaryTable_Large REBUILD
15 -- there‘s only the clustered index
16
17 SELECT d.name ,
18 -- session_id ,
19 d.recovery_model_desc ,
20 -- database_transaction_begin_time ,
21 database_transaction_log_record_count ,
22 database_transaction_log_bytes_used ,
23 DATEDIFF(ss, database_transaction_begin_time, GETDATE())
24 AS SecondsToRebuild
25 FROM sys.dm_tran_database_transactions AS dt
26 INNER JOIN sys.dm_tran_session_transactions AS st
27 ON dt.transaction_id = st.transaction_id
28 INNER JOIN sys.databases AS d ON dt.database_id = d.database_id
29 WHERE d.name = ‘FullRecovery‘
30 COMMIT TRANSACTION
(代码6.5:当重建聚集索引时日志空间使用率)
当我在完整恢复模式里的数据运行这个代码,从DMV里的输出信息如插图6.4所示。

(插图6.4:在完整恢复模式里索引重建后的日志空间使用)。
它花费了近18秒来重建索引,对于20210条日志记录,这个重建需要近166M日志空间;这已经忽略了回滚情况的日志,因此总的日志空间需要会更多。
如果在BulkLoggedRecovery数据库运行同样的例子,输出如插图6.5所示。

(插图6.5:在大容量日志恢复模式里索引重建后的日志空间使用)
重建看起来会稍微快一点,但是,因为这个例子的索引非常小,数据和日志文件都在同一个硬盘,这一次看不出有太大的区别。这里的要点是日志空间使用率。在大容量日志里,索引重建只用近0.8M的空间,在完整恢复模式里却有166M的日志空间使用。对于只有160M大小的表,这是最大的节约。
为了一些人想知道在简单恢复模式里,这个操作会有没有什么区别,执行代码如下:
1 /*Repeat example in SimpleRecovery*/ 2 USE master 3 GO 4 IF EXISTS ( SELECT name 5 FROM sys.databases 6 WHERE name = ‘SimpleRecovery‘ ) 7 DROP DATABASE SimpleRecovery 8 GO 9 10 EXEC msdb.dbo.sp_delete_database_backuphistory @database_name = N‘SimpleRecovery‘ 11 GO 12 13 CREATE DATABASE SimpleRecovery ON 14 (NAME = SimpleRecovery_dat, 15 FILENAME = ‘D:\SQLData\SimpleRecovery.mdf‘ 16 ) LOG ON 17 ( 18 NAME = SimpleRecovery_log, 19 FILENAME = ‘D:\SQLData\SimpleRecovery.ldf‘ 20 ); 21 22 23 ALTER DATABASE SimpleRecovery SET RECOVERY SIMPLE 24 GO 25 26 USE SimpleRecovery 27 GO 28 IF OBJECT_ID(‘dbo.PrimaryTable_Large‘, ‘U‘) IS NOT NULL 29 DROP TABLE dbo.PrimaryTable_Large 30 GO 31 CREATE TABLE PrimaryTable_Large 32 ( 33 ID INT IDENTITY 34 PRIMARY KEY , 35 SomeColumn CHAR(4) NULL , 36 Filler CHAR(1500) DEFAULT ‘‘ 37 ); 38 GO 39 40 INSERT INTO PrimaryTable_Large 41 ( SomeColumn 42 ) 43 SELECT TOP 100000 44 ‘abcd ‘ 45 FROM msdb.sys.columns a 46 CROSS JOIN msdb.sys.columns b 47 GO 48 49 SELECT * 50 FROM sys.dm_db_index_physical_stats(DB_ID(N‘SimpleRecovery‘), 51 OBJECT_ID(N‘PrimaryTable_Large‘), NULL, 52 NULL, ‘DETAILED‘); 53 54 USE SimpleRecovery 55 GO 56 BEGIN TRANSACTION 57 58 ALTER INDEX ALL ON dbo.PrimaryTable_Large REBUILD 59 -- there‘s only the clustered index 60 61 SELECT d.name , 62 -- session_id , 63 d.recovery_model_desc , 64 -- database_transaction_begin_time , 65 database_transaction_log_record_count , 66 database_transaction_log_bytes_used , 67 DATEDIFF(ss, database_transaction_begin_time, GETDATE()) AS SecondsToRebuild 68 FROM sys.dm_tran_database_transactions AS dt 69 INNER JOIN sys.dm_tran_session_transactions AS st ON dt.transaction_id = st.transaction_id 70 INNER JOIN sys.databases AS d ON dt.database_id = d.database_id 71 WHERE d.name = ‘SimpleRecovery‘ 72 COMMIT TRANSACTION
可以看下插图6.6.

