标签:
http://blog.chinaunix.net/uid-25324849-id-3110075.html
部分转自:http://blog.chinaunix.net/uid-20620288-id-3025213.html
1、首先要明确进程和线程的含义:
进程(Process)是具有一定独立功能的程序关于某个数据集合上的一次运行活动,是系统进行资源分配和调度的一个独立单位。与程序相比,程序只是一组指令的有序集合,它本身没有任何运行的含义,只是一个静态实体。进程是程序在某个数据集上的执行,是一个动态实体。它因创建而产生,因调度而运行,因等待资源或事件而被处于等待状态,因完成任务而被撤消,反映了一个程序在一定的数据集上运行的全部动态过程。
每个正在系统上运行的程序都是一个进程。每个进程包含一到多个线程。进程也可能是整个程序或者是部分程序的动态执行。线程是一组指令的集合,或者是程序的特殊段,它可以在程序里独立执行。也可以把它理解为代码运行的上下文。所以线程基本上是轻量级的进程,它负责在单个程序里执行多任务。通常由操作系统负责多个线程的调度和执行。
多线程是为了同步完成多项任务,不是为了提高运行效率,而是为了提高资源使用效率来提高系统的效率。线程是在同一时间需要完成多项任务的时候实现的。
使用线程的好处有以下几点:
a)使用线程可以把占据长时间的程序中的任务放到后台去处理
b)用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度
c)程序的运行速度可能加快
d)在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
2、其次来看下线程和进程的关系
线程是属于进程的,线程运行在进程空间内,同一进程所产生的线程共享同一内存空间,当进程退出时该进程所产生的线程都会被强制退出并清除。线程可与属于同一进程的其它线程共享进程所拥有的全部资源,但是其本身基本上不拥有系统资源,只拥有一点在运行中必不可少的信息(如程序计数器、一组寄存器和栈)。
3、然后我们来看下线程和进程间的比较
|
子进程继承父进程的属性: |
子线程继承主线程的属性: |
|
实际用户ID,实际组ID,有效用户ID,有效组ID; 附加组ID; 进程组ID; 会话ID; 控制终端; 设置用户ID标志和设置组ID标志; 当前工作目录; 根目录; 文件模式创建屏蔽字(umask); 信号屏蔽和安排; 针对任一打开文件描述符的在执行时关闭(close-on-exec)标志; 环境; 连接的共享存储段; 存储映射; 资源限制; |
进程中的所有信息对该进程的所有线程都是共享的; 可执行的程序文本; 程序的全局内存; 堆内存; 栈; 文件描述符; 信号的处理是进程中所有线程共享的(注意:如果信号的默认处理是终止该进程那么即是把信号传给某个线程也一样会将进程杀掉);
|
|
父子进程之间的区别: |
子线程特有的: |
|
fork的返回值(=0子进程); 进程ID不同; 两个进程具有不同的父进程ID; 子进程的tms_utime,tms_stime,tms_cutime以及tms_ustime均被设置为0; 不继承父进程设置的文件锁; 子进程的未处理闹钟被清除; 子进程的未处理信号集设置为空集; |
线程ID; 一组寄存器值; 栈; 调度优先级和策略; 信号屏蔽字; errno变量; 线程私有数据; |
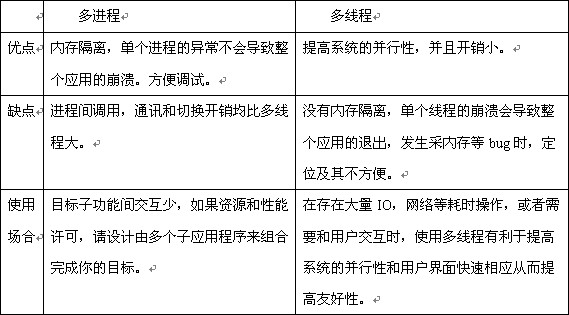
3、设计时考虑的使用技巧
1.尽量避免长驻内存的进程,例如那些很少用到的功能,或周期性很长(10分钟以上),把它们的功能提取出来,做成一个小的应用程序。需要的时候再把它们拉起来(如通过crontab配置,或直接system)。
2.把目标设计成子功能系统的组合可用提高重用的易用性和维护性。
把目标根据功能划分不同的子系统,子系统间遵循特定的协议(文本或XML),由通讯联系起来,协作完成目标。
也就是说,我们在做设计的时候可以如下考虑:
1、线程的创建以及线程间的通信和同步都比进程要快。在多核CPU上的任务分割是对线程而言的,不是进程。
2、如果不需要频繁的创建和销毁 执行的效率是并不多的,需要频繁创建的话,线程快。
3、其它的就根据你的实际情况选择了, 要是没有数据通信什么的,线程间的通信比进程间方便。最关键的一点,多线程可以让同一个程序的不同部分并发执行。
所以在做安防系统的时候,报警系统和监控系统之间可以用多进程来做,对于报警系统中可以用多线程来实现如果发生意外,可以向用户发送消息,同时鸣笛,以及如果是火警的话,可以打开阀门等。
进程间通信
unix系统主要进程间通信机制(IPC)
管道
FIFO(命名管道)
消息队列
共享内存
信号量
套接字
3. 管道
详细请见:
http://blog.chinaunix.net/space.php?uid=25324849&do=blog&id=207407
管道是最常见的IPC机制,是单工的,如果要两个进程实现双向传输则需要两个管道,管道创建的时候既有两端,一个读端和一个写端。两个进程要协调好,一个进程从读的方向读,一个进程从写的方向写,并且只能在关系进程间进行,比如父子进程,通过系统调用pipe()函数实现。
