标签:
参考文章:http://www.cnblogs.com/yicoder/
因为最近有几个实验需要处理大型数据,因为需要读取的是一千万个double型的数据,虽然不要求快速读取文件数据,但是实在是无法忍受那几十秒钟的停顿。所以上网搜了下关于大数据的处理。
虽然可以利用scanf()提高读取的速度,但还是有几十秒钟的停顿。所以在这里选择使用fread()读取出所有的字符。
为了方便实验,先写了个生成 0< n <10,的double型数据n的文件数据。这个没做优化,时间较久。
源码:
void product_data ()
{
uniform_int_distribution<unsigned> u(0, 9999);
default_random_engine e (time(0));
freopen ("data.txt", "w", stdout);
for (int i = 0; i < 10000000; i++){
cout << (double)u(e)/1000 << endl;
}
fclose(stdout);
}
各种方法的结果对比
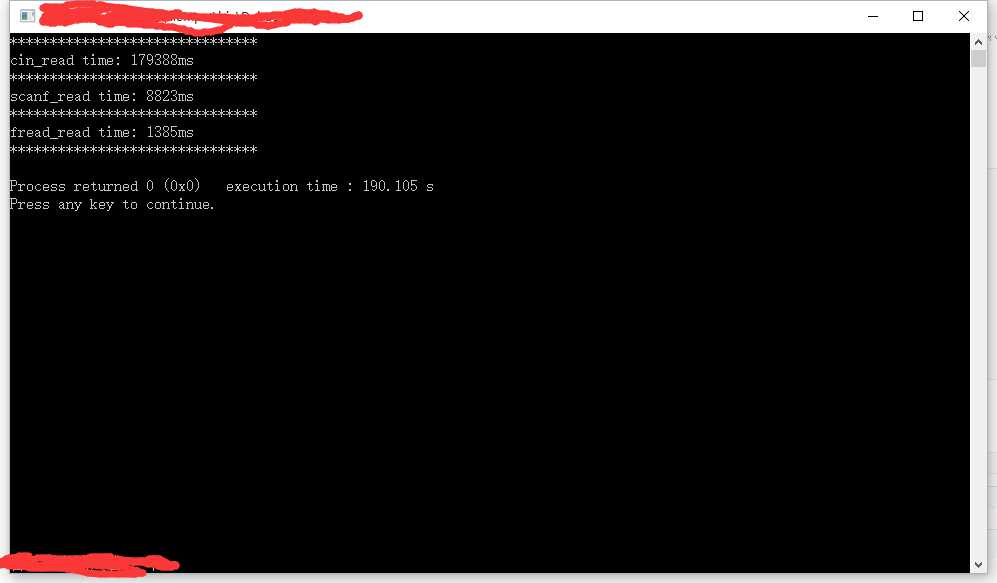
可见使用fread读取整个文件要比其他两种方法更快。
cin 比 scand 慢的原因很清楚,流数据处理比标准化处理要慢。而用fread更快的原因是吧所有数据当作一个字符串来读取,一次读入整个文件,这种方法的主要时间开销是把字符转换成要求的数值。
虽然用fread读取要快得多,但是这种方法却有很大的缺陷,buffer数组的容量要比文件所包含的所有字符都要大,要不然不能读取出所有的数据,或许可以利用分块处理解决这个问题。如果各位大虾有更好的方法请指点一二。
源码:
#include <iostream> #include <fstream> #include <ctime> #include <random> #include <cstdio> #define N 10000000 #define M 70000000 using namespace std; void cin_read() { time_t start_time = clock (); double *nums = new double [N]; freopen ("data.txt", "r", stdin); for (int i = 0; i < N; i++){ cin >> nums[i]; } time_t end_time = clock (); fclose (stdin); cout << "cin_read time: " << end_time - start_time << "ms" << endl; } void scanf_read() { time_t start_time = clock (); double *nums = new double [N]; freopen ("data.txt", "r", stdin); for (int i = 0; i < N; i++){ scanf ("%lf", &nums[N]); } time_t end_time = clock (); fclose (stdin); cout << "scanf_read time: " << end_time - start_time << "ms" << endl; } double* transform_num(char* buffer, int lenght) { bool is_dec = false; double *nums = new double [M]; int k = 0; int nt = 10; for (int i = 0; i < lenght; i++){ if (buffer [i] == ‘\n‘){ k++; nt = 10; continue; } else if (buffer [i] == ‘.‘)is_dec = true; if (!is_dec)nums[k] = buffer[i] - ‘0‘; else { nums[k] += (double)(buffer[i] - ‘0‘)/nt; nt = nt*nt; } } } void fread_read() { time_t start_time = clock (); freopen ("data.txt", "r", stdin); char *buffer = new char [M]; //把所有字符一次全部读取到buf里面,包括‘\n‘ int lenght = fread (buffer, 1, M, stdin); double *nums = transform_num (buffer, lenght); time_t end_time = clock (); fclose (stdin); cout << "fread_read time: " << end_time - start_time << "ms" << endl; } void product_data () { uniform_int_distribution<unsigned> u(0, 9999); default_random_engine e (time(0)); freopen ("data.txt", "w", stdout); for (int i = 0; i < 10000000; i++){ cout << (double)u(e)/1000 << endl; } fclose(stdout); } int main() { cout << "*******************************" << endl; cin_read(); cout << "*******************************" << endl; scanf_read(); cout << "*******************************" << endl; fread_read(); cout << "*******************************" << endl; return 0; }
完。
标签:
原文地址:http://www.cnblogs.com/yicoder/p/fileinputbigdata.html