(插图6.6:在简单恢复模式里索引重建后的日志空间使用)
和预计的一样,与大容量恢复模式的行为一样,因为在简单恢复模式里,最小化日志操作是和大容量日志恢复模式一样的。
这是数据库运行在大容量恢复模式里的主要原因;它提供完整恢复模式的数据库恢复选项(马上就会谈到),但是它减少了特定操作的日志空间使用量。还有注意,如果数据库是主日志传送,我们不能切换数据库到简单恢复模式,因为索引重建后没有必要重做日志传送,但我们可以切换到大容量日志模式来做索引重建。
最后,注意数据库镜像只支持完整恢复模式,如果数据库运行在主要镜像里是不能使用大容量日志恢复模式。
刚才,我们讨论了当数据库运行在大容量日志恢复模式时是如何操作的,日志只包含区分配(加上元数据),不是最小化日志操作的真实记录(例如不是插入的实际数据)。这意味着日志本身只包含回滚事务的足够信息,没有重做的信息。为了接下来的操作,SQL Server需要读取描述操作和操作影响到真实数据页的日志记录。
当任何时候SQL Server需要重做事务的时候,就会有影响,例如灾难恢复(crash recovery),在数据库恢复(restore)操作期间。对日志备份操作(log backup operation)也有影响,在这2个方面SQL Server必须复制到备份文件,但在这里SQL Server不能做到。
灾难恢复,也叫做重新恢复,是SQL Server任何时候将数据库重新上线的过程。例如,如果数据库没有正常关闭,数据库重启的时候会读取数据库事务日志。它会撤销关闭时任何未提交的事务,重做已经提交但没写入硬盘永驻的事务。
这是可行的,因为在第一篇里讨论的预写式日志(Write Ahead Logging)机制保证数据修改相关的日志记录在事务提交前或修改的数据写入硬盘前,预先写入硬盘。SQL Server可以在任何时候写入更改到数据文件,在事务提交前或之后,通过检查点或惰性写入器。因此,对于一般的操作(例如完整记录的),SQL Server在事务日志里有足够的信息来表明一个操作是否要撤销或重做,有足够的信息来前滚或后滚。
对于最小化日志的操作,然而前滚是不可能了,因为在日志里没有足够的信息。因此当在简单或大容量日志恢复模式里处理最小化日志时,另一个过程,勤奋写入器(Eager Write),保证通过最小化日志的任何区修改的大容量操作,在事务完成前都硬写入硬盘。这和在事务完成之前就写入日志的普通操作,数据页写入是通过系统进程(惰性写入器或检查点)完成有鲜明的对比。
这意味着灾难恢复从不重做最小化日志操作,因为SQL Server会保证数据页修改会在事务提交前写入硬盘,因此最小化日志对灾难恢复过程毫无影响。
SQL Server写日志记录和修改数据页在事务提交前写入硬盘的要求的一个副作用是,与常规的事务相比,最小化日志操作会稍慢,如果数据文件不能处理大量的写。最小化日志通常比常规操作快,但并不能保证。只有一个可以保证:它们写入更少的信息到事务日志。
当恢复完整,差异或日志备份时,SQL Server也需要进行重做操作。我们已经谈到,对于最小化日志操作,对于最小化日志操作,受影响的页在事务完成时写入硬盘,因此SQL Server直接复制这些页到任何完整或差异备份文件,从这些备份里恢复未影响的页。
然而从日志备份里恢复会更有趣。如果日志备份只包含相关区分配的日志记录,那么在日志备份恢复上,没有办法重建最小化日志操作影响的分区内容。这是因为,如我们刚才所看到的,日志不包含插入的数据,只有区分配和原数据。