#include
int pipe(int fd[2]);
fd[0]:文件描述符,用于读操作
fd[1]:文件描述符,用于写操作
返回值:成功返回0,如果创建失败将返回-1并记录错误码
4. FIFO
详细请见:
http://blog.chinaunix.net/space.php?uid=25324849&do=blog&id=207413
FIFO又称命名管道,通过FIFO的通信可以发生在任何两个进程之间,且只需要对FIFO有适当的访问权限,对FIFO的读写操作与普通文件类似,命名管道的创建是通过mkfifo()函数创建的。
#include
int mkfifo(const char *filename, mode_t mode)
filename:命名管道的文件名
mode:访问权限
返回值:若成功则返回0,否则返回-1,错误原因存于errno中。
4.1 FIFO服务器实例
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define SERVER_FIFO_NAME "./serv_fifo"
#define CLIENT_FIFO_NAME "./cli_%d_fifo"
#define BUFFER_SIZE 20
struct data_to_pass_st {
pid_t client_pid;
char some_data[BUFFER_SIZE - 1];
};
int main()
{
int server_fifo_fd, client_fifo_fd;
struct data_to_pass_st my_data;
int read_res;
char client_fifo[256];
char *tmp_char_ptr;
mkfifo(SERVER_FIFO_NAME, 0777);
server_fifo_fd = open(SERVER_FIFO_NAME, O_RDONLY);
if (server_fifo_fd == -1) {
fprintf(stderr, "Server fifo failure\n");
exit(EXIT_FAILURE);
}
sleep(10); /* lets clients queue for demo purposes */
do {
read_res = read(server_fifo_fd, &my_data, sizeof(my_data));
if (read_res > 0) {
tmp_char_ptr = my_data.some_data;
while (*tmp_char_ptr) {
*tmp_char_ptr = toupper(*tmp_char_ptr);
tmp_char_ptr++;
}
sprintf(client_fifo, CLIENT_FIFO_NAME, my_data.client_pid);
client_fifo_fd = open(client_fifo, O_WRONLY);
if (client_fifo_fd != -1) {
write(client_fifo_fd, &my_data, sizeof(my_data));
close(client_fifo_fd);
}
}
} while (read_res > 0);
close(server_fifo_fd);
unlink(SERVER_FIFO_NAME);
exit(EXIT_SUCCESS);
}
4.2 FIFO客户实例
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define SERVER_FIFO_NAME "./serv_fifo"
#define CLIENT_FIFO_NAME "./cli_%d_fifo"
#define BUFFER_SIZE 20
struct data_to_pass_st {
pid_t client_pid;
char some_data[BUFFER_SIZE - 1];
};
int main()
{
int server_fifo_fd, client_fifo_fd;
struct data_to_pass_st my_data;
int times_to_send;
char client_fifo[256];
server_fifo_fd = open(SERVER_FIFO_NAME, O_WRONLY);
if (server_fifo_fd == -1) {
fprintf(stderr, "Sorry, no server\n");
exit(EXIT_FAILURE);
}
my_data.client_pid = getpid();
sprintf(client_fifo, CLIENT_FIFO_NAME, my_data.client_pid);
if (mkfifo(client_fifo, 0777) == -1) {
fprintf(stderr, "Sorry, can‘t make %s\n", client_fifo);
