标签:style blog http color 使用 os
转载请注明出处:电子科技大学EClab——落叶花开http://www.cnblogs.com/nlp-yekai/p/3848528.html
SVD,即奇异值分解,在自然语言处理中,用来做潜在语义分析即LSI,或者LSA。最早见文章
SVD的有关资料,从很多大牛的博客中整理了一下,然后自己写了个python版本,放上来,跟大家分享~
关于SVD的讲解,参考博客
本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gmail.com
python的拓展包numpy,scipy都能求解SVD,基于numpy写了一个文档做svd的程序。首先将每篇文档向量化,然后对向量化后的文档集合做SVD,取计算后的矩阵U,进行分析。先上代码:
1 #coding=utf-8 2 import re 3 import math 4 import numpy as np 5 import matplotlib.pylab as plt 6 7 def f_file_open(trace_string): 8 """open the document_set, save in the list called txt""" 9 f=open(trace_string,‘r‘) 10 txt=f.readlines() 11 f.close() 12 return txt 13 14 def f_vector_found(txt): 15 """calculate all of the word in the document set---构造词空间""" 16 word_list=[] 17 for line in txt: 18 line_clean=line.split() 19 for word in line_clean: 20 if word not in word_list: 21 word_list.append(word) 22 else: 23 pass 24 return word_list 25 26 def f_document_vector(document,word_list): 27 """transform the document to vector---文档向量化""" 28 vector=[] 29 document_clean=document.split() 30 for word in word_list: 31 a=document_clean.count(word) 32 vector.append(a) 33 return vector 34 35 def f_svd_calculate(document_array): 36 """calculate the svd and return the three matrics""" 37 U,S,V=np.linalg.svd(document_array) 38 return (U,S,V) 39 40 def f_process_matric_U(matric_U,Save_N_Singular_value): 41 """according to the matric U, choose the words as the feature in each document,根据前N个奇异值对U进行切分,选择前N列""" 42 document_matric_U=[] 43 for line in matric_U: 44 line_new=line[:Save_N_Singular_value] 45 document_matric_U.append(line_new) 46 return document_matric_U 47 48 def f_process_matric_S(matric_S,Save_information_value): 49 """choose the items with large singular value,根据保留信息需求选择奇异值个数""" 50 matricS_new=[] 51 S_self=0 52 N_count=0 53 Threshold=sum(matric_S)*float(Save_information_value) 54 for value in matric_S: 55 if S_self<=Threshold: 56 matricS_new.append(value) 57 S_self+=value 58 N_count+=1 59 else: 60 break 61 print ("the %d largest singular values keep the %s information " %(N_count,Save_information_value)) 62 return (N_count,matricS_new) 63 64 def f_process_matric_V(matric_V,Save_N_Singular_value): 65 """according to the matric V, choose the words as the feature in each document,根据前N个奇异值对U进行切分,选择前N行""" 66 document_matric_V=matric_V[:Save_N_Singular_value] 67 return document_matric_V 68 69 def f_combine_U_S_V(matric_u,matric_s,matirc_v): 70 """calculate the new document对奇异值筛选后重新计算文档矩阵""" 71 72 new_document_matric=np.dot(np.dot(matric_u,np.diag(matric_s)),matirc_v) 73 return new_document_matric 74 75 def f_matric_to_document(document_matric,word_list_self): 76 """transform the matric to document,将矩阵转换为文档""" 77 new_document=[] 78 for line in document_matric: 79 count=0 80 for word in line: 81 if float(word)>=0.9: #转换后文档中词选择的阈值 82 