当有最小化日志操作时为了启用日志恢复,包括在日志备份里不只是日志记录,也有任何区(8页一组)的镜像,受最小化日志操作影响的。这不意味着它们的镜像是最小化日志操作后的,但页是日式备份时的。SQL Server维护一个位图分配页,叫做ML map或bulk-logged change map,每个区都有一个位。任何收最小化日志操作影响的区都会标记为1.日志备份操作读取这个页而知道在备份里应该具体包含哪些页。然后日志备份会清空这个ML map。
因此,例如假设我们有如插图6.7所示的时间点,日志备份发生在10:00,然后在1点最小化日志操作(例如一个BULK INSERT)影响了1308-1315页,在2点一个UPDATE影响了1310页和1311页,在3点的时候另一个日志备份发生了。

(插图6.7:数据库操作和日志备份时间轴)
在10:30的日志备份,备份的日志记录覆盖了10:00-10:30的。因为在那个日志段有个最小化日志操作,它复制因最小化日志操作影响的区到日志备份里。复制了它们,因此它们会出现在日志备份里,因此它们会映射BULK INSERT和UPDATE的效果,加上在UPDATE和日志备份期间可能发生的任何进一步修改。
这影响到我们如何能恢复日志,也会影响日志备份的大小,在某些特定情况下,也会影响尾日志备份,这个我们在下一部分会详细谈到。
我们来看下最小化日志操作会如何影响时间点恢复。插图6.8描述了2个数据库的典型备份时间轴。绿色待变完整数据备份,黄色代表一系列的日志备份。2个数据库的唯一区别是第一个数据库运行在完整恢复模式,第二个数据库运行在大容量日志恢复模式。
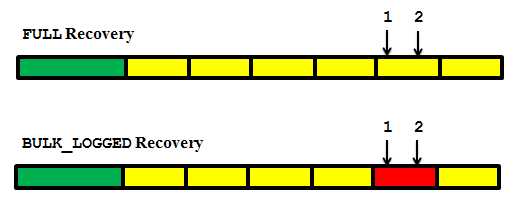
(插图6.8:数据库备份时间线)
第5个日志备份时间片是10:00-10:30。在10:10,一个BULK INSERT命令(1位置)加载了一系列数据。这个大容量数据加载一下子就完成了,但在10:20的时候有个不相关的事情发生,一个用户运行了“流氓的”数据修改命令(2位置),关键数据丢失了。项目经理通知DBA团队,要求他们恢复到导致数据丢失的事务前,在10:20前。
在完整恢复模式的数据库里,这不是问题。大容量数据加载被完整记录,我们可以恢复数据库到日志文件里的任何时间点。我们直接恢复最近一次完整数据库备份,使用without recovery,应用日志文件到不幸数据丢失事件发生前的时间点。使用RESTORE LOG命令,带STOPAT参数,停止恢复操作到10:20前的某个时间点。
在大容量日志数据库里,我们有个问题。我们恢复数据库到第1个4个日志日志备份的任何时间点,但不能恢复到第5个日志备份,因为它包含最小化日志操作。记住对于这个日志备份,我们只有受最小胡日志操作影响的分区信息,它们存在于日志备份的时间上。第5个日志备份的恢复是“孤注一掷”:要么我们不应用这个日志文件的所有操作,停止恢复到第5个文件尾,或者应用日志文件的所有操作,恢复到文件尾,或者恢复第6个日志备份的任何时间点。
如果我们尝试恢复到第5个日志备份,带有STOP AT 10:15(这是最小化日志操作和流氓修改之间的时间点),SQL 不会继续往下进行剩下的日志备份,找出页上受最小化日志操作影响的哪些操作需要撤销。它会更简单的反馈:
Msg 4341, Level 16, State 1, Line 2
This log backup contains bulk-logged changes. It cannot be used to stop at an arbitrary point in time.