exit(EXIT_FAILURE);
}
for (times_to_send = 0; times_to_send < 5; times_to_send++) {
sprintf(my_data.some_data, "Hello from %d", my_data.client_pid);
printf("%d sent %s, ", my_data.client_pid, my_data.some_data);
write(server_fifo_fd, &my_data, sizeof(my_data));
client_fifo_fd = open(client_fifo, O_RDONLY);
if (client_fifo_fd != -1) {
if (read(client_fifo_fd, &my_data, sizeof(my_data)) > 0) {
printf("received: %s\n", my_data.some_data);
}
close(client_fifo_fd);
}
}
close(server_fifo_fd);
unlink(client_fifo);
exit(EXIT_SUCCESS);
}
5. 消息队列
详细请见:
http://blog.chinaunix.net/space.php?uid=25324849&do=blog&id=207459
消息队列有如下特点:
(1) 通过消息队列key值来定义和生成消息队列
(2) 任何进程只要有访问权限并且知道key就可以访问消息队列
(3) 消息队列为内存块方式数据段
(4) 消息队列的消息长度可为系统参数限制内的任何长度
(5) 消息队列有消息类型,访问可以按类型访问
(6) 在一次读写操作前都必须取得消息标识符,即访问权,访问后脱离关系
(7) 消息队列中的某条消息被读后立即自动的从消息队列中删除
(8) 消息队列具有加锁处理机制
(9) 在权限允许时,消息队列的信息可以双向传递
6. 共享内存
详细请见:
http://blog.chinaunix.net/space.php?uid=25324849&do=blog&id=207467
共享内存是效率最高的IPC机制,他允许任何两个进程访问相同的逻辑内存区,它具有一下特点:
(1) 通过共享内存key值定义和生成共享内存
(2) 任何进程只要有访问权限并且知道key就可以访问共享内存
(3) 共享内存为内存块方式数据段
(4) 共享内存的消息长度可为系统参数限制内的任何长度
(5) 共享内存的访问方式与数组的访问方式相同
(6) 在取得共享内存标识符将共享内存与进程数据段连接后即可以开始对其进行读写操作,在所有操作完成之后再做共享内存与进程数据段的脱离操作,才完成内存访问的过程
(7) 共享内存中的数据不会因为数据被进程读取后消失
(8) 共享内存不具备锁机制,所有共享内存最好与信号量一起使用来保证数据的一致性
(9) 在权限允许时,共享内存的信息传递时双向的
7. 信号量
详细请见:
http://blog.chinaunix.net/space.php?uid=25324849&do=blog&id=207464
信号量是一种同步机制,主要用途是保护临界资源(在一个时刻只能被一个进程所拥有),通常与共享内存一起使用。
6.1 semget()函数
#include
int semget(key_t key, int num_sems, int sem_flags)
key:信号量集合的键
num_sems:信号量集合里面元素个数
sem_flags:任选参数
返回值:返回信号量集合标识符,出错返回-1
6.2 semop()函数
#include
int semop(int sem_id, struct sembuf *sem_ops , size_t num_sem_ops)
sem_id: 信号量集合标识符
sem_ops:信号量操作结构的指针
num_sem_ops:信号量操作结构的个数
6.3 semctl)函数
#include
int semctl (int sem_id, int sem_num, int command, …)
sem_id: 信号量集合标识符
sem_num:信号量元素编号
command:控制命令
…:命令参数列表
返回值:根据命令返回相应的值,出错返回-1
http://timyang.net/linux/linux-process/
上周碰到部署在真实服务器上某个应用CPU占用过高的问题,虽然经过tuning, 问题貌似已经解决,但我对tuning的方式只是基于大胆的假设并最终生效了。我更希望更多的求证一下程序背后CPU及OS kernel当时的运作机制。所以我读了一些Linux内核设计与实现及其他一些相关资料,对Linux process的机制与切换有了更多一些体会。本文尽可能条理一点,但由于牵涉点较多,同时自己可能觉得某些点有记录的价值,因此文字可能会零散。
Linux进程的状态比较容易理解,值得注意的是 UNINTERRUPTIBLE 及 ZOMBIE
TASK_RUNNING