new_document.append(word_list_self[count]+" ") 83 else: 84 pass 85 count+=1 86 new_document.append("\n") 87 return new_document 88 89 90 def f_save_file(trace,document): 91 f=open(trace,‘a‘) 92 for line in document: 93 for word in line: 94 f.write(word) 95 96 trace_open="/home/alber/experiment/test.txt" 97 trace_save="/home/alber/experiment/20140715/svd_result1.txt" 98 txt=f_file_open(trace_open) 99 word_vector=f_vector_found(txt) 100 print (len(word_vector)) 101 102 document=[] 103 Num_line=0 104 for line in txt: #transform the document set to matric 105 Num_line=Num_line+1 106 document_vector=f_document_vector(line,word_vector) 107 document.append(document_vector) 108 print (len(document)) 109 U,S,V=f_svd_calculate(document) 110 print (sum(S)) 111 N_count,document_matric_S=f_process_matric_S(S,0.9) 112 document_matric_U=f_process_matric_U(U,N_count) 113 document_matric_V=f_process_matric_V(V,N_count) 114 print (len(document_matric_U[1])) 115 print (len(document_matric_V)) 116 new_document_matric=f_combine_U_S_V(document_matric_U,document_matric_S,document_matric_V) 117 print (sorted(new_document_matric[1],reverse=True)) 118 new_document=f_matric_to_document(new_document_matric,word_vector) 119 f_save_file(trace_save,new_document) 120 print ("the new document has been saved in %s"%trace_save)
第一篇文档对应的向量的结果如下图(未列完,已排序):
[1.0557039715196566, 1.0302828340480468, 1.0177955652284856, 1.0059864028992798, 0.99050787479103541, 0.93109816291875147, 0.70360233131357808, 0.22614603502510683, 0.10577134907675778, 0.098346889985350489, 0.091221506093784849, 0.085227549911874326, 0.052355994530275715, 0.049805639460153352, 0.046430974364203001, 0.046430974364203001, 0.045655634442695908, 0.043471974743277547, 0.041953839699628029, 0.041483792741663243, 0.039635143169293147, 0.03681955156197822, 0.034893319065413916, 0.0331697465114036, 0.029874818442883051, 0.029874818442883051, 0.028506042937487715, 0.028506042937487715, 0.027724455461901349, 0.026160357130229708, 0.023821284531034687, 0.023821284531034687, 0.017212073571417009, 0.016793815602261938, 0.016793815602261938, 0.016726955476865021, 0.015012207148054771, 0.013657280765244915。。。。。
基于这样一种结果,要对分解后的矩阵进行分析,如上图,值越大,表明该位置的词对该文档贡献越大,而值越小则该词无意义,因而,下一步就是设定阈值,取每一篇文档的特征词,至于阈值的设定,有很多种方法,可以对所有值进行排序,取拐点。如图(不是上面的结果做出来的图):
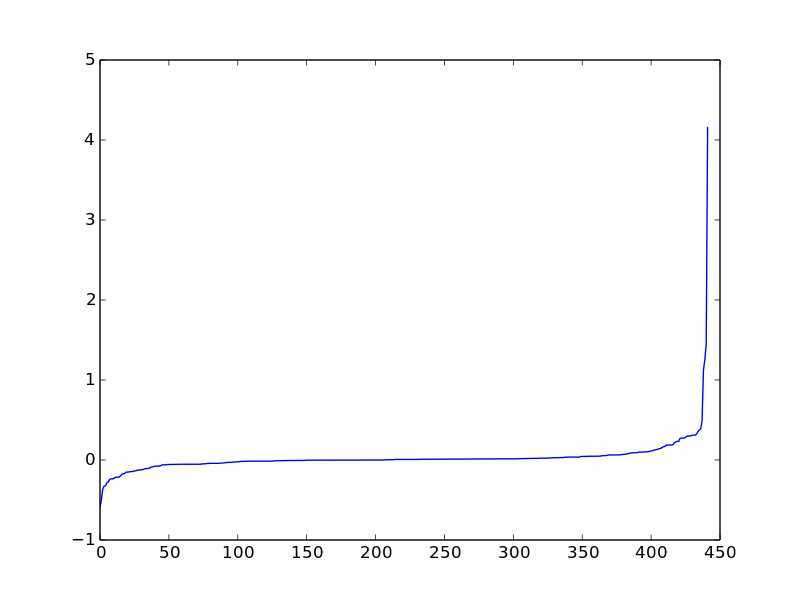
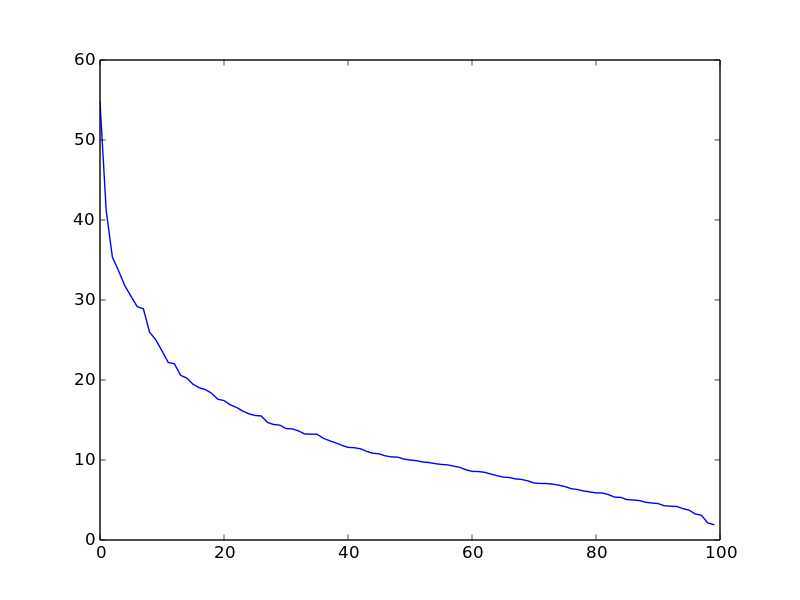
显然,只有拐点以后的值对文档的贡献较高,而拐点以后的值变为0,这样,一个文档--词矩阵就通过SVD分解而降低了维度。
这个过程中,有两个认为设定的参数,一个是奇异值的选择,如上图(右):奇异值下降较快,而其中前N个奇异值已经能够代替整个矩阵大部分的的信息。在我的程序中,通过设定需要保留的信息比率(保留90%或者95%或者其他等等)来控制奇异值个数。
另一个需要设定的就是在对上图(左),对于重新构造的矩阵,要用来代替原来的文档矩阵,需要对词进行选择,上面已经说过的,取拐点值是一种。
词--文档矩阵的SVD分解基本上就是这些内容。欢迎纠错和吐槽。
用Python做SVD文档聚类---奇异值分解----文档相似性----LSI(潜在语义分析),布布扣,bubuko.com
用Python做SVD文档聚类---奇异值分解----文档相似性----LSI(潜在语义分析)
标签:style blog http color 使用 os
原文地址:http://www.cnblogs.com/nlp-yekai/p/3848528.html