标签:
EventScheduler:将系统中的可用资源均匀地分配给需要资源的topology,其实也不是绝对均匀,后续会详细说明DefaultScheduler:和EvenetScheduler差不多,只不过会先将其它topology不需要的资源重新收集起来,再进行EventSchedulerIsolationScheduler:用户可定义这个topology的机器资源,storm分配的时候会优先分配这些topology,以保证分配给该topology的机器只为这一个topology服务needsSchedualerTopologies方法获得需要进行任务分配的topologiesgetAvailableSlots方法获得当前集群可用的资源,以<node,port>集合的形式返回,赋值给available-slots<start-t ask-id,end-task-id>集合存入all-executors,根据topology计算executors信息,采用compute-executors算法,稍后会讲解get-alive-assigned-node+port->executors方法获得该topology已经获得的资源,返回<node+port,executor>集合的形式存入alive-assigned,为什么要计算当前topology的已分配资源情况而不是计算集群中所有已分配资源?,猜测可能是进行任务rebalance的时候会有用吧。slot-can-reassign对alive-assigned中的slots信息进行判断,选出其中能被重新分配的slot存入变量can-reassignedavailable-slots和can-reassigned两部分组成total-slots--to-use:min(topology的NumWorker数,available-slots+can-reassigned)total-slots--to-use>当前已分配的slots数目,则调用bad-slots方法计算可被释放的slotfreeSlots方法释放计算出来的bad-slotschedule-topologies-evenly进行分配主要流程梳理:获得当前集群空闲资源->计算当前topology的executor信息(分配时会用得上)->计算可重新分配和可释放的资源->分配
EventScheduler调度算法与Default相比少了一个计算可重新分配资源的环节,直接利用Supervisor中空闲的slot进行分配,在此不再细讲。
这两种调度机制在一般情况下调度结果基本保持一致,所以一起来看:
集群初始状态
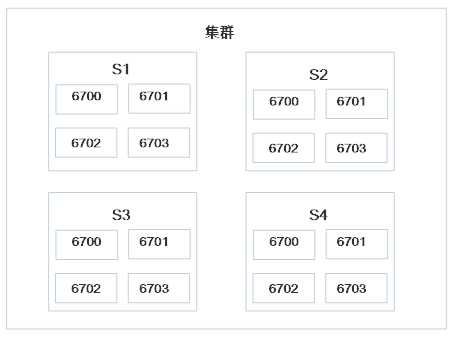
接下来我们提交3个topology
|
Topology |
Worker数 |
Executer数 |
Task数 |
|
T-1 |
3 |
8 |
16 |
|
T-2 |
5 |
10 |
10 |
|
T-3 |
3 |
5 |
10 |
注:格式为[start-task-id end-task-id],共8个worker,第一个包含2个task,start-task-id为1,end-task-id为2,所以记为[1 2],后面依次类推...compute-executors算法会在下一篇博客中详解分配后集群状态为:
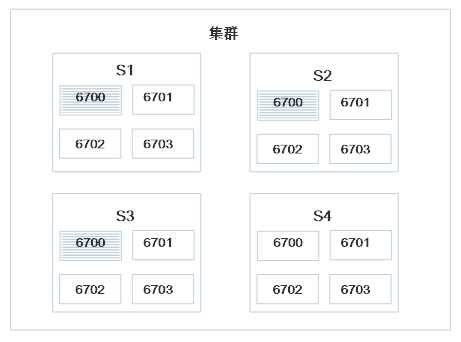
分配后集群状态为:
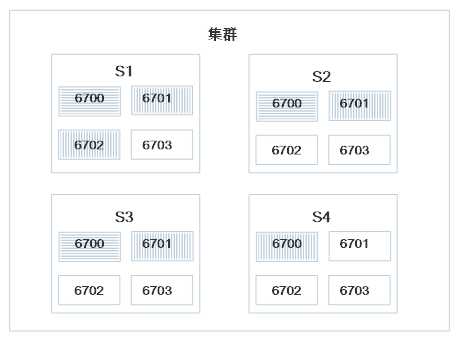
分配后集群状态为:
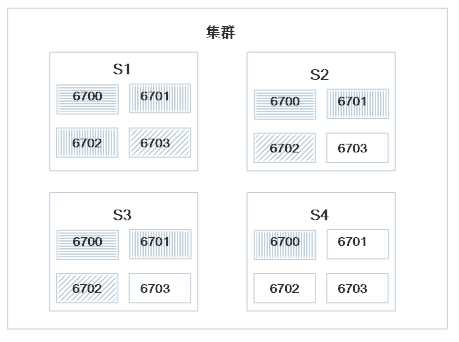
如图,此任务调度方式也不是绝对均匀的,s1已经满负荷运转,而s4才刚使用一个slots。
comput-executors、sort-slots、slots-can-reassign、bad-slots、sort-slots等会在下篇博客中专门探讨标签:
原文地址:http://www.cnblogs.com/Chuck-wu/p/4948529.html