遗憾的是,如果我们应用整个第5个日志备份,它会挫败恢复目的,因为错误进行的提交,它修改日志文件内部内容,因此我们直接删除了我们尝试恢复回来的数据!我们没有选择,只能恢复第4个日志尾,恢复数据库,然后报告在这个时间后的任何数据丢失。
当数据库选择运行在大容量日志模式里时,如果日志段里有最小化日志操作,我们不能恢复数据库到指定时间点,这是我们必须要考虑的,不管是短期还是长期运行。判断日志备份里是否包含最小化日志操作是很容易的。RESTORE HEADERONLY返回备份的详细问题信息,包括在HasBulkLoggedData列里。另外,在MSDB数据库的backupset表里也有has_BULK_LOGGED_data列。如果这列值为1,那么日志备份包含最小化日志操作,可以全部恢复或全部丢失。那就是说,在计划或执行恢复时得到这个消息是个令人很不愉快的意外。
最小化日志操作影响的页需要拷贝到日志备份,影响日志备份的大小。基本上,在大容量恢复模式的数据库里,对于大容量操作实际的日志增长会很少,与完整恢复模式的数据库相比,日志备份大小不会更小,对于完整恢复模式来说,相比较的日志备份会更大。
为了验证最小化日志操作的影响,还有大容量恢复模式在日志备份大小上。我们来看一个简单的例子。
首先,重新运行代码6.3片段,删除很重建BulkLoggedRecovery数据库,设置恢复模式为大容量恢复模式,再进行一次完整数据库备份。
1 USE master 2 GO 3 IF DB_ID(‘BulkLoggedRecovery‘) IS NOT NULL 4 DROP DATABASE BulkLoggedRecovery; 5 GO 6 7 EXEC msdb.dbo.sp_delete_database_backuphistory @database_name = N‘BulkLoggedRecovery‘ 8 GO 9 10 CREATE DATABASE BulkLoggedRecovery ON 11 (NAME = BulkLoggedRecovery_dat, 12 FILENAME = ‘D:\SQLData\BulkLoggedRecovery.mdf‘ 13 ) LOG ON 14 ( 15 NAME = BulkLoggedRecovery_log, 16 FILENAME = ‘D:\SQLData\BulkLoggedRecovery.ldf‘ 17 ); 18 GO 19 20 ALTER DATABASE BulkLoggedRecovery SET RECOVERY BULK_LOGGED 21 GO 22 23 BACKUP DATABASE BulkLoggedRecovery TO DISK = 24 ‘D:\SQLBackups\BulkLoggedRecovery.bak‘ 25 WITH INIT 26 GO
接下来,运行代码6.6在SomeTable表里创建50万条记录。
1 USE BulkLoggedRecovery 2 GO 3 IF OBJECT_ID(‘dbo.SomeTable‘, ‘U‘) IS NOT NULL 4 DROP TABLE dbo.SomeTable ; 5 SELECT TOP 500000 6 SomeCol = REPLICATE(‘a‘, 2000) 7 INTO dbo.SomeTable 8 FROM sys.all_columns ac1 9 CROSS JOIN sys.all_columns ac2 ; 10 GO
(代码6.6:在BulkLoggedRecovery数据库里插入50万条记录)
然后就,我们检查下当前日志空间使用率,然后备份日志。
1 DBCC SQLPERF(LOGSPACE) ; 2 --24 MB 3 4 --truncate the log 5 USE master 6 GO 7 BACKUP LOG BulkLoggedRecovery 8 TO DISK = ‘D:\SQLBackups\BulkLoggedRecovery_log.trn‘ 9 WITH INIT 10 GO
(代码6.7:为BulkLoggedRecovery数据库备份日志)
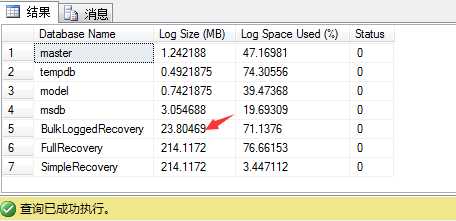
日志大小只有24MB,看到这个备份日志的大小,你会很惊讶,在我的测试里近1GB!