TASK_INTERRUPTIBLE
TASK_UNINTERRUPTIBLE 此时进程不接收信号,这就是为什么有时候kill一个繁忙的进程没有响应。
TASK_ZOMBIE 我们经常 kill -9 pid 之后运行ps会发现被kill的进程仍然存在,状态为 zombie。zombie的进程实际上已经结束,占用的资源也已经释放,仅由于kernel的相关进程描述符还未释放。
TASK_STOPPED
Kernel space是供内核,设备驱动运行的内存区域。user space是供普通应用程序运行的区域。每一个进程都运行在自己的虚拟内存区域,不能访问其他进程的内存空间。普通进程不能访问kernel space, 只能通过系统调用来间接进行。当系统内存比较紧张时,非当前运行进程user space可能会被swap到磁盘。
使用命令 pmap -x 可以查看进程的内存占用信息; lsof -a -p 可以查看一个进程打开的文件信息。ps -Lf 可以查看进程的线程数。
另外procfs也是一个分析进程结构的好地方。procfs是一个虚拟的文件系统,它把系统中正在运行的进程都显现在/proc/目录下。
进程创建通常调用fork实现。创建后子进程和父进程指向同一内存区域,仅当子进程有write发生时候,才会把改动的区域copy到子进程新的地址空间,这就是copy-on-write技术,它极大的提高了创建进程的速度。
Linux线程是通过进程来实现。Linux kernel为进程创建提供一个clone()系统调用,clone的参数包括如 CLONE_VM, CLONE_FILES, CLONE_SIGHAND 等。通过clone()的参数,新创建的进程,也称为LWP(Lightweight process)与父进程共享内存空间,文件句柄,信号处理等,从而达到创建线程相同的目的。
Linux 2.6的线程库叫NPTL(Native POSIX Thread Library)。POSIX thread(pthread)是一个编程规范,通过此规范开发的多线程程序具有良好的跨平台特性。尽管是基于进程的实现,但新版的NPTL创建线程的效率非常高。一些测试显示,基于NPTL的内核创建10万个线程只需要2秒,而没有NPTL支持的内核则需要长达15分钟。
在Linux 2.6之前,Linux kernel并没有真正的thread支持,一些thread library都是在clone()基础上的一些基于user space的封装,因此通常在信号处理、进程调度(每个进程需要一个额外的调度线程)及多线程之间同步共享资源等方面存在一定问题。为了解决这些问题,当年IBM曾经开发一套NGPT(Next Generation POSIX Threads), 效率比 LinuxThreads有明显改进,但由于NPTL的推出,NGPT也完成了相关的历史使命并停止了开发。
NPTL的实现是在kernel增加了futex(fast userspace mutex)支持用于处理线程之间的sleep与wake。futex是一种高效的对共享资源互斥访问的算法。kernel在里面起仲裁作用,但通常都由进程自行完成。
NPTL是一个1×1的线程模型,即一个线程对于一个操作系统的调度进程,优点是非常简单。而其他一些操作系统比如Solaris则是MxN的,M对应创建的线程数,N对应操作系统可以运行的实体。(N<m),优点是线程切换快,但实现稍复杂。< p="">
进程接收信号有两种:同步和异步。同步信号比如SEGILL(非法访问), SIGSEGV(segmentation fault)等。发生此类信号之后,系统会立即转到内核陷阱处理程序,因此同步信号也称为陷阱。异步信号如kill, lwp_kill, sigsend等调用产生的都是,异步信号也称为中断。
kill 调用的是 SIGTERM, 此信号可以被捕获和忽略。
kill -9 调用的是 SIGKILL, 杀掉进程,不能被捕获和忽略。
SIGHUP是在终端被断开时候调用,如果信号没有被处理,进程会终止。这就是为什么突然断网刚通过远程终端启动的进程都终止的原因。防止的方法是在启动的命令前加上 nohup 命令来忽略 SIGHUP信号。如 nohup ./startup.sh &
很多应用程序通常捕获SIGHUP用来实现一些自定义特性,比如通过控制台传递信号让正在运行的程序重新加载配置文件,避免重启带来的停止服务的副作用。可惜的是,在JAVA中没法直接使用这一功能,SUN JVM没有官方的signal支持,尽管它已经可以实现,详情可参看Singals and Java.
另外有个有趣的现象是 zombie 状态的进程 kill/kill -9 都没有任何作用,这是由于进程本身已经不存在,所以没有相应的进程来处理signal, zombie状态的进程只是kernel中的进程描述符及相关数据结构没有释放,但进程实体已经不存在了。
关于僵尸进程,也可参看下酷壳上的这篇Linux 的僵尸(zombie)进程,从程序的角度解释了相关原理。
标签:
原文地址:http://www.cnblogs.com/virusolf/p/4946039.html