对于完整恢复的数据库,你会发现日志大小和日志备份大小都会近1GB!
我们假设有硬件故障导致了数据损坏,但是数据库还是在线的,我们希望恢复数据库。使用BACKUP LOG...WITH NORECOVERY,会捕获日志文件的剩余内容,把数据库放入还原状态,这样的话没有任何事务可以成功提交到数据库,我们可以进行还原操作。这种尾日志备份,和通常的日志备份一样,数据库需要在线(这样的话,SQL Server可以根据日志备份可以把信息标入数据库头)。
但是,假设对数据的损坏太厉害,数据库变得不可用,尝试无法将数据库恢复在线。如果数据库在完整恢复模式,有定期的日志备份,那么只要日志文件还是可用的,我们可以进行一次尾日志备份,但使用NO_TRUNCATE选项,例如BACKUP LOG...NO_TRUNCATE。这个选项会备份日志文件而不截断它,而且不需要数据库在线。
使用已有的备份(完整,差异(如果有的话),还有日志)和尾日志备份,我们可以恢复数据库到失败前的指定时间点。我们能这样做的原因是日志包含足够的信息来重建所有提交的事务。
但是,如果数据库运行在大容量日志模式,在事务日志的活动部分有最小化日志,那么日志没有包含足够的信息来重建所有提交的事务,当我们进行尾日志备份时,实际的数据页是需要的。如果数据文件不可用,那么尾日志备份不能复制需要的页来恢复一致的数据库。我们用BulkLoggedRecovery数据库实际操作下。
1 BACKUP DATABASE BulkLoggedRecovery 2 TO DISK = ‘D:\SQLBackups\BulkLoggedRecovery2.bak‘ 3 WITH INIT 4 GO 5 USE BulkLoggedRecovery 6 GO 7 8 IF OBJECT_ID(‘dbo.SomeTable‘, ‘U‘) IS NOT NULL 9 DROP TABLE dbo.SomeTable ; 10 SELECT TOP 200 11 SomeCol = REPLICATE(‘a‘, 2000) 12 INTO dbo.SomeTable 13 FROM sys.all_columns ac1 14 GO 15 16 SHUTDOWN WITH NOWAIT
(代码6.8:创建BulkLoggedRecovery数据库,执行SELECT INTO,然后关闭数据库)
使用SQL Server服务关闭,进入数据文件夹,删除BulkLoggedRecovery数据库的mdf数据文件,然后重启SQL Server。这不算硬盘故障的完美模拟,但对于我们的演示目的已经达到。
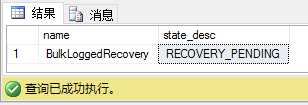
当SQL Server重启时,数据库是不可用的,这一点也不奇怪,因为主数据文件丢失。数据库状态是Recovery_Pending,表示SQL不能打开数据库在它上面运行故障恢复。
USE master GO SELECT name , state_desc FROM sys.databases WHERE name = ‘BulkLoggedRecovery‘
(代码6.9:BulkLoggedRecovery数据库是RECOVERY_PENDING状态)
在代码6.10里,我们尝试进行尾日志备份(注意NO_TRUNCATE表示COPY_ONLY且CONTINUE_AFTER_ERROR(仅复制且忽略错误继续))
1 BACKUP LOG BulkLoggedRecovery 2 TO DISK = ‘D:\SQLBackups\BulkLoggedRecovery_tail.trn‘ 3 WITH NO_TRUNCATE
(代码6.10:使用BACKUP LOG…WITH NO_TRUNCATE尝试尾日志备份)

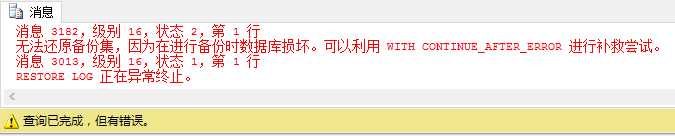
很好,已经成功执行(尽管有警告,在错误日志没有错误)。现在,我们尝试恢复数据库,如代码6.11所示。
1 RESTORE DATABASE BulkLoggedRecovery 2 FROM DISK = ‘D:\SQLBackups\BulkLoggedRecovery2.bak‘ 3 WITH NORECOVERY 4 5 RESTORE LOG BulkLoggedRecovery 6 FROM DISK = ‘D:\SQLBackups\BulkLoggedRecovery_tail.trn‘ 7 WITH RECOVERY
(代码6.11:尝试恢复BulkLoggedRecovery)

1 RESTORE DATABASE BulkLoggedRecovery 2 FROM DISK = ‘D:\SQLBackups\BulkLoggedRecovery2.bak‘ 3 WITH NORECOVERY 4 5 RESTORE LOG BulkLoggedRecovery 6 FROM DISK = ‘D:\SQLBackups\BulkLoggedRecovery_tail.trn‘ 7 WITH RECOVERY, CONTINUE_AFTER_ERROR
(代码6.12:使用CONTINUE_AFTER_ERROR恢复日志备份)
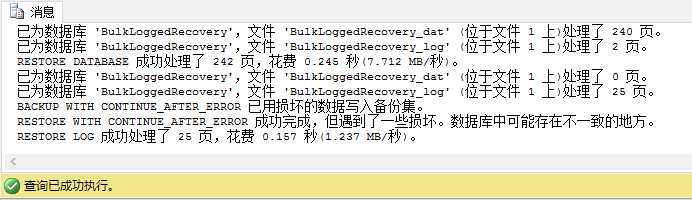
成功执行,我们检查下恢复数据库的状态。重新运行下代码6.9,你会发现数据库已经在线。
1 USE master 2 GO 3 SELECT name , 4 state_desc 5 FROM sys.databases 6 WHERE name = ‘BulkLoggedRecovery‘
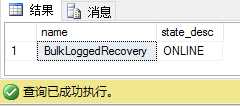
我们再看看SELECT...INTO的SomeTable也存在,因此我们看看表里的数据(记住,页分配是记录了,但页的内容是没有记录的)。
1 USE BulkLoggedRecovery 2 GO 3 IF OBJECT_ID(‘dbo.SomeTable‘, ‘U‘) IS NOT NULL 4 PRINT ‘SomeTable exists‘ 5 6 SELECT * 7 FROM SomeTable
(代码6.13:尝试查询SomeTable表)

注意,这个信息是来自SQL Server 2008R2。如果你测试的其他版本的数据库,错误信息可能会不同,这看起来并不好;我们运行DBCC看下数据库状态。
1 DBCC CHECKDB (‘BulkLoggedRecovery‘) WITH NO_INFOMSGS, ALL_ERRORMSGS
(代码6.14:使用DBCC CHECKDB检查BulkLoggedRecovery状态)

非常遗憾,这看起来非常糟糕(TempDB空间还没用完)。现在唯一合理的选择是重新恢复,但不恢复尾日志备份。这就意味着在正常日志备份和灾难点的任何提交的事务都丢失了。
当决定数据库运行在大容量日志恢复模式的时间长短时,这个另一个要考虑的重要因素。在完整恢复模式里,尾日志备份只需要访问事务日志。因此,我们还可以备份事务日志即使由于例如硬盘故障导致MDF文件不可用。但是,在大容量日志模式里,如果字上次日志备份有最小化日志操作,这意味着我们不能进行尾日志备份,如果数据文件包含有最小化日志操作的数据变得不可用。这个原因是当在大容量日志恢复模式里进行事务日志备份时,SQL Server需要备份因大容量操作的修改的所有区事务日志备份文件,还有事务日志条目。换句话说,SQL Server需要访问数据文件来进行尾日志备份。
最后,检查下数据库的SLA来看下数据丢失风险的可接受问题。如果不允许数据丢失,那么计划所有操作在完整恢复模式里,这会影响到日志的增长。如果你能在最大数据丢失范围允许内用最小化完整想要的操作,即SLA指出的,那么你可以考虑使用大容量恢复模式。
当使用大容量恢复模式时,它的黄金法则是尽量短时间使用,且可能远隔离最小化操作到它们的日志本身。因此,在切换到大容量日志模式前立即进行一次事务日志备份,切换回完整恢复模式后也立即进行一次日志备份。这可以保证在日志间隔里的最小化日志操作的事务,时间尽可能短的,数量尽可能数量小。
为了演示这个如何减少风险,假设下列情景:
在这个情况下,凌晨3:15的日志备份会失败,接下来可以做一次尾日志备份。我们只能恢复数据库到完整备份和第一个2个日志备份,因此我们丢失了近55分钟的数据。
换另一个情况,我们调整下,就会有更好的情况:
这里,3:15的日志备份会失败,但随后我们能进行一次尾日志备份,因为日志备份4保证在活动日志里没有最小化日志操作。那么我们恢复完整备份,4个事务日志备份,还有尾日志备份,恢复数据库导凌晨3:15灾难前的时间点。
即使有这些预防性的日志备份,最好还是正常备份之外进行任何的最小化日志操作,当很少有其他事务进行的时候。这个方法,如果出错的话,我们可以直接重新进行大容量加载来恢复数据。
即使你通过在每个大容量操作前后进行额外的日志备份来最小化风险,还是不建议你连续运行数据库在大容量模式。这个会非常困难,取决于你的环境,对谁可能在什么时候进行最小化日志操作进行完全控制。记住:任何表拥有者可以在表上进行创建和重建索引;任何可以建表的人也可以运行SELECT...INTO语句。
最后,我们建议阅读下数据加载性能指南(https://msdn.microsoft.com/en-us/library/dd425070.aspx),它在获得高速大容量数据修改提供很多建议,还有讨论了使用跟踪标记610如何衡量来自最小化日志的潜在效益。
大容量恢复模式提供这样一种方式:进行数据加载和一些例如索引重建数据库维护操作,不会产生在完整恢复模式里事务日志增长过快的问题,但同时保持日志链是完整的。这个缺点包括如果灾难发生的话会有很大风险丢失大容量操作期间的数据。换句话说,当还原的日志文件包含最小化日志操作,你不能使用STOPAT选项。还原整个事务日志备份来前滚数据库还是可以的,或者恢复数据库到不包含最小化操作的事务前的时间点。但是,在程序BUG里,或者用户误删造成的数据丢失,在这最小化日志操作期间,是不能恢复到日志里的特定时间点里日志记录,删除的记录也不能恢复。
当使用大容量日志恢复模式时,记住会增加数据丢失的风险,只在数据库维护或大容量数据加载操作时使用这个模式,不是默认就使用大容量日志恢复模式。
尽管有潜在增加的风险,它还是个可行且有用的选项,当DBA计划大数据加载或索引维护时还是可以考虑的。
非常感谢《SQL Server Backup and Restore》的作者Shawn McGehee,为本篇数据库恢复部分提供了额外材料。
也感谢您花这么长时间,这么耐心的看完这篇文章。
感谢关注!!!
SQL Server中的事务日志管理(6/9):大容量日志恢复模式里的日志管理
标签:
原文地址:http://www.cnblogs.com/woodytu/p/4